-
Pandas에서 엑셀 및 텍스트 파일 읽기
- Python에서 R만큼의 강력한 데이터 핸들링 성능을 제공하는 모듈
- 단일 프로세스에서는 최대 효율
- 코딩 가능하고 응용 가능한 엑셀로 받아들여도 됨
-
모듈(Module) Import
-
원하는 모듈이 설치되어 있다면 import 명령을 통해 사용하겠다고 선언
import pandas as pd
-
Python 모듈에 대한 naming 규칙
MODULE.function→ import MODULE: MODULE사용하겠음md.function→ import MODULE as md: MODULE을 사용할 건데, md라는 이름으로 부르겠음function→ from MODULE import function: MODULE에 포함된 function이라는 함수만 사용하겠음
-
Pandas에서 엑셀 및 텍스트 파일 읽기
CCTV_Seoul = pd.read_csv("../data/01. Seoul_CCTV.csv", encoding="utf-8") CCTV_Seoul.head(5) CCTV_Seoul.tail(5)- 통상 CSV(Comma seperated value)는 띄어쓰기로 구분되니 그냥
read.csv명령으로 읽기만 해도 됨 "../data/01. Seoul_CCTV.csv"
: 현재 위치에서 상위폴더인 data 폴더에서 01.Seoul_CCTV.csv 파일 읽어오기..: 상위폴더.: 현재폴더- 긴 파일명을 끝까지 입력하지 말고 적당한 곳에서 TAB키 누르기
- 한글은 encoding 설정 필수
head(3)앞 부분 3개만 출력tail(3)끝에서 3개만 출력(내가 가진 데이터 숫자가 몇 개인지 파악 가능)
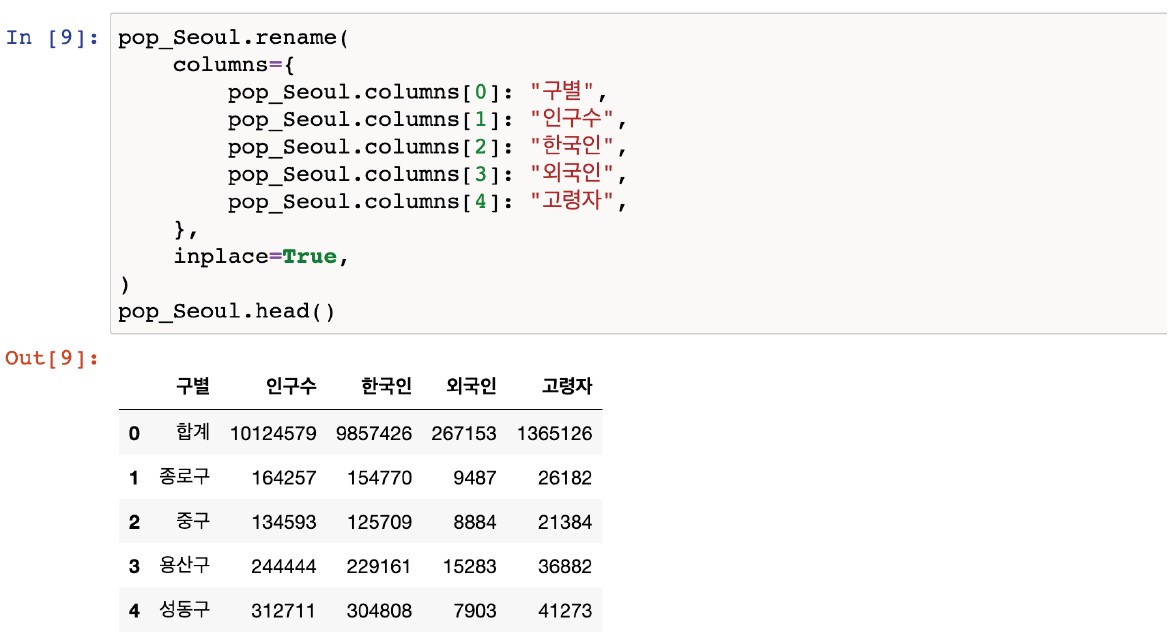
pop_Seoul = pd.read_excel("../data/01. Seoul_population.xls", header=2, usecols="B, D, G, J, N") pop_Soeul.head()header = num자료를 읽기 시작할 행 지정usecols = "B, D, G"읽어올 엑셀의 컬럼을 지정
- 통상 CSV(Comma seperated value)는 띄어쓰기로 구분되니 그냥
-
Pandas DataFrame의 구조
- column의 이름을 조회할 수 있음
In[1]: CCTV_Seoul.columns Out[1]: Index(['기관명', '소개', '2013년도 이전', '2014년', '2015년', '2016년'], dtype='object') In[2]: CCTV_seoul.columns[0] Out[2]: '기관명'- column의 이름 바꾸고 싶을 때
.rename(columns={기존 컬럼명: 바꿀 컬럼명})
inplace=True해당 실행문의 변경사항을 저장하는 값(원본데이터도 수정 )
CCTV_Seoul.rename(columns={CCTV_Seoul.columns[0]: "구별"}, implace=True) CCTV_Seoul.head()
-
-
Pandas 기초
import pandas as pd
: Pandas는 통상 pd로 import 함import numpy as np
: 수치해석적 함수가 많은 numpy는 np로 import함Series: pandas의 데이터형을 구성하는 기본
-
날짜(시간) 이용 가능
dates = pd. date_range("20230101", periods=6) dates # 날짜가 20230101부터 6일만큼 출력됨
-
DataFrame
-
pandas에서 가장 많이 사용되는 데이터형
-
index와 columns를 지정하면 됨
df = pd.DataFrame(np.random.randn(6,5), index=dates, columns=["A", "B", "C", "D"]) df
-
-
DataFrame 정보 탐색
df.info(): 데이터프레임의 기본정보 확인, 각 컬럼의 크기와 데이터형태를 확인하는 경우가 많음df.describe(): 데이터프레임의 통계적 기본 정보 확인(각 컬럼별로 개수, 평균, 표준편차, 최소값, 최대값 등 확인)df.index: 인덱스 값을 리스트 형태로 반환하여 보여줌df.columns: 컬럼 값을 리스트 형태로 반환하여 보여줌df.values: 벨류 값을 리스트 형태로 반환하여 보여줌
-
데이터 정렬
-
sort_Values: 특정 컬럼(열)을 기준으로 데이터 정렬df.sort_values(by="B", ascending=Falseascending=False옵션: 내림차순 정렬ascending=True옵션: 오름차순 정렬(생략가능)
-
- 특정 컬럼만 읽기
df['A']
-
슬라이싱
df[0:3]- [n:m] : n부터 m-1까지
- 인덱스나 컬럼의 이름으로 slice하는 경우 끝을 포함
-
loc[행,열]
df.loc[:, ["A", "B"]]- 이름으로도 사용 가능
- pandas의 보편적인 슬라이싱 옵션
-
iloc
df.iloc[3]- iloc옵션 이용해서 번호로만 접근
-
df
- df[condition] 같이 사용하는 것이 일반적
- pandas 버전에 따라 조금씩 허용되는 문법이 다름
df[df>0]0보다 작은 것은 NaN(Not a Number)처리 됨- 리스트 안 데이터 값을 가진 E 컬럼을 새로 생성
df["E"] = ["one", "two", "three", "four", "three"]` df - 특정 요소가 있는 행만 선택
df["E"].isin[["two", "four"])
-
del
-
del df["E"]: 특정컬럼 제거
-
apply()
df.apply(np.cumsum): 각 컬럼 누적합

파이팅
유익한 글이었습니다.