1. 데이터 불러오기
-
원하는 데이터를 불러오기 가능하다.
-
주로 csv 파일 형태를 불러온다.
-
csv파일로 불러오면 데이터프레임 형태로 되어있기때문에 그대로 사용하면된다.
- 시리즈로 되어있는 변수를 적용할려면 DataFrame으로 변형해야함import pandas as pd csv = pd.read_csv('주소')
2. 대표적 기능
1) head()
-
위 기준으로 정보를 확인 한다.
# 위에서 기본 5개 확인 csv.head() # 지정해서 보이는 것도 가능하다. csv.head(2) #2개만 보기
2) tail()
-
아래 기준으로 정보를 확인 한다.
# 아래에서 기본 5개를 확인 csv.tail() # 지정해서 보이는 것도 가능하다. csv.tail(2) # 2개만 보기
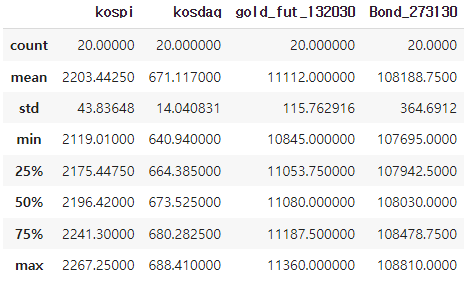
3) describe()
- 기술 통계량을 보여준다.
- 개수, 평균, 표준편차, 가장 작은 값, 가장 높은 값, (25%, 50%, 75%) 값 을 보여준다.
csv.describe() - 결과 예시)
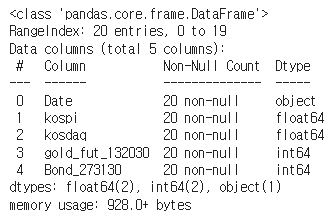
4) info()
- 데이터 타입의 종류 등 기본적인 정보들을 보여준다.
csv.info() - 결과 예시)
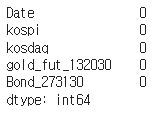
5) isna(), isnull()
-
결측치(Missing Value)를 확인할 수 있다.
-
NaN, Null 값 확인 가능
# null의 여부를 확인해 True, False 값으로 시리즈 형태로 가져옴. csv.isna() # sum()가 결합하여, 각각의 컬럼에 결측치의 갯수를 확인 할 수 있다. csv.isna().sum() -
결과 예시)
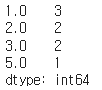
6) value_counts()
- 각각의 컬럼들의 갯수를 세어준다.
csv.value_counts() - 결과 예시)
7) axis 옵션
- axis=0일때 행을 기준으로 두는 것을 말하며, axis=1일때 열을 기준으로 두고 작업을 한다.
- 기본값은 대부분 axis = 0을 두고 있다.
8) sort_ 정렬
- Serise를 기준으로 많이 사용되지만, 데이터 프레임으로 사용이 가능하다.
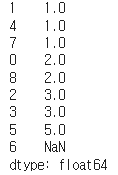
8-1) sort_values()
-
값을 기준으로 오름차순으로 정렬
-
옵션으로 ascending=False를 부여할 경우 내림차순으로 변경된다.
# 기본 사용법 obj.sort_values() # 오름 차순으로 정렬 # 내림 차순 정렬 obj.sort_values(ascending = False) -
결과 예시)
8-2) sort_index()
-
Index를 기준으로 오름차순으로 정렬한다.
-
옵션으로 ascending=False를 부여할 경우 내림차순으로 변경된다.
-
axis옵션을 부여할 경우 컬럼별로 적용이 된다.
# 기본 사용법 obj.sort_index() # 오름 차순으로 정렬 # 내림 차순으로 정렬 obj.sort_index(ascending = False)

공부해보자