APA
Brown, T. B., Mané, D., Roy, A., Abadi, M., & Gilmer, J. (2017). Adversarial patch. arXiv preprint arXiv:1712.09665.
💻한 줄 요약
어떤 이미지에도 적용 가능하며(universal) 패치에 어느 정도 변형이 가해져도 상관없고(robust) 특정한 타겟 클래스로 classifier가 인식하도록 하는(targeted) Adversarial Patch를 통해 물리적으로 인공지능 모델을 공격할 수 있다.
New Physical Adversarial Attack using Adversarial Patch
Introduction
현재까지의 adversarial example을 생성하는 방법으로 L-BFGS, FGSM, DeepFool, PGD, LS-PGA, JSMA 등 많은 방법들이 논의되었다. 이들은 작은 픽셀을 수정하거나, 아주 적은 수의 픽셀을 수정하거나 고정된 위치에 작은 패치를 붙이는 방식으로 공격을 진행하였다.
그리고 이를 실제 physical world에서 공격하고자 많은 연구를 진행했었다. 실제로 카메라를 통해 머신러닝 모델에 input으로 들어가도 adversarial attack을 진행할 수 있었다. 그리고 이를 3D 공간에도 적용할 수 있었으며 대표적으로 facial recognition을 피하기 위한 adversarial glasses가 있었다. 이와 함께 물리적인 공격을 대항하는 방법 또한 논의되었다.
지금까지의 연구들은 굉장히 작고 눈에 잘 보이지 않는 adversarial example을 생성하여 공격하고 방어하였지만 본 논문에서는 adversarial patch를 통해 제한이 없는(unrestrict)한 attack을 진행한다.
-실제로 생성한 Adversarial Patch를 통해 Classifier를 공격한 모습(banana➡️toaster)
Approach
1. 기존의 방법(The traditional strategy)
입력되는 이미지를 , 모델의 결과로 나올 클래스를 라고 할 때, 는 가 모델의 input으로 들어왔을 때 output으로 클래스가 나올 확률을 말한다. 여기서 target class를 이라고 할 때, Adversarial example 는 의 값을 최대화시키는 값이다. 그렇기에 nerual network에서 이미지는 미분이 가능한 상태로 진행하기에 경사하강법(gradient descent)을 이용하여 미분을 반복적으로 수행해서 이미지를 조금씩 변형해가며 Adversarial example을 생성한다.
2. Adversarial Patch
여러 개의 이미지를 학습시키는 방법으로 Patch를 생성하였다. 가 모델의 input으로 들어올 때 patch 와 패치가 들어갈 위치(patch location) , 패치를 변형시키는 파라미터(patch transformations) 일 때, 패치를 적용시키는 연산자(patch application operator)로 를 정의할 수 있다. 이 연산을 통해 이미지 의 특정위치 에 패치 를 붙이는 행위를 반복하여 동작하여 어느 위치에 붙이더라도 결과가 target class인 로 나오게끔 한다.

여기에 Expectation over Transformation(EOT)를 적용하여 만들어진 Adversarial image(A 연산의 결과물)이 특정 클래스 로 분류될 확률을 높이는 를 찾는 학습을 진행하는 아래의 수식이 완성된다.
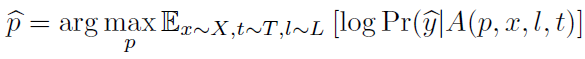
또한 변형이 눈에 덜 띄도록 각 픽셀별 차이가 아래로 나오도록 변형을 진행하였다.
Experimental Results
본 논문에서는 test를 위해 다섯 개의 ImageNet모델(inceptionv3, resnet50, xception, VGG16, VGG19)에 대해 white box ensemble attack을 진행하여 하나의 패치를 생성하여 각 모델에 대한 win rate를 averaging하여 평가하였다.
두 번째로, white box single model attack을 통해 하나의 모델에 대한 attack을 진행하였고 마지막으로 4개의 모델로 학습을 진행하여 패치를 생성하고 나머지 5번째 모델을 black box attack하는 형식으로 실험을 진행하였다.
-그냥 토스트 사진을 두는 것보다 더욱 높은 Attack success rate가 나오는 것을 볼 수 있다.
추가적으로, 기존의 Tie Dye 패턴등과 L2 distance가 크게 차이나지 않는 방향으로 patch를 생성하고 공격성공률을 비교하였다.
-이를 통해 기계적으로 만들어지는 패치 외에도 공격자가 의도한 모양을 가지도록 패치를 생성할 수 있음을 증명하였다.
이렇게 생성한 Adversarial Patch를 출력하여 실제 Classifier에 적용해 공격이 성공한 것을 증명하였다.

Conclusion
본 논문에서는 이렇게 어떤 이미지에도 적용 가능하며(universal) 패치에 어느 정도 변형이 가해져도 상관없고(robust) 특정한 타겟 클래스로 classifier가 인식하도록 하는(targeted) Adversarial Patch를 통해 물리적으로 인공지능 모델을 공격할 수 있음을 증명하였다. 기존에는 작은 크기의 perturbation에 집중하였다면 이제는 unrestrict한 attack에 대해서도 관심을 가져야 한다.
Appendix

📒Opinion
연구 과정에서 Physical Adversarial Attack을 필요로 해서 본 논문을 읽게 되었다. 어떤 이미지든, 어느 위치에 있든 상관없이 하나의 클래스로 분류하도록 모델을 공격하는 기법이기에 적용가능성이 매우 높은 연구인 것 같다. 추후 그래픽으로 적용하는 Adversarial example과 Object Detector를 대상으로 한 Adversarial Patch에 대한 논문도 살펴봐야겠다.
