01. 이제는 마주해야 할 시간 : 영속성 컨텍스트
00. 들어가기 전에(가장 중요합니다!)
📌 우리는 입문주차에 Spring Data JPA라는 라이브러리를 사용했습니다. JPA를 랩핑해서 사용하기 편하게 만들어주는 라이브러리 라고 설명을 드렸었죠? 우리가 Spring Data JPA를 사용했기 때문에 JPA만 사용하던 시절의 코드는 아마 지금 처음 보시게 될 거에요. 상황에 따라 다르지만, 숙련주차를 공부하는 주차 빼고는, 실제 프로젝트에서는 당분간 Spring Data JPA를 사용 하시게 될 것 같습니다. 다만 중요한 것은 지금 나오는 코드들이 Spring Data JPA가 도와주지 않으면 우리가 작성해야하는 원래 JPA 코드의 모습이라 ****인지**** 하는 것 입니다.”어 왜 이런 코드가 나오지? 내가 알고 있어야 했나? 따로 공부해야 할까?” → ❎
”아 Spring Data JPA가 도와주지 않았던 시절의 JPA는 이렇게 생겼구나!” → 🅾️
- 참고 : 우리가 Spring Data JPA로 해오던 방식
// Entity를 생성! Member minsook = new Member(); member.setId("abcd1234"); member.setUsername("민숙"); // 이렇게 간단하게 해오셨던것 기억나시죠? 아래의 내용은 똑같은 과정입니다! memberRepository.save(minsook); memberRepository.find();
💥JPA만 사용시절 ~
- 우리가 Spring Data JPA를 사용하지 않았다면 우리가 Spring Data JPA를 사용하지 않았다면.. (1)
// Entity를 생성! Member minsook = new Member(); member.setId("abcd1234"); member.setUsername("민숙");
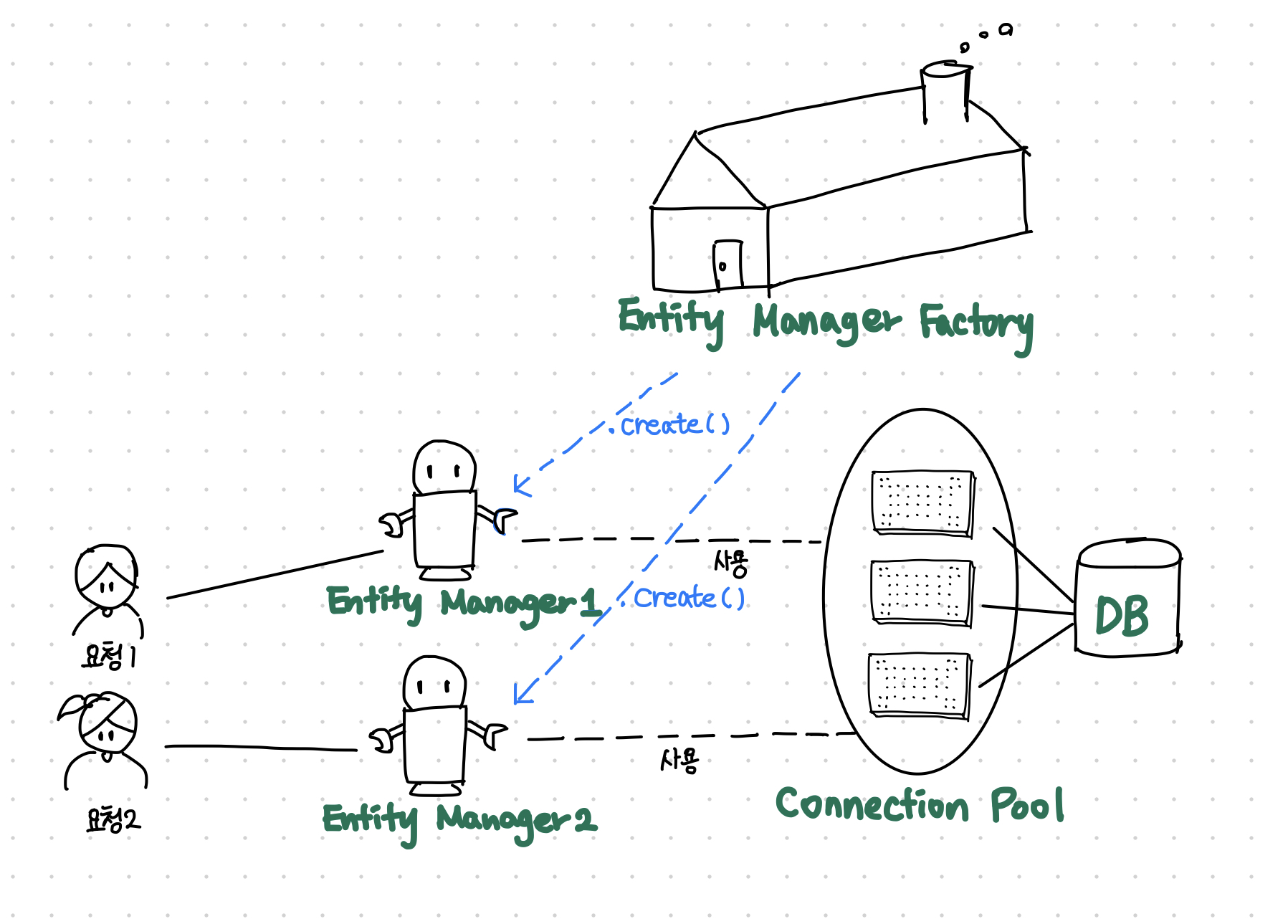
🤔 EntityManager가 Entity를 관리해준다는 것은 이름에서 짐작이 가능한데, 왜 굳이 저걸 EntityManagerFactory에서 또 생성하게 만들게끔 구현하나요? 👉 (나중에 알아도 될 이야기, 편하게 들어주세요) 프로그램 내부에 **“스레드”**라는 일꾼이 있습니다. 최근의 프로그램들은 성능을 위해 여러 스레드들이 일을 같이하게 되어 있는데, 하나의 큰 일을 동시에 처리하려다 보면 동시성 문제가 생길 수 있습니다. 