문제 설명
[level 2][PCCP 기출문제] 2번 / 석유 시추 - 250136
성능 요약
메모리: 13.9 MB, 시간: 50.98 ms
구분
코딩테스트 연습 > PCCP 기출문제
채점결과
정확성: 60.0
효율성: 40.0
합계: 100.0 / 100.0
제출 일자
2024년 03월 09일 03:37:55
문제 설명
[본 문제는 정확성과 효율성 테스트 각각 점수가 있는 문제입니다.]
세로길이가 n 가로길이가 m인 격자 모양의 땅 속에서 석유가 발견되었습니다. 석유는 여러 덩어리로 나누어 묻혀있습니다. 당신이 시추관을 수직으로 단 하나만 뚫을 수 있을 때, 가장 많은 석유를 뽑을 수 있는 시추관의 위치를 찾으려고 합니다. 시추관은 열 하나를 관통하는 형태여야 하며, 열과 열 사이에 시추관을 뚫을 수 없습니다.
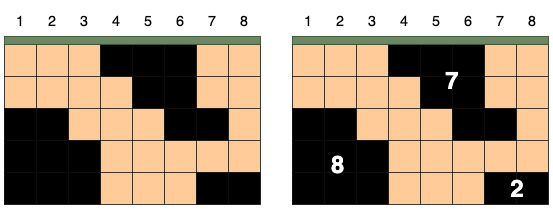
예를 들어 가로가 8, 세로가 5인 격자 모양의 땅 속에 위 그림처럼 석유가 발견되었다고 가정하겠습니다. 상, 하, 좌, 우로 연결된 석유는 하나의 덩어리이며, 석유 덩어리의 크기는 덩어리에 포함된 칸의 수입니다. 그림에서 석유 덩어리의 크기는 왼쪽부터 8, 7, 2입니다.
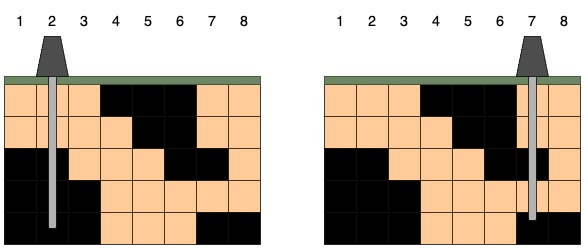
시추관은 위 그림처럼 설치한 위치 아래로 끝까지 뻗어나갑니다. 만약 시추관이 석유 덩어리의 일부를 지나면 해당 덩어리에 속한 모든 석유를 뽑을 수 있습니다. 시추관이 뽑을 수 있는 석유량은 시추관이 지나는 석유 덩어리들의 크기를 모두 합한 값입니다. 시추관을 설치한 위치에 따라 뽑을 수 있는 석유량은 다음과 같습니다.
| 시추관의 위치 | 획득한 덩어리 | 총 석유량 |
|---|---|---|
| 1 | [8] | 8 |
| 2 | [8] | 8 |
| 3 | [8] | 8 |
| 4 | [7] | 7 |
| 5 | [7] | 7 |
| 6 | [7] | 7 |
| 7 | [7, 2] | 9 |
| 8 | [2] | 2 |
오른쪽 그림처럼 7번 열에 시추관을 설치하면 크기가 7, 2인 덩어리의 석유를 얻어 뽑을 수 있는 석유량이 9로 가장 많습니다.
석유가 묻힌 땅과 석유 덩어리를 나타내는 2차원 정수 배열 land가 매개변수로 주어집니다. 이때 시추관 하나를 설치해 뽑을 수 있는 가장 많은 석유량을 return 하도록 solution 함수를 완성해 주세요.
제한사항
- 1 ≤
land의 길이 = 땅의 세로길이 =n≤ 500- 1 ≤
land[i]의 길이 = 땅의 가로길이 =m≤ 500 land[i][j]는i+1행j+1열 땅의 정보를 나타냅니다.land[i][j]는 0 또는 1입니다.land[i][j]가 0이면 빈 땅을, 1이면 석유가 있는 땅을 의미합니다.
