웹 데이터 Beautiful Soup 1
-
설치
conda install -c anaconda beautifulsoup4
pip install beautifulsoup4
- 모듈
from bs4 import BeautifulSouppage = open("../data/03. test_first.html","r").read()
soup = BeautifulSoup(page, "html.parser")
print(soup.prettify)원하는 데이터 읽어오기
-
soup.find(): 하나의 태그 반환 -
soup.p, soup.find("p"): 처음 발견한 p 태그만 출력 -
다중조건 사용하기
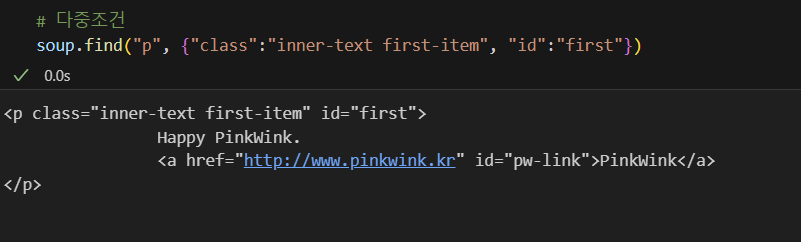
-
조건 찾을 때 파이썬 예약어는 언더바 붙여서 사용하기
#파이썬 예약어 class, id, def, str, int, tuple,..
soup.find("p", class_="outer-text first-item")soup.find_all(): 여러개의 태그를 반환, list 형태로 반환
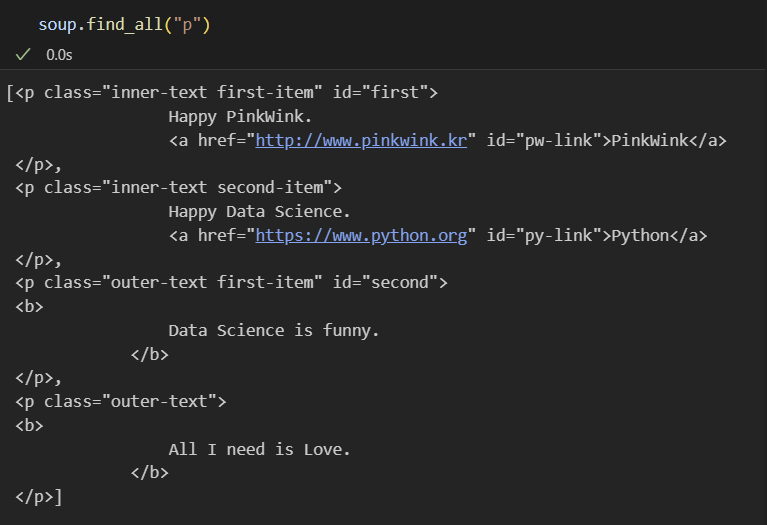
- 텍스트 보는 매서드 3가지
print(soup.find_all("p")[0].text)
