해당 시리즈의 게시물은 codelatte.io 사이트를 참고하여 정리한 내용입니다.
https://www.codelatte.io/courses/java_programming_basic
20. enum
enum은 JVM에 의해 Singleton으로 생성되며 의미 있는 상수를 정의하고 프로그램의 안전성을 위해 사용된다.
enum CafeFoodCategory {
BREAD, CAKE, COFFEE, BEVERAGE
}enum이 해결할 수 있는 문제를 아래 예시 코드를 통해 설명하겠다.
public void eat(int foodCategory) {
if (0 == foodCategory) {
System.out.println("빵");
} else if (1 == foodCategory) {
System.out.println("케이크");
} else if (2 == foodCategory) {
System.out.println("커피");
} else if (3 == foodCategory) {
System.out.println("음료");
} else {
System.out.println("존재하지않음");
}
}현재 eat() 메서드는 0 ~ 3까지 정수형 데이터를 넣으면 빵, 케이크, 커피, 음료를 출력한다.
그렇다면 해당 메서드를 사용하려면 보통은 아래와 같이 작성할 것이다.
eat(0);
eat(1);근데 이렇게 보니까 0이 빵을 의미하는지 케이크를 의미하는지, 또는 1이 케이크인지 커피인지 알아보기 힘들다.
이런 불편함을 해소하기 위해 심볼릭 상수로 만들어서 의미를 부여했다.
final class FoodCategory {
public static final int BREAD = 0;
public static final int CAKE = 1;
public static final int COFFEE = 2;
public static final int BEVERAGE = 3;
}eat(FoodCategory.BREAD);
eat(FoodCategory.CAKE);아까보단 훨씬 이해하기 쉬운 것은 사실이나, 해당 코드에는 본질적인 문제가 있다. eat() 메서드는 여전히 정수로 된 모든 인자를 전달받을 수 있으므로, 아래와 같이 엉터리 코드도 작성이 가능하다.
eat(-1);
eat(-100);위 2가지 문제인 코드 가독성과 엉터리 코드도 모두 막을 수 있는 것이 enum이다.
enum FoodCategory {
BREAD, CAKE, COFFEE, BEVERAGE
}public void eat(FoodCategory foodCategory) {
if (FoodCategory.BREAD == foodCategory) {
System.out.println("빵");
} else if (FoodCategory.CAKE == foodCategory) {
System.out.println("케이크");
} else if (FoodCategory.COFFEE == foodCategory) {
System.out.println("커피");
} else if (FoodCategory.BAVERAGE == foodCategory) {
System.out.println("음료");
}
}이렇게 하면 아래와 같이 eat 메서드를 FoodCategory enum에 정의된 상수만 전달받을 수 있게 된다.
eat(FoodCategory.BREAD);
eat(FoodCategory.CAKE);20-1. ordinal()
ordinal() 메서드는 enum 상수에 의해 정의된 순서값을 반환한다.
enum FoodCategory {
BREAD, CAKE, COFFEE, BEVERAGE
}
System.out.println(FoodCategory.CAKE.ordinal());
// 출력 : 120-2. name()
name() 메서드는 enum 상수에 정의된 이름을 반환한다.
enum FoodCategory {
BREAD, CAKE, COFFEE, BEVERAGE
}
System.out.println(FoodCategory.CAKE.name());
// 출력 : CAKE20-3. Enum을 다르게 정의하기
enum 상수에 특정한 값을 정의할 수 있다.
enum FoodCategory {
BREAD(2800),
CAKE(17000),
COFFEE(4300),
BEVERAGE(2500);
int cost;
FoodCategory(int cost) {
this.cost = cost;
}
}상수에 특정한 값을 지정할 때는 상수의 끝맺음에 반드시 세미콜론(;)을 작성해 주어야 한다. 그리고 enum 내에 변수를 선언하고 생성자를 통해 값을 저장하면 다음과 같이 사용할 수 있다.
System.out.println(FoodCategory.BREAD.cost);
System.out.println(FoodCategory.CAKE.cost);
System.out.println(FoodCategory.COFFEE.cost);
System.out.println(FoodCategory.BEVERAGE.cost);
// 출력
2800
17000
4300
2500또한 하나의 특정한 값이 아니라 여러 개의 특정한 값도 지정할 수 있다.
enum FoodCategory {
BREAD("빵", 2800),
CAKE("케이크", 17000),
COFFEE("커피", 4300),
BEVERAGE("음료", 2500);
int name;
int cost;
FoodCategory(String name, int cost) {
this.name = name;
this.cost = cost;
}
}
System.out.println(FoodCategory.CAKE.name);
System.out.println(FoodCategory.CAKE.cost);
// 출력
케이크
17000enum 특성상 내부적으로 singleton 방식으로 관리하기 대문에 enum의 생성자는 기본적으로 private으로 처리된다.