그런 일을 방지하기 위해 특정 리소스나 정보는 공유하지 못하게 하는등의 처리가 필요합니다. 엔티티매니저에는 공유하면 안되는 특정 리소스나 정보가 있고, 여러 스레드가 하나의 엔티티 매니저를 이용 할 수 없도록 처리해야 합니다. 그래서 엔티티 매니저 팩토리에서 필요 할 때 마다 여러개의 엔티티매니저를 생성하는 구조로 설계한 것 입니다.// EntityManager를 생성해줄 EntityManagerFactory를 만들어야합니다. EntityManagerFactory emf = Persistence.createEntityManagerFactory("jpa심화주차");
❤이해가 어려우시면, 모종의 이유로 여러개의 엔티티 매니저가 필요하고, 매번 모든과정을 다시하기에는 비용이 많이 들어
EMF (엔티티 매니저 팩토리)는 말 그대로 EM(엔티티 매니저)를 만드는 공장인데 생성비용이 크다.
따라서 애플리케이션 전체에서 공유하도록 설계되어 있다.
반면 공장에서 생성되는 엔티티 매니저는 비용은 거의 없기 때문에 여러개 생성하는 일의 비용을 줄였다고 생각하면 좋습니다.❤EMF 는 여러 스레드가 동시에 접근해도 안전하지만,
EM 은 여러 스레드가 접근하면 동시성 문제로 인해서 공유하면 안된다.
</aside>
**우리가 Spring Data JPA를 사용하지 않았다면.. (2)**
```java
// Entity를 관리해줄 EntityManager를 EntityManagerFactory에서 생성!
EntityManager em = emf.createEntityManager();
```
**우리가 Spring Data JPA를 사용하지 않았다면.. (3) - 저장, 조회 예시**
```java
// 엔티티를 영속화(저장)
em.persist(minsook);
// 엔티티를 찾기
em.find(Member.class, 100L);
```- 지금까지의 요약
출처 자바 ORM 표준 JPA - [https://product.kyobobook.co.kr/detail/S000000935744](https://product.kyobobook.co.kr/detail/S000000935744)영속성 컨텍스트란?
영속성 컨텍스트란 엔티티를 영구 저장 하는 환경 이라는 뜻 입니다.
어플리케이션(🤔 지금은 여러분의 자바 코드 그 자체라고 생각하시면 좋을 것 같습니다)이 데이터베이스에서 꺼내온 데이터 객체를 보관하는 역할을 합니다.
