<강남3구 범죄현황 데이터개요 및 읽어오기>
모듈 가져오기
import numpy as np
import pandas as pd데이터 읽기
crime_raw_data = pd.read_csv(
"../data/02.crime_in_Seoul.csv", thousands=",", encoding="euc-kr"
)
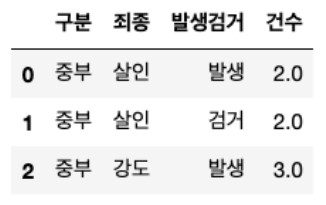
crime_raw_data.head(3) thousands="," : 데이터 안의 숫자값들 중 콤마가 있으면 문자로 인식하기 때문에 천단위 구분(thousands=',')이라고 알려주면 콤마를 제거하고 숫자형으로 읽음
데이터 기본정보 확인
crime_raw_data.info()
→ 인덱스 범위와 데이터의 수가 이상한 것을 확인
중복되지 않는 고유 값 확인하기
▶ unique(): 중복되지 않는 고유값 나타남
▶ nan 값이 들어가있음
crime_raw_data["최종"].unique()
array(["살인", "강도", "강간", "절도", "폭력", nan], dtype=object)nan 값 확인
▶ isnull() : nan값인 것
▶ 마스킹해서 데이터 프레임 형태로 나오게 추출
crime_raw_data[crime_raw_data["죄종"].isnull()]
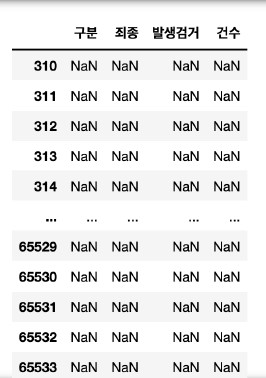
nan 값이 아닌 데이터만 담기
▶ notnull() : nan값이 아닌 것
crime_raw_data = crime_raw_data[crime_raw_data["죄종"].notnull()]
crime_raw_data.info() 
- Pandas pivot_table
데이터 불러오기
df = pd.read_excel("../data/02. sales-funnel.xlsx")
df.head()Name을 인덱스로 두고 재정렬
pd.pivot_table(df, index=["Name"])Index를 여러개 지정
pd.pivot_table(df, index=["Name", "Rep", "Manager"]) 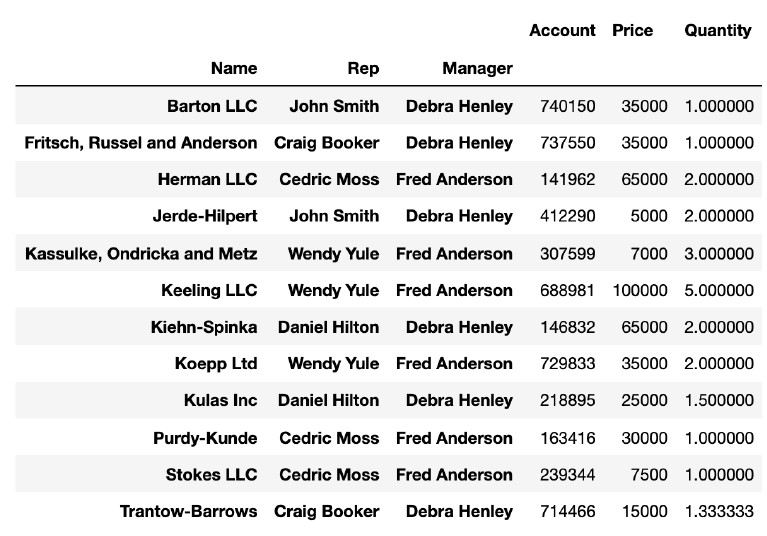
values 지정