- 1 ≤
정확성 테스트 케이스 제한사항
- 1 ≤
land의 길이 = 땅의 세로길이 =n≤ 100- 1 ≤
land[i]의 길이 = 땅의 가로길이 =m≤ 100
- 1 ≤
효율성 테스트 케이스 제한사항
- 주어진 조건 외 추가 제한사항 없습니다.
입출력 예
| land | result |
|---|---|
| [[0, 0, 0, 1, 1, 1, 0, 0], [0, 0, 0, 0, 1, 1, 0, 0], [1, 1, 0, 0, 0, 1, 1, 0], [1, 1, 1, 0, 0, 0, 0, 0], [1, 1, 1, 0, 0, 0, 1, 1]] | 9 |
| [[1, 0, 1, 0, 1, 1], [1, 0, 1, 0, 0, 0], [1, 0, 1, 0, 0, 1], [1, 0, 0, 1, 0, 0], [1, 0, 0, 1, 0, 1], [1, 0, 0, 0, 0, 0], [1, 1, 1, 1, 1, 1]] | 16 |
입출력 예 설명
입출력 예 #1
문제의 예시와 같습니다.
입출력 예 #2

시추관을 설치한 위치에 따라 뽑을 수 있는 석유는 다음과 같습니다.
| 시추관의 위치 | 획득한 덩어리 | 총 석유량 |
|---|---|---|
| 1 | [12] | 12 |
| 2 | [12] | 12 |
| 3 | [3, 12] | 15 |
| 4 | [2, 12] | 14 |
| 5 | [2, 12] | 14 |
| 6 | [2, 1, 1, 12] | 16 |
6번 열에 시추관을 설치하면 크기가 2, 1, 1, 12인 덩어리의 석유를 얻어 뽑을 수 있는 석유량이 16으로 가장 많습니다. 따라서 16을 return 해야 합니다.
제한시간 안내
- 정확성 테스트 : 10초
- 효율성 테스트 : 언어별로 작성된 정답 코드의 실행 시간의 적정 배수
출처: 프로그래머스 코딩 테스트 연습, https://school.programmers.co.kr/learn/challenges
문제 풀이
from collections import deque
def get_adjacent_node(land, x, y):
adjacent_nodes = []
for dx, dy in [(-1,0),(1,0),(0,-1),(0,1)]: # 상하좌우
nx, ny = x + dx, y + dy
if 0 <= nx and nx < len(land) and 0 <= ny and ny < len(land[0]):
# 가로 len(land), 세로 len(land[0])
adjacent_nodes.append([nx,ny])
return adjacent_nodes
def solution(land):
n = len(land) # 세로
m = len(land[0]) # 가로
total_oil = []
for j in range(m):
# 아래 for 문이 돌고 난 다음 계산된 count를 저장한다.
# 아래 for 문이 돌고 난 다음 visited를 초기화 한다.
visited = [[False] * m for _ in range(n)]
count = 0
for i in range(n):
if not visited[i][j] and land[i][j] == 1:
visited[i][j] = True
queue = deque([(i,j)])
count += 1
while queue:
x,y = queue.popleft()
adjacent_nodes = get_adjacent_node(land,x,y)
for nx, ny in adjacent_nodes:
if not visited[nx][ny] and land[nx][ny]:
visited[nx][ny] = True
queue.append([nx,ny])
count += 1
total_oil.append(count)
return max(total_oil)- 일반적인 DFS, BFS 코드를 작성하여 문제를 풀어보았다.
인접한 노드를 계산하는 함수를 만들고 그와 연결된 코드들을 visited를 확인하며 문제를 풀었다.
정확성 테스트는 통과했으나 효율성 테스트를 통과하지 못했다. - solution 함수 내에서 열방향으로 탐색하고 열을 탐색할때마다 석유의 크기를 찾기때문에 효율성 테스트에 통과못하는 것이다. 이러한 중복을 없애는 것이 중요하다. 또한 인접한 노드의 탐색할 때, 따로 함수를 뺄 필요까진 없어 보인다.