// 불가능한 코드
FoodCategory foodCategory = new FoodCategory(…);20-4. Singleton Pattern
Singleton 패턴은 인스턴스 생성 패턴 중 하나로 인스턴스를 한번 생성하고 인스턴스 내용을 여러 메서드에서 공유하여 사용할 수 있는 패턴이다.
public class Configuration {
private static Configuration configuration;
private Configuration() {
}
public static Configuration getInstance() {
if (null == configuration) {
configuration = new Configuration();
}
return configuration;
}
}new 키워드로 인스턴스를 생성하지 못하게 함과 동시에 인스턴스를 생성할 수 있는 특정 정적 메서드를 통해서만 인스턴스를 생성하도록 하고 생성된 인스턴스는 정적 변수에 저장하여 인스턴스에 접근할 수 있도록 한다.
따라서 Configuration.getInstance()를 통해서만 생성할 수 있으며 configuration 정적 변수가 null일 경우 생성자를 통해 인스턴스를 생성한다.
Configuration configuration1 = Configuration.getInstance();
System.out.println(configuration1);
// 동일한 해시코드 Configuration@610455d6
Configuration configuration2 = Configuration.getInstance();
System.out.println(configuration2);
// 동일한 해시코드 Configuration@610455d6Singleton 인스턴스 해제
public class Configuration {
private static Configuration configuration;
…
public void free() {
configuration = null;
}
…
}
Configuration configuration = Configuration.getInstance();
…
configuration.free();※ Singleton Pattern vs 정적 변수, 메서드
먼저 Singleton 클래스의 경우 아래와 같다.
public class Configuration {
private static Configuration configuration;
private String cafeName = "카페";
private String cafeAddress = "저 먼나라 주소";
private Configuration() {
}
public static Configuration getInstance() {
if (null == configuration) {
configuration = new Configuration();
}
return configuration;
}
public String getCafeName() {
return cafeName;
}
public String getCafeAddress() {
return cafeAddress;
}
}
Configuration configuration1 = Configuration.getInstance();
System.out.println(configuration.getCafeName());
// 출력 "카페"
System.out.println(configuration.getCafeAddress());
// 출력 "저 먼나라 주소"그리고 Singleton 대신 정적 변수, 메서드를 사용한 클래스는 아래와 같다.
public class Configuration {
private static String cafeName = "카페";
private static String cafeAddress = "저 먼나라 주소";
public static String getCafeName() {
return cafeName;
}
public static String getCafeAddress() {
return cafeAddress;
}
}
System.out.println(Configuration.getCafeName());
// 출력 "카페"
System.out.println(Configuration.getCafeAddress());
// 출력 "저 먼나라 주소"결과만 놓고 보면 둘 다 큰 차이점이 없어보인다. 하지만 인스턴스 지연 생성(Lazy Load)를 생각하면 확연한 차이가 있다.
정적 변수와 정적 메서드는 자바 메모리 모델에서 Method Area에 저장되며 프로그램 시작 시 메모리에 할당되고 적재된다. 이 말은 즉슨 해당 정적 변수와 메서드를 사용하지 않더라고 메모리 공간을 차지하게 된다.
반면 Singleton Pattern은 호출하지 않는다면 최소 인스턴스 참조 값을 저장한느 configuration 정적 변수와 인스턴스를 생성하기 위한 Configuration.getInstance() 정적 메서드만 메모리에 할당된다.
따라서 진짜 필요할 때 Configuration.getInstance()를 호출하여 최초 메모리에 할당하는 지연 생성(Lazy Load)가 가능하며 좀 더 유동적으로 메모리를 사용할 수 있다.
21. Generic
자바 제네릭은 Inpa Dev님의 자바 제네릭(Generics) 개념 & 문법 정복하기를 참고하여 정리하였습니다.
https://inpa.tistory.com/entry/JAVA-%E2%98%95-%EC%A0%9C%EB%84%A4%EB%A6%ADGenerics-%EA%B0%9C%EB%85%90-%EB%AC%B8%EB%B2%95-%EC%A0%95%EB%B3%B5%ED%95%98%EA%B8%B0
Generic은 클래스 내부에서 사용할 데이터 타입을 외부에서 지정하는 기법을 의미한다.
ArrayList<String> list = new ArrayList<>();꺾쇠 괄호<> 키워드를 통해 제네릭을 선언하며, <> 안에는 타입명을 적는다. 예시 코드에는 String 타입으로 지정되어 있으므로 문자열 데이터만 리스트에 저장할 수 있게 되는 것이다.
우리가 변수를 선언할 때 기본 자료형을 통해 타입을 지정해 주듯이, 제네릭은 객체(Object)에 타입을 지정해주는 것과 같다.