영속성 컨텍스트는 엔티티 매니저를 통해 엔티티를 조회하거나 저장할때 엔티티를 보관하고 관리합니다.
📌 자바의 엔티티 객체를 엔티티 매니저마다 가지고 있는 영속성 컨텍스트라는 공간에다 넣고 빼고 하면서 사용하는거죠, “영속화 한다” 라는 말을 “엔티티 매니저가 자기의 영속성 컨텍스트에 넣어준다”로 이해하는 것 처럼 말이죠속성 컨텍스트의 특징
- 영속성 컨텍스트와 식별자 값
영속성 컨텍스트는 엔티티를 식별자 값으로 구분하기 떄문에
반드시 영속상태는 식별자 값이 있어야한다. 없다면 예외가 발생한다.
- 영속성 컨텍스트와 DB 저장
JPA는 보통 트랜잭션을 커밋하는 순간 영속성 컨텍스트에 새로 저장된 엔티티를 DB에 반영하는데
이것을 flush 라고 한다
영속성 컨텍스트가 엔티티를 관리할 떄 장점
- 1차 캐시
- 동일성 보장
- 트랜잭션을 지원하는 쓰기 지연
- 변경 감지
- 지연 로딩
- JPA 엔티티의 상태
-
비영속(New) : 영속성 컨택스트와 관계가 없는 새로운 상태입니다.
해당 객체의 데이터가 변경되거나 말거나 실제 DB의 데이터와는 관련없고, 그냥 Java 객체인 상태죠!// 엔티티를 생성 Member minsook = new Member(); member.setId("minsook"); member.setUsername("민숙"); -
영속(Managed) : 엔티티 매니저를 통해 엔티티가 영속성 컨텍스트에 저장되어 관리되고 있는 상태입니다.
이와 같은 경우 데이터의 생성, 변경등을 JPA가 추적하면서 필요하면 DB에 반영합니다.// 엔티티 매니저를 통해 영속성 컨텍스트에 엔티티를 저장 em.persist(minsook); -
준영속(Detached) : 영속성 컨택스트에서 관리되다가 분리된 상태입니다.
// 엔티티를 영속성 컨택스트에서 분리 em.detach(minsook); // 영속성 컨텍스트를 비우기 em.clear(); // 영속성 컨택스트를 종료 em.close(); -
삭제(Removed) : 영속성 컨택스트에서 삭제된 상태
em.remove(minsook)
-

출처 자바 ORM 표준 JPA - [https://product.kyobobook.co.kr/detail/S000000935744](https://product.kyobobook.co.kr/detail/S000000935744)영속성 컨텍스트는 어떻게, 왜 이렇게 설계되어있을까요? 자세한설명 (1)
#🐱🏍영속성 컨텍스트 1차 캐쉬 및 쓰기지연 SQL 저장소 등 flush() 원리 요약 !!
JPA) 변경 감지
🐱🏍Entity Manager의 영속 컨텍스트는
🐱💻1차 캐쉬 +🚽🧻 쓰기 지연 SQL저장소로 구성 되어 데이터의 변경을 감지하고
엔티티 매니저를 통해 엔티티가 영속성 컨텍스트에 저장되어 관리하며
이와 같은 경우 데이터의 생성, 변경 등을 JPA가 추적하면서 필요하면 DB에 반영합니다.
