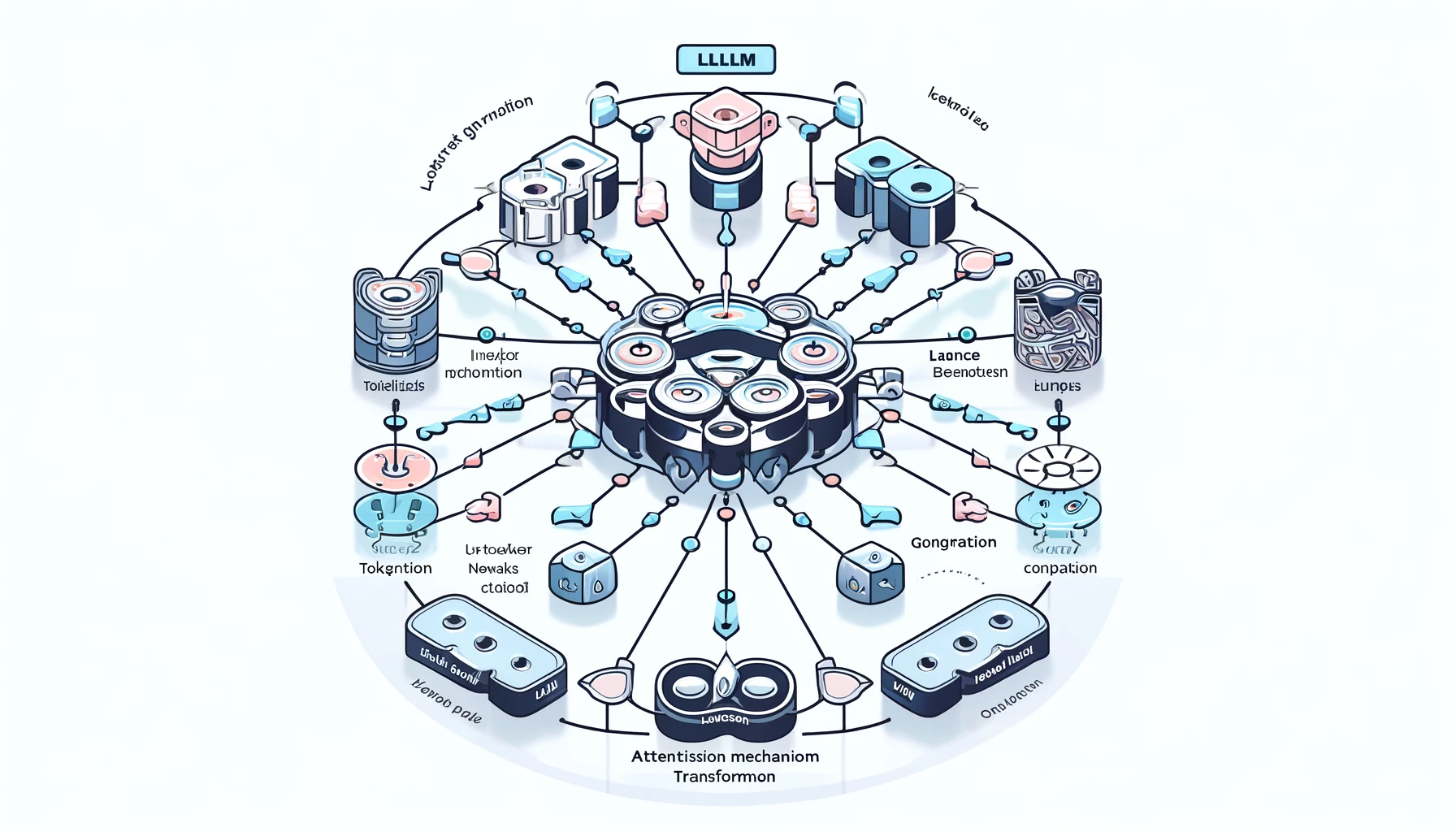
Large Language Model (LLM) 작동 원리
1. 입력 데이터 (Input Data)
사용자가 입력한 텍스트 데이터가 LLM의 첫 번째 입력으로 들어갑니다.
2. 토큰화 (Tokenization)
입력된 텍스트는 토큰화 과정을 거쳐 개별 단어 또는 문장 부호로 분리됩니다.
- 예시: "Hello, world!" → ["Hello", ",", "world", "!"]
3. 임베딩 (Embeddings)
토큰화된 단어들은 임베딩 벡터로 변환됩니다. 이 벡터들은 고차원 공간에서 단어의 의미를 나타냅니다.
- 예시: "Hello" → [0.1, 0.3, 0.5, ...]
4. 신경망 레이어 (Neural Network Layers)
임베딩 벡터는 다층 신경망을 통과하며 변환됩니다. 이 과정에서 주로 트랜스포머(Transformers) 구조가 사용됩니다.
- 트랜스포머는 자체 회귀 모델로, 입력 시퀀스의 모든 단어들 간의 관계를 한 번에 처리할 수 있습니다.
5. 어텐션 메커니즘 (Attention Mechanism)
어텐션 메커니즘은 입력 시퀀스의 각 단어가 다른 단어들과 어떻게 상호작용하는지를 평가합니다. 이는 모델이 문맥을 이해하고 중요한 부분에 집중하도록 돕습니다.
- Self-Attention: 각 단어가 다른 모든 단어와의 관계를 계산합니다.
6. 출력 생성 (Output Generation)
최종 신경망 레이어의 출력을 기반으로, 모델은 다음 단어 또는 문장을 생성합니다. 이 과정은 반복되어 원하는 길이의 출력을 생성합니다.
- 예시: 입력 "The weather is" → 출력 "nice today."
전체 흐름 요약
- 입력 데이터 → 토큰화
- 토큰 → 임베딩 벡터
- 임베딩 → 신경망 레이어 통과
- 어텐션 메커니즘 적용
- 최종 출력 생성
이 과정이 반복되며, 모델은 주어진 입력에 대해 가장 적절한 출력을 생성하게 됩니다.

나 원장이 아니다