

문제 설명 및 링크

접근 방법 및 해결 전략
첫 번째
from collections import deque
def solution(begin, target, words):
count = 0
if target not in words:
return 0
visited = [False] * len(words)
q = deque()
q.append(begin)
# 시작 노드는 words 리스트 안에 없으므로 visited = True는 생략한다.
while q:
v = q.popleft()
if v == target:
return count
for word in words:
if not visited[words.index(word)] and sum(1 for i in list(v) if i not in word) == 1:
visited[words.index(word)] = True
q.append(word)
count += 1
return count- 초기 count 값은 return 값을 계산하기 위해 설정했다.
if target not in words는 words 리스트에 target 값이 없으면 변환 할 수 없으므로 우선 판별해주었다.- visted 리스트는 방문 체크만 하기때문에 1차원으로 정의했다.
sum(1 for i in list(v) if i not in word를 풀어서 적어보면 다음과 같다.
count = 0
for i in list(v):
if i not in word:
count += 1예시를 들면
count = 0
for i in ["h","i","t"]:
if i not in "hot":
count += 1hit의 각 알파벳이 for문으로 돌면서 "hot"안에 있는 값인지 비교한다. 만약 "hot"안에 없는 알파벳이면 count에 1을 더한다. 이 뜻은 한번에 하나의 알파벳이 변하는 것을 찾는 코드를 말한다.
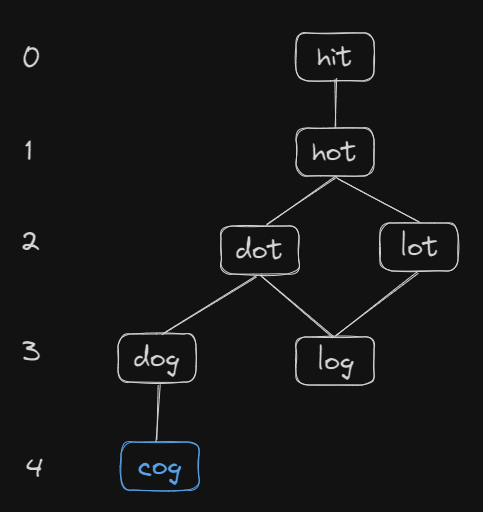
그림 1을 보면 return값으로 내놓아야하는 값은 graph의 깊이 값이다. 그러나 나는 코드에서 edge의 수를 count로 내놓았기 때문에 틀린 값이 발생했다.
두 번째
from collections import deque
def solution(begin, target, words):
if target not in words:
return 0
visited = [False] * len(words)
q = deque()
q.append((begin, 0))
# 시작 노드는 words 리스트 안에 없으므로 visited = True는 생략한다.
while q:
node, depth = q.popleft()
if node == target:
return depth
for i in range(len(words)):
if not visited[i] and sum(1 for j in list(node) if j not in words[i]) == 1:
visited[i] = True
q.append((words[i], depth+1))달라진 점은 graph의 깊이를 알기 위해서 depth를 큐 자료구조에 같이 넣어주었다. 그리고
for i in range(len(words))를 사용하여 index와 value값을 더 쉽게 나타낼 수 있게 했다.
그러나 테스트 케이스 1개를 통과하지 못했다.
그에 대한 예시는 아래와 같다.
예를 들어, begin이 "hto", target이 "lot", words가 ["dot", "dog", "log", "lot"]인 경우를 생각해보자. 이 경우, "hto"의 한 알파벳이 변해서 바뀔 수 있는 단어가 없기 때문에 0이 정답니다. 그러나 주어진 코드에서는 리스트로 비교하면 단어의 위치와 상관없이 비교하게 되므로 올바른 코드가 아니다.
마지막
from collections import deque
def solution(begin, target, words):
if target not in words:
return 0 # words 리스트에 target이 없을 때
visited = [False] * len(words)
q = deque()
q.append((begin, 0))
while q:
node, depth = q.popleft()
if node == target:
return depth
for i in range(len(words)):
if not visited[i] and sum(a!=b for a,b in zip(node,words[i])) == 1:
visited[i] = True
q.append((words[i], depth+1))
return 0 # begin값이 target에 도달하지 못했을 때sum([a!=b for a,b in zip(node,words[i])]) == 1 zip()함수를 사용하여 단어와 같은 위치의 알파벳을 비교할 수 있도록 했다. 그리고 리스트 함축을 통해 a!=b 값을 리스트에 담는다.풀어쓰면 아래와 같다.
my_list = []
for a, b in zip(node, word):
my_list.append(a!=b)예시를 들면
for a, b in zip("hit", "hot"):
my_list.append(a!=b)
# list(zip("hit", "hot")) = [('h', 'h'), ('i', 'o'), ('t', 't')]
# print(my_list) = [False, True, False]
# sum([my_list) = sum([0,1,0]) = 1그리고 마지막에 return 0값을 추가 해주었다. 왜냐하면 begin값이 target값에 도달하지 못하는 경우도 고려해야하기 때문이다.