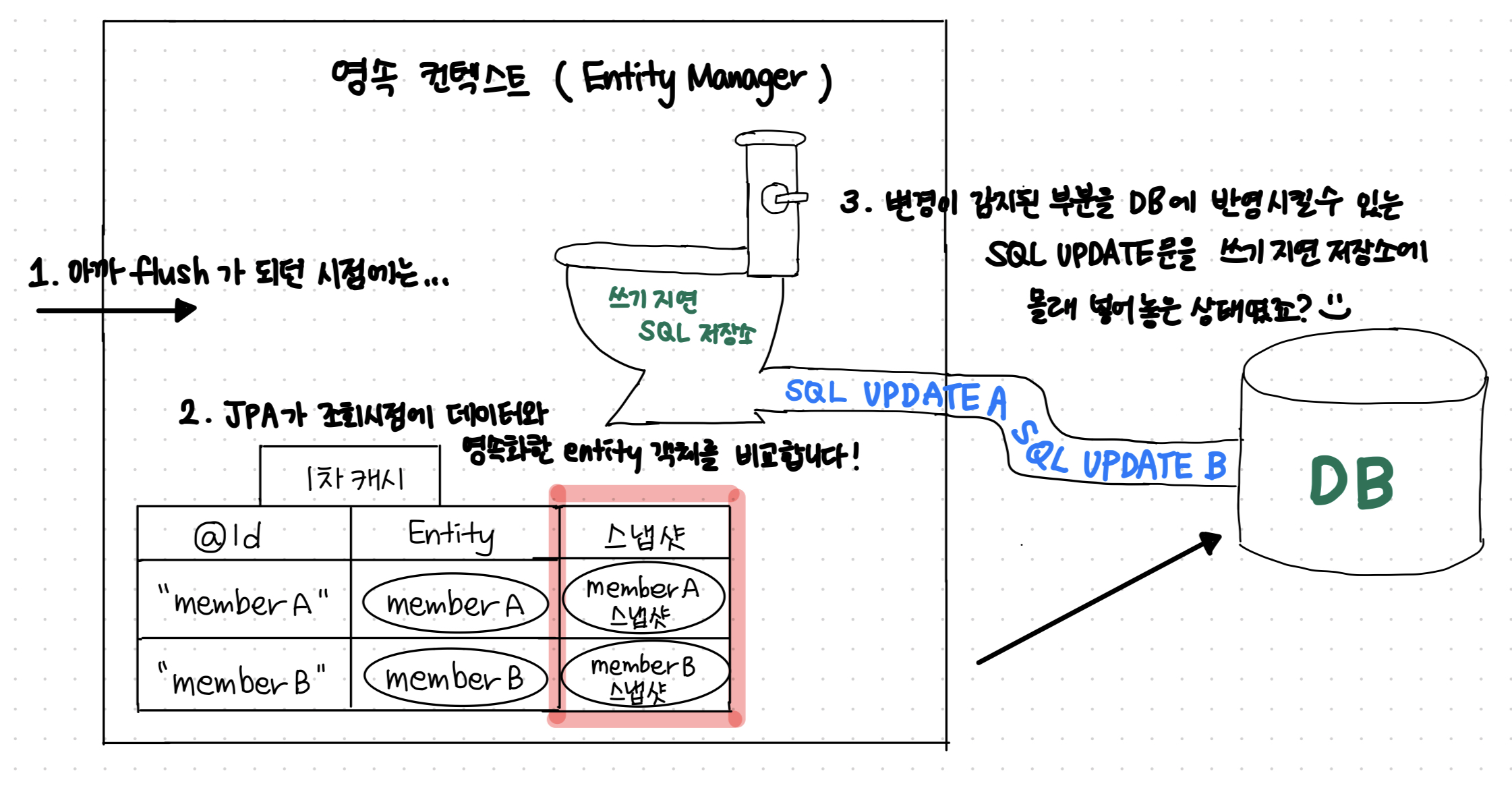
JPA는 영속성 컨텍스트에 엔티티를 보관할 때,
최초 상태를 복사해서 저장해 두는데 이것을 스냅샷 이라고 한다.
그리고 Flush 되는 시점에 스냅샷과 엔티티를 비교해서 변경된 엔티티를 찾는다.
순서
1) Transaction Commit 시 EM 내부에서 먼저 flush가 호출 된다.
2) 엔티티와 스냅샷을 비교해서 변경된 엔티티를 찾는다.
3) 변경된 엔티티가 있으면 쓰기 지연 저장소에 SQL을 보낸다.
4) 쓰기지연 저장소의 SQL을 DB로 전달한다.(등록, 수정, 삭제 Query)
5) flush가 완료된 이후 DB Transaction Commit을 한다.
플러시가 동작할 수 있는 이유는 데이터베이스 트랜잭션(작업 단위)이라는 개념이 있기 때문이다.
트랜잭션이 시작되고 해당 트랜잭션이 commit 되는 시점 직전에만 동기화 (변경 내용을 날림) 해주면 되기 때문에, 그 사이에서 플러시 매커니즘의 동작이 가능한 것이다.
변경 감지 는 영속성 컨텍스트가 관리하는 영속 상태의 엔티티만 적용된다.