print(soup.find_all("p")[1].string)
print(soup.find_all("p")[1].get_text())- p 태그 리스트에서 텍스트 속성만 출력
for each_tag in soup.find_all("p"):
print("="*40)
print(each_tag.text)- 외부로 연결되어 있는 링크 주소 알아내기
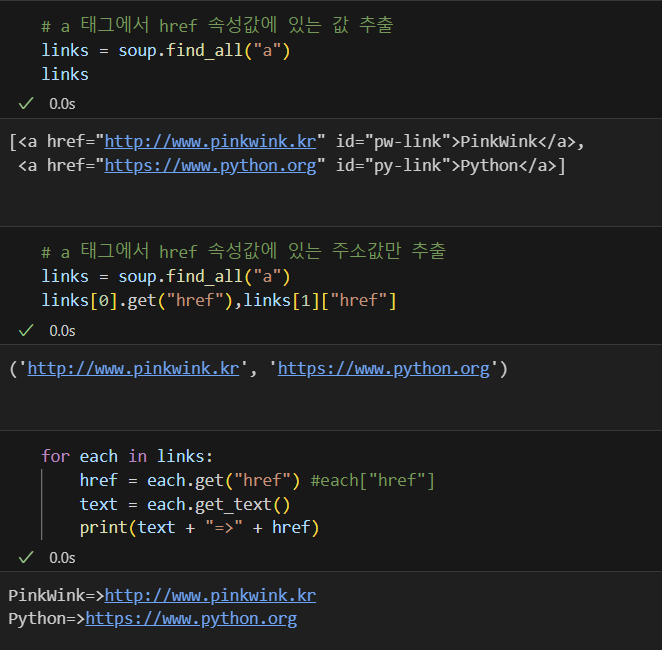
크롬 개발자 도구
모듈
#import
from urllib.request import urlopen
from bs4 import BeautifulSoupurl = "https://finance.naver.com/marketindex/"
page = urlopen(url)
soup = BeautifulSoup(page, "html.parser")
print(soup.prettify())
#BeutifulSoup은 HTML 등의 마크업 언어를 파싱하여 파이썬에서 사용하기 쉬운 형태로 변환하는 라이브러리
#prettify() 매서드는 BeautifulSoup 객체에서 사용할 수 있는 매서드 중 하나로 파싱된 HTML 코드를 들여쓰기하여 예쁘게 출력원하는 데이터 검색
#1번 soup.find_all("span", "value")