pd.pivot_table(df, index=["Manager", "Rep"], values=["Price"]) 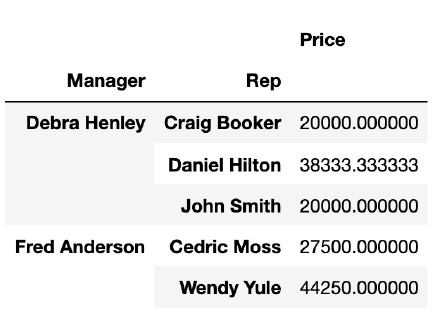
values에 함수 적용 가능
-디폴트는 평균, 합산 등의 다른 함수 적용할 때 aggfunc옵션 지정
pd.pivot_table(df, index=["Manager", "Rep"], values=["Price"]), aggfunc=np.sum) 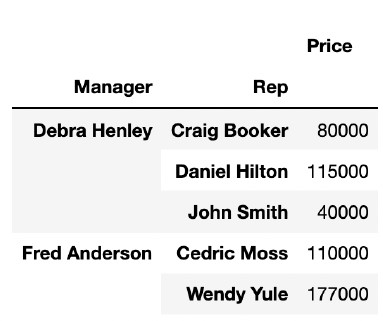
개수 지정
pd.pivot_table(df, index=["Manager", "Rep"], values=["Price"]), aggfunc=[np.mean, len])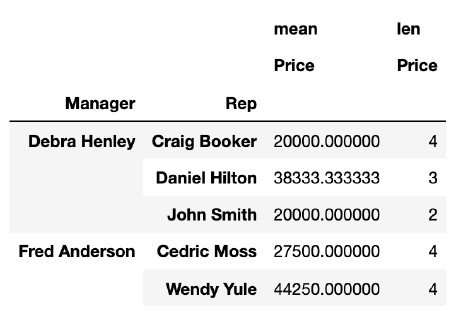
columns 설정
-
분류 지정
columns -
NaN에 대한 처리 지정
fill_value=0 -
sum(합계)에 대한 것은 price로 Mean(평균)에 대한 것은 Quantity로
-
총계(All)추가
margins=Truepd.pivot_table( df, index={"Manager", "Rep", "Proudct"], values=["Price", "Quantity"], aggfunc=[np.sum, np.mean], fill_value=0, margins=True, )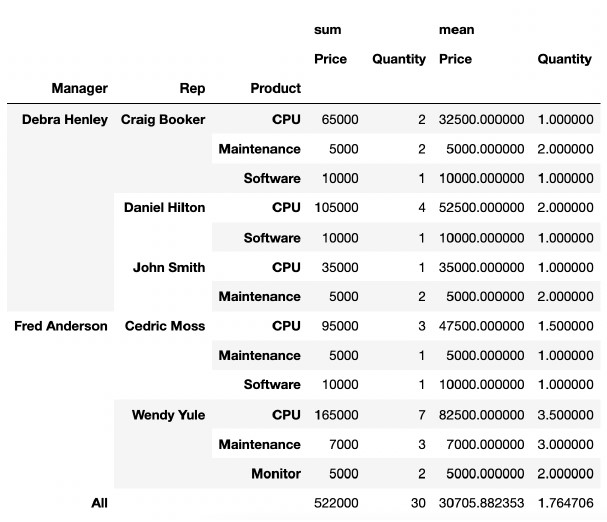
<범죄 현황 데이터에 Pandas Pivot Tabel 적용>
crime_station = crime_raw_data.pivot_table(
crime_raw_data, index=["구분"], columns=["죄종", "발생검거"], aggfunc=[np.sum]
)
crime_station.head()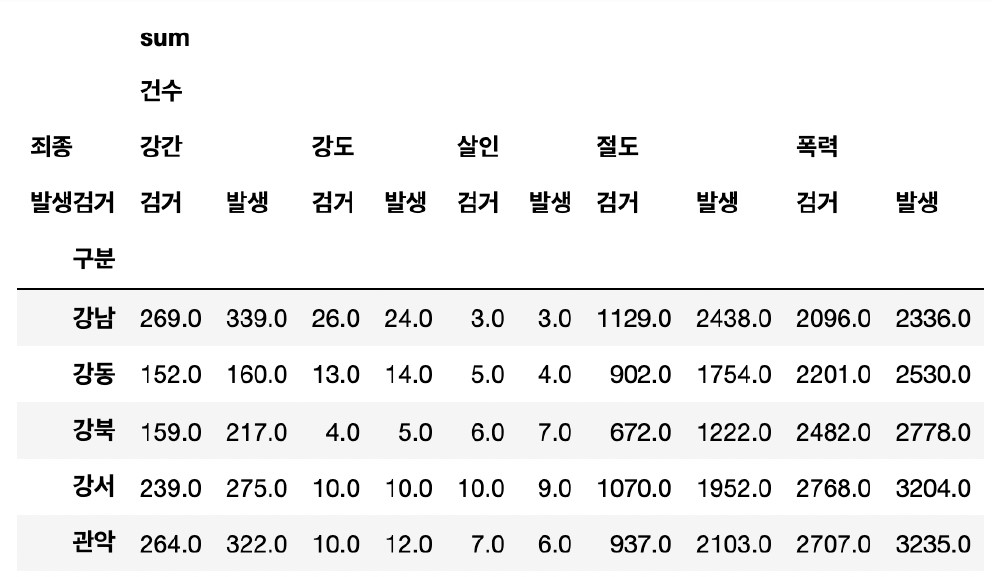
멀티 인덱스 확인하기
crime_station.columns 
멀티 인덱스 제거 columns.droplevel
crime_station.columns = crime_station.columns.droplevel([0,1])
crime_station.columns
crime_station.head() 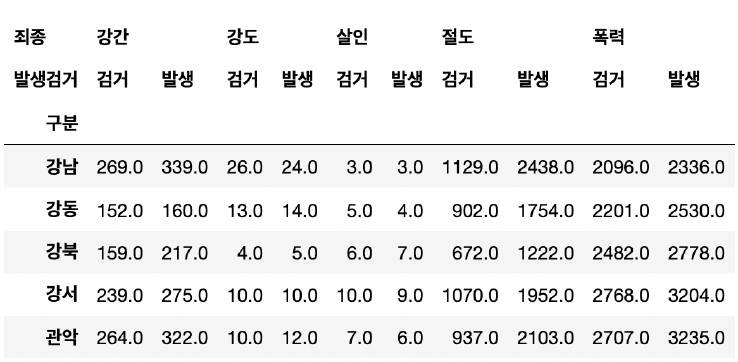

파이팅