그외 준영속, 비영속은 영속성 컨텍스트의 관리를 받지 못하는 것은 변경해도 반영되지 않는다.
만약에 필드가 많거나 저장되는 내용이 너무 크면 수정된 데이터만 사용해서
동적으로 SQL을 생성하는 전략을 사용하자
@DynamicUpdate
참고로 데이터를 저장할 때 데이터가 존재하는 (Not null field) 필드만
SQL을 생성하는 @DynamicInsert 도 있다.
- 엔티티삭제 삭제시 대상 엔티티를 조회 해야한다
삭제 대상 엔티티를 em.remove() 에 넘겨주면 된다. 물론 즉시 삭제가 아니라 엔티티 등록과 비슷하게 쓰기지연 저장소에 등록하고 커밋해서 플러시를 호출하면 실제 DB에 쿼리를 전달한다. remove 호출 순간 영속성컨텍스트에서 제거된다.
JPA ) 🛁플러시 (Flush)
영속성 컨텍스트의 변경 내용을 DB 에 반영하는 것을 말한다.
Transaction commit 이 일어날 때 flush가 동작하는데, 이때 쓰기 지연 저장소에 쌓아 놨던 INSERT, UPDATE, DELETE SQL들이 DB에 날라간다.
주의! 영속성 컨텍스트를 비우는 것이 아니다.
영속성 컨텍스트의 변경 사항들과 DB의 상태를 맞추는 작업이다.
즉 플러시는 영속성 컨텍스트의 변경 내용을 DB에 동기화한다.
영속성 컨텍스트를 플러시하는 방법
1. em.flush() 을 통한 직접 호출
1. // 영속 상태 (Persistence Context 에 의해 Entity 가 관리되는 상태)
Member member = new Member(200L, "A");
entityManager.persist(member);
entityManager.flush(); // 강제 호출 (쿼리가 DB 에 반영됨)
System.out.println("DB INSERT Query 가 즉시 나감. -- flush() 호출 후 -- Transaction commit 됨.");
tx.commit(); // DB에 insert query 가 날라가는 시점 (Transaction commit)Q. 플러시가 일어나면 1차 캐시가 모두 지워질까?
NO! 그대로 남아있다.
쓰기 지연 SQL 저장소에 있는 Query들만 DB에 전송까지만 되는 과정일뿐이다.
1차캐쉬는 Transaction commit 완료 된 시점에 같이 소멸된다.
2. 트랜잭션 커밋 시 플러시 자동 호출
3. JPQL 쿼리 실행 시 플러시 자동 호출
em.persist(memberA);
em.persist(memberB);
em.persist(memberC);
// 중간에 JPQL 실행
query = entityManager.createQuery("select m from Member m", Member.class);
List<Member> members = query.getResultList();Q. memberA, B, C 를 영속성 컨텍스트에 저장한 상태에서 바로 조회하면 조회가 될까?
조회가 되지 않는다.
DB 에 Query로도 날라가야 반영이 될텐데 INSERT Query 자체가 날라가지 않은 상태이다. 이런 상태에서 JPQL로 DB에서 가져오는 SELECT Query 요청을 한 것이므로 당연히 조회되지 않는다.
JPQL은 SQL로 번역이 돼서 실행되는 것이다.
이 때문에 JPA의 기본 모드는 JPQL 쿼리 실행 시 flush()를 자동으로 날린다.
즉, JPQL 쿼리 실행 시 플러시 자동 호출로 인해 위의 코드는 조회가 가능하다.
플러시 모드 옵션
em.setFlushMode(FlushModeType.COMMIT);
FlushModeType.AUTO
기본 설정 값
Transaction 을 commit 하거나 Query를 실행할 때 flush()를 먼저 수행한다.
FlushModeType.COMMIT
Transaction commit 할때만 flush()를 먼저 수행한다.
Query를 실행할 때는 flush()를 먼저 수행하지 않는다.