- 처음 코드를 작성했을 때, visited의 초기값을
visited = [[False] * m] * n으로 작성했었다. 그러나 이후 코드가 진행되면서 같은 열에 있는 visited 값이 모두 True로 바뀌는 현상이 발생했다. 그 이유는[False] * m리스트를 가리키는 n개의 참조를 생성하기 때문이다. 여기서 중요한 점은 모든 n개의 참조가 같은 리스트 객체를 가리킨다는 것이다. 따라서, 하나의 리스트 원소를 변경할 때, 같은 객체를 참조하는 모든 참조에 대해 변경되었다.
결과적으로 visited의 초기값은visited = [[False] * m for _ in range(n)]이처럼 작성해야 한다는 것을 배웠다.
개선방안
def bfs(land, x, y, visited, cluster_id):
n, m = len(land), len(land[0])
queue = deque([(x, y)])
visited[x][y] = cluster_id
size = 0 # 현재 덩어리의 크기
columns = set() # 현재 덩어리가 포함된 열의 집합
while queue:
cx, cy = queue.popleft()
size += 1
columns.add(cy)
for dx, dy in [(-1, 0), (1, 0), (0, -1), (0, 1)]:
nx, ny = cx + dx, cy + dy
if (
0 <= nx < n
and 0 <= ny < m
and land[nx][ny] == 1
and visited[nx][ny] == -1
):
visited[nx][ny] = cluster_id
queue.append((nx, ny))
return size, columns
def solution(land):
n, m = len(land), len(land[0])
visited = [[-1] * m for _ in range(n)] # 방문한 노드와 덩어리 ID 저장
cluster_info = {}
# 덩어리 ID를 key로, (크기, 포함된 열의 집합)을 value로 가지는 딕셔너리
cluster_id = 0
for i in range(n):
for j in range(m):
if land[i][j] == 1 and visited[i][j] == -1:
size, columns = bfs(land, i, j, visited, cluster_id)
cluster_info[cluster_id] = (size, columns)
cluster_id += 1
# 각 열별로 석유량 계산
column_oil = [0] * m
for cluster_id, (size, columns) in cluster_info.items():
for column in columns:
column_oil[column] += size
return max(column_oil)- 열의 정보를 저장하는 columns를 집합(set)으로 생성하여 중복을 없애고 답을 내는데에 이용한다.
- bfs 함수는 초기값 설정 -> 현재 노드 탐색 -> 인접 노드 탐색 순서로 진행된다. 그래서
size += 1와columns.add(cy)은 현재 노드에 대한 정보를 갱신하는 것이므로 while문 바로 아래에 작성한다. for dx, dy in [(-1, 0), (1, 0), (0, -1), (0, 1)]:은 인접한 노드를 탐색하기 위한 for문이다. 인접한 노드의 중복을 막기위해 마찬가지로 land[nx][ny], visited[nx][ny] 확인하였다.- solution 함수는 bfs에서 얻은 석유의 크기, 석유가 존재하는 열 정보(size, columns)를 얻어 가장 많이 추출할 수 있는 석유량을 계산한다.
- cluster_info는 파이썬의 딕셔너리를 활용하였다.
배운점
- visited 초기값 설정의 잘못된 방법과 객체의 참조에 대해 이해할 수 있게 되었다.
- 딕셔너리를 이용해 정보를 저장하고 중복을 없애는 아이디어를 얻을 수 있었다.
- bfs의 순서는 초기값 설정 -> 현재노드 탐색 -> 인접노드 탐색이다. 이 순서를 기억하고 해당 노드에 적용할 논리를 적용해보자.
- 문제의 흐름대로 코드를 작성하는 습관이 있는데 효율적으로 중복을 없애기 위해서는 정보를 모두 얻은 다음 문제가 원하는 답을 끼워 맞추면 된다는 것을 배웠다.