#2번 soup.find_all("span", class_="value")
#3번 soup.find_all("span", {"calss":"value"})상태코드
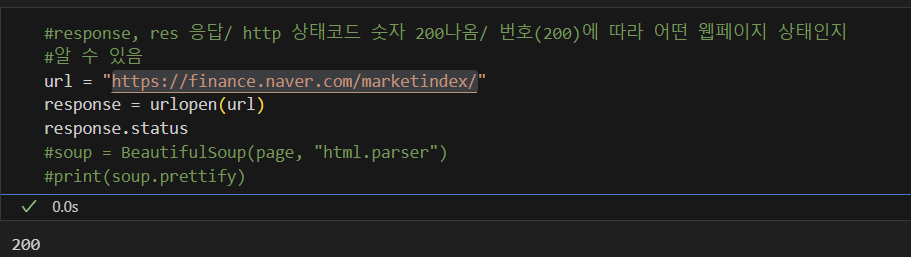
find, select_one : 단일선택
find_all, select : 다중선택 select 데이터 검색
"#" : id
"." : class
> : 바로 하위 문장 뜻함 4개 데이터 수집
exchange_datas = []
baseUrl = "https://finance.naver.com"
for item in exchangeList:
data={
'title': item.select_one(".h_list").text,
'exchange': item.select_one(".value").text,
'change': itme.select_one(".change).text,
'updown': item.select_one(
".head_info.head_info > .blind"
).text,
'link' : baseUrl + item.select_one("a").get("href")
}
exchange_datas.append(data)
df = pd.DataFrame(exchange_datas)