이점: persist 한 것과 전혀 다른 테이블을 조회하는 경우
02. 엔티티 매핑 심화
🙂 심화라는 말에 너무 겁먹을 필요 없습니다! 이번 파트에서 다룰 내용은, 지난 입문주차에 우리가 다뤘던 내용에 대한 조금 더 디테일한 설명과 조금 더 디테일한 설정들 입니다! 아직 익숙하지 않으신분들은 너무 당연한 부분이니, 지난주 내용과 교차하고 대조해보면서 보시면 좋을 것 같습니다.01. 기본 엔티티 매핑 관련
@Entity
@Table (name="USER")
public class Member {
@Id
@Column (name = "user_id")
private String id;
private String username;
private Integer age;
@Enumerated (EnumType. STRING)
private RoleType userRole;
// @Enumerated (EnumType. ORDINAL)
// private RoleType userRole;
@Temporal (TemporalType. TIMESTAMP)
private Date createdDate;
@Temporal (TemporalType. TIMESTAMP)
private Date modifiedDate;
}- 기본 엔티티 관련 어노테이션 조금 더 자세히 살펴보기 “@Entity” 관련!
-
**기본 생성자**는 필수입니다.(생성자가 하나도 없으면 자바가 만들어주겠지만 그렇지 않다면…🤔) -
final 클래스, enum, interface 등에는 사용 할 수 없어요.
-
저장할 필드라면 final을 사용하시면 안됩니다.
“@Table”관련!
-
엔티티와 매핑할 테이블의 이름입니다. 생략하는경우 어떻게되는지 찾아보시면 좋을 것 같아요!
“@Column”관련!
-
객체 필드를 테이블 컬럼에 매핑하는데 사용합니다.
-
생략이 가능합니다!
-
속성들은 자주 쓸 일이 없고, 특정 속성은 무시무시한 effect가 있으니(
검색해보세요) 이름을 지정 할 때 아니고는 보통 생략하기도 합니다.“@Enumerated”관련!
-
Java Enum을 테이블에서 사용한다고 생각하면 좋을 것 같습니다.
-
속성으로는 Ordinal, String이 있는데, String인경우 해당 문자열 그대로 저장해서 비용은 많이 들지만, 나중에 Enum이 변경되어도 위험할일이 없기 때문에 일반적으로는 String을 사용합니다.
-
02. 연관관계 관련 심화
단방향 연관관계
🙂 지난주에 매운맛을 보고오셔서 단방향은 조금 수월하실 것 같습니다! 일단 우리가 지난주 사용했었던 어노테이션부터 볼까요?- 단방향 연관관계
@Entity @Getter @Setter public class Member { @Id @Column(name = "member_id") private String id; private String username; @ManyToOne @JoinColumn(name="team_id") private Team team; public void setTeam(Team team) { this.team = team; } } @Entity @Getter @Setter public class Team { @Id @Column (name = "TEAM_ID") private String id; private String name; }@ManyToOne: 이름 그대로 다대일(N:1) 관계라는 매핑 정보였습니다. “한명의 유저가 여러개의 주문” 기억나시죠? 주요 속성으로는 optional, fetch, cascade가 있습니다. optional은 말 그대로 false로 설정하면 항상 연관된 엔티티가 있어야 생성할 수 있다는 뜻 입니다. fetch와 cascade는 뒤에 조금 더 설명하겠습니다@JoinColumn(name="food_id"): 외래 키를 매핑할 때 사용했습니다. (실제 데이터베이스에는 객체필드에는 해당 객체 테이블의 외래키가 들어간다고 말씀드렸었죠?) 기본적으로 @Column이 가지고 있는 필드 매핑관련 옵션 설정들과, 외래키 관련 몇가지 옵션이 추가되어있는 옵션입니다.
양방향 연관관계
🙃 다시 봐도 조금 매울까요..? 자세한 내용을 설명드리고 싶었지만, 영속성 컨텍스트와 같은 개념들을 이해하지 못한다면 설명하기 어려운내용이 있어서 그랬습니다🥲양방향 연관관계로 전환되는 부분을 자세히 살펴보면 좋을 것 같습니다.- 양방향 연관관계
@Getter @Entity @NoArgsConstructor public class Member { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) private Long id; @Column(nullable = false) private String memberName; @OneToMany(mappedBy = "member", fetch = FetchType.EAGER) private List<Orders> orders = new ArrayList<>(); public Member(String memberName) { this.memberName = memberName; } }@Getter @Entity @NoArgsConstructor public class Orders { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) private Long id; @ManyToOne @JoinColumn(name = "food_id") private Food food; @ManyToOne @JoinColumn(name = "member_id") private Member member; public Orders(Food food, Member member) { this.food = food; this.member = member; } }
Member와 Team vs Order의 Member차이를 살펴볼까요?@Getter @Entity @NoArgsConstructor public class Food { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) private Long id; @Column(nullable = false) private String foodName; @Column(nullable = false) private int price; @OneToMany(mappedBy = "food",fetch = FetchType.EAGER) private List<Orders> orders = new ArrayList<>(); public Food(String foodName, int price) { this.foodName = foodName; this.price = price; } }// Member의 Team쪽 @ManyToOne @JoinColumn(name="team_id") private Team team;// Order의 Member쪽 @ManyToOne @JoinColumn(name = "member_id") private Member member;-
차이가 보이시나요?
🙃 네 Many쪽은 없습니다.. -
그렇다면 실제 DataBase에는 차이가 어떻게 반영됐었죠?
<aside> 🙃 네 없습니다, 기본적으로 DB의 외래키는 양방향에서 조회는 가능합니다! 데이터베이스 상에는 변경될게 없다는거죠! </aside>그렇다면 Many의 반대쪽을 보죠!
@OneToMany(mappedBy = <"member", fetch = FetchType.EAGER) private List<Orders> orders = new ArrayList<>();단방향에는 없었던 OneToMany라는 어노테이션이 있었습니다.
🙃 **@OneToMany는 양방향을 표기해주기 위해 해주는게 딱 봐도 느낌이 오는데 mappedBy는 뭔가요?**객체에는 사실 양방향 연관관계라는 것이 없습니다. 서로 다른 단방향으로 조회하는 로직 2개를 잘 묶어서 양방향인 것처럼 보이게 한 것 뿐이죠! 더 정확히는 멤버객체에 주문객체의 주소값을, 주문객체에는 멤버객체의 주소값을 가지고 있는 것 입니다!
-
반면 데이터베이스는 어떨까요?
**Member** | | id | member_name | order | | --- | --- | --- | --- | | | | | | | | | | | **Order** | | id | food_id | member_id | | --- | --- | --- | --- | | | | | | | | | | |외래키는 연관관계가있는 두개의 테이블 중에서 하나의 테이블에만 있으면 충분합니다! 따라서. 이런 차이로 인해 두 객체 연관관계 중 하나를 정해서 테이블의 외래키를 관리해야 하는데 이것을 연관관계의 주인이라 합니다.
📌 연관관계의 주인에 의해 mappedBy 된다!연관관계의 주인만이 데이터베이스 연관관계와 매핑되고 외래 키를 관리(등록, 수정, 삭제) 하게 되어있습니다. 반면에 주인이 아닌 쪽은 읽기만 할 수 있죠. 연관관계의 주인을 정한다는 것은 사실 외래 키 관리자를 선택하는 것 입이다.
-
03. 양방향 연관관계의 주의점
-
주의점
연관관계의 주인에는 값을 입력하지 않고, 주인이 아닌 곳에만 값을 입력하기. 데이터베이스에 외래 키값이 정상적으로 저장되지 않으면 이것부터 의심해봐야 합니다.
Order order = new Order ("order", "order”); em.persist(order); Order order2 = new Order (”order2", "order2”); em.persist(order2); Member member = new Member("member", ”member”); //여기가 실수 포인트!!! member.getOrders().add(order); member.getOrders().add(order2); em.persist(member);
📌 여기는 연관관계의 주인이 아닌 member.order에만 값을 저장했기 때문입니다. 예제 코드는 연관관계의 주인인 order.member에 아무 값도 입력하지 않았죠. 따라서 memberId 외래 키의 값도 `null`이 저장됩니다. 해결 : **순수한 객체까지 고려한 양방향 연관관계** 객체 관점에서 양쪽 방향에 모두 값을 입력해주는 것이 가장 안전합니다. 양쪽 방향 모두 값을 입력하지 않으면 `JPA`를 사용하지 않는 순수한 객체 상태에서 심각한 문제가 발생할 수 있죠. ```java order.setMember(member) member.getOrders().add(order); ``` 해결 2 : **연관관계 편의 메소드** 이걸 매번 하는건 깜빡할 여지가 너무 많겠죠? ```java private Order order; public void setMember(Member member) { this.member = member; member.getOrders().add(this); } ... } ```memberId order null order2 null 출처: 스파르타코딩 강의
인프런강의