df.to_excel("./naverfinance.xlsx", encoding="utf-8")위키백과 문서 정보 가져오기 2
urllib.parse.quote(): 문자열을 URL인코딩하는 함수
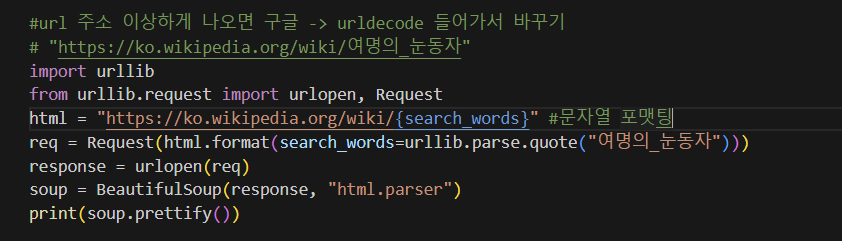
원하는 데이터 추출
- ul 태그 전체 조회하여 문자열 추출
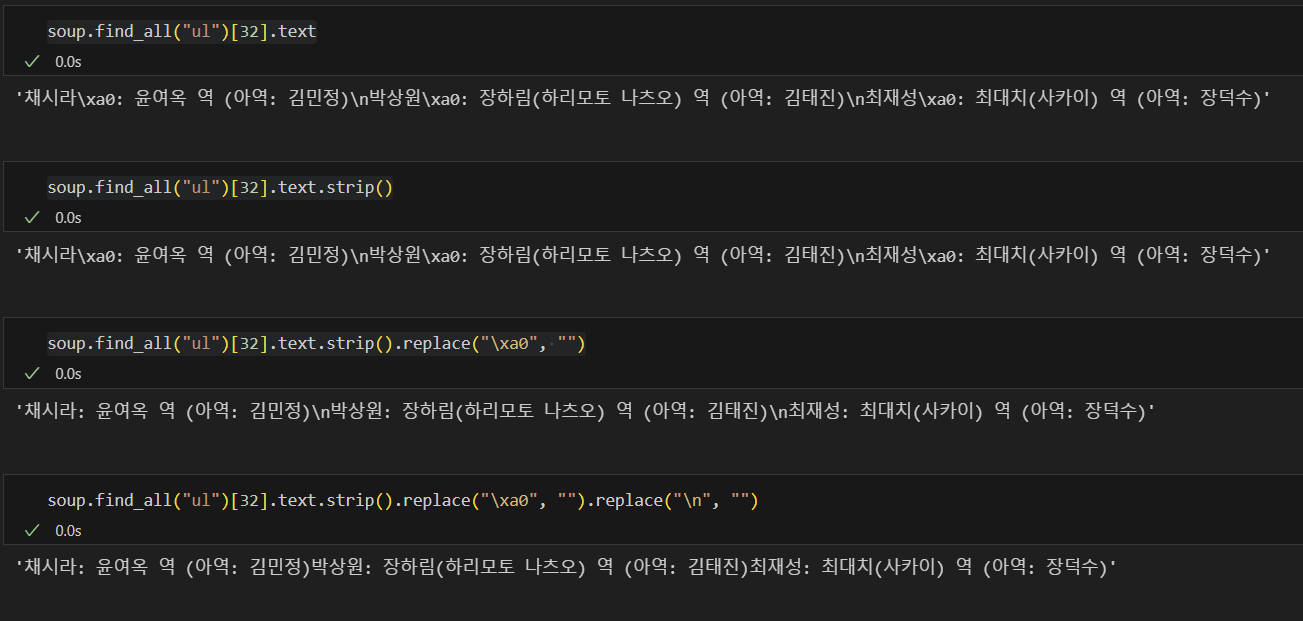
데이터 가공
text: 문자열 반환strip(): 문자열 양 끝에 있는 공백과 개행 문자 등 제거replace(): 문자열에서 특정 문자열을 다른 문자열로 대체
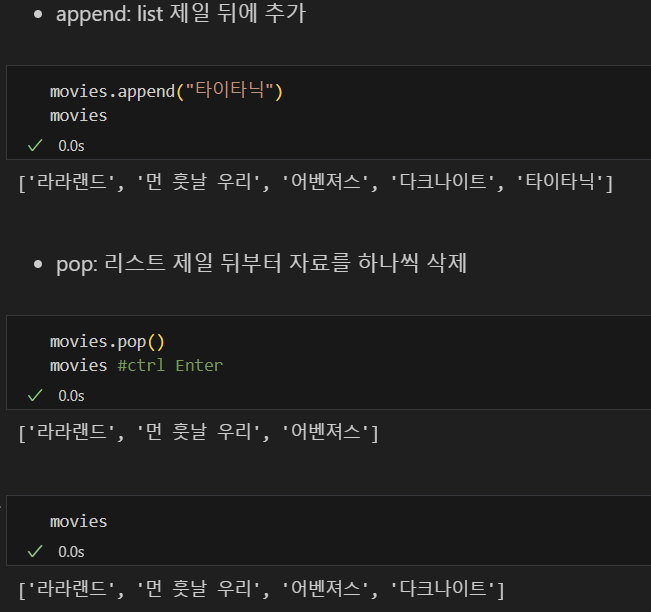
Python List 데이터형 3
- 리스트 변경
append(), pop(), extend(), remove(), sliceing, insert(),isintance
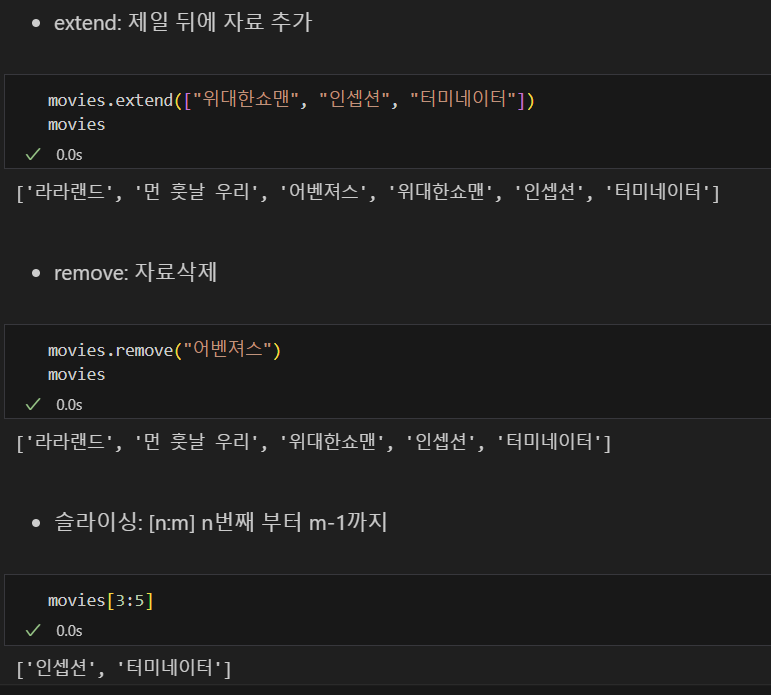
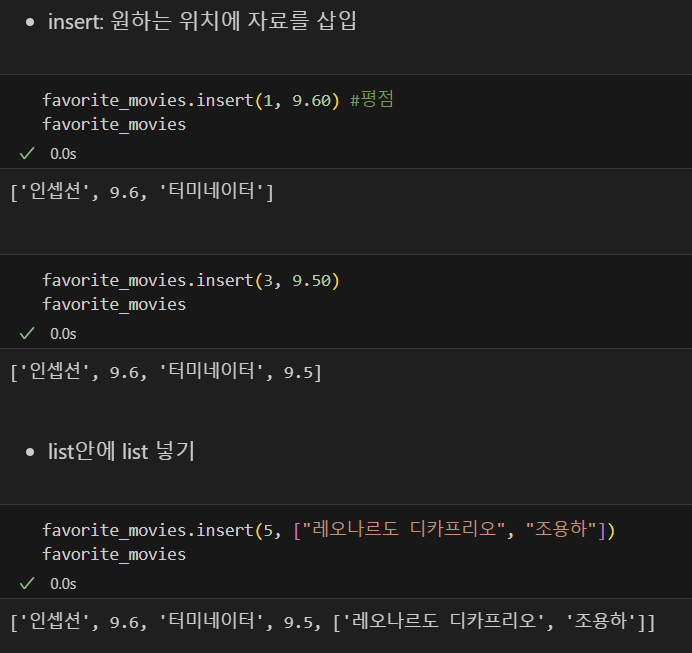
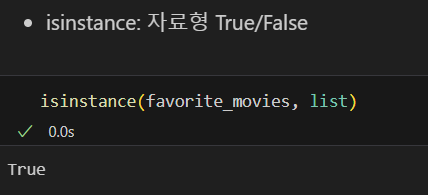
- for문으로 list 요소 분리
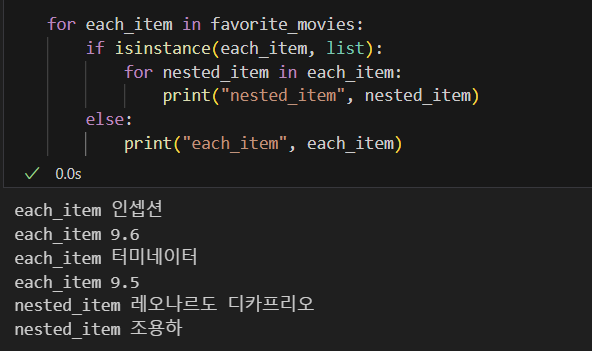

파이팅