21-1. 제네릭 타입 매개변수
제네릭을 선언하는 <>를 다이아몬드 연산자라고 하며, <> 안에 식별자 기호를 지정함으로써 파라미터화가 가능하다.
마치 메서드가 매개변수를 받아 사용하는 것과 유사하기 때문에 타입 매개변수(타입 변수)라고 부른다.
List<T> // 타입 매개변수
List<String> stringList = new ArrayList<String>(); // 매개변수화된 타입이러한 타입 매개변수는 제네릭을 이용한 클래스나 메서드를 설계할 때 사용한다.
class FruitBox<T> {
List<T> fruits = new ArrayList<>();
public void add(T fruit) {
fruits.add(fruit);
}
}<T> 기호를 이용하여 제네릭을 붙인 다음, FruitBox 클래스를 정의하였다. 또한 List의 제네릭 타입을 <T>, add 메서드의 매개변수 역시 T 타입으로 지정되어 있다.
이를 인스턴스화 하기 위해서는 아래와 같이 파라미터에 지정해주고 싶은 타입명을 넣어주면 된다.
// 제네릭 타입 매개변수에 정수 타입을 할당
FruitBox<Integer> intBox = new FruitBox<>();
// 제네릭 타입 매개변수에 실수 타입을 할당
FruitBox<Double> intBox = new FruitBox<>();
// 제네릭 타입 매개변수에 문자열 타입을 할당
FruitBox<String> intBox = new FruitBox<>();
// 클래스도 넣어줄 수 있다. (Apple 클래스가 있다고 가정)
FruitBox<Apple> intBox = new FruitBox<Apple>();이렇게 타입명을 지정하여 선언만하면! 클래스 내부에 있던 List의 제네릭 타입, add 메서드의 매개변수 타입이 모두 선언할 때 지정했던 동일한 타입으로 설정된다.
이를 전문용어로 구체화(Specialization)라고 한다.
타입 파라미터 생략
제네릭은 객체를 사용하는 문법을 보면 아래와 같이 양쪽 두 군데에 꺾쇠 괄호 제네릭 타입을 지정한다.
JDK 1.7 이후부터 new 키워드 이후 인스턴스를 생성하는 부분에서는 제네릭 타입을 생략해도 알아서 추론해서 넣어주는 점도 참고하길 바란다.
FruitBox<Apple> intBox = new FruitBox<Apple>();
// 다음과 같이 new 생성자 부분의 제네릭의 타입 매개변수는 생략할 수 있다.
FruitBox<Apple> intBox = new FruitBox<>();할당 가능 타입은 참조형 타입
제네릭에서 할당 가능한 타입은 참조형 타입만 가능하다. 따라서 int, double과 같이 기본 자료형은 제네릭 타입 파라미터에 지정할 수 없다.
여기서 우리가 추후 학습할 Wraper 클래스를 만들고 사용하는 이유가 나온다. 위 코드에서 Integer, Double이 Wrapper 클래스이며, 사실 int, double과 똑같은 역할과 기능을 한다.
하지만 자바는 객체 지향 프로그래밍이므로... 제네릭 사용을 위해서 별도로 존재한다고 이해하면 된다.
// 기본 타입 int는 사용 불가 !!!
List<int> intList = new List<>();
// Wrapper 클래스로 넘겨주어야 한다. (내부에서 자동으로 언박싱되어 원시 타입으로 이용됨)
List<Integer> integerList = new List<>();클래스가 타입으로 온다 - 다형성 적용
우리가 학습한 클래스끼리 상속을 통해 관계를 맺는 객체 지향 프로그래밍의 다형성 원리를 그대로 적용할 수 있다는 말도 된다.
class Fruit { }
class Apple extends Fruit { }
class Banana extends Fruit { }
class FruitBox<T> {
List<T> fruits = new ArrayList<>();
public void add(T fruit) {
fruits.add(fruit);
}
}
public class Main {
public static void main(String[] args) {
FruitBox<Fruit> box = new FruitBox<>();
// 제네릭 타입은 다형성 원리가 그대로 적용된다.
box.add(new Fruit());
box.add(new Apple());
box.add(new Banana());
}
}제네릭 선언부인 <> 안에 부모 클래스인 Fruit이 선언되었으나, box.add(new Apple());과 같이 자식 클래스로 인스턴스를 생성하는 것이 가능하다. (업캐스팅 원리)
21-2. 복수 타입, 중첩 타입 파라미터
제네릭은 꼭 1개만 사용하라는 법은 없다. 필요하면 얼마든지 2개, 3개, 4개... 이상으로 만들 수 있다.
또한 우리가 지금까지 <T> 기호를 사용하여 표현했지만 사실 문법적으로 정해진 것은 없고, 단지 관례적으로 많이 사용한다.
아래 표는 관례적으로 자주 사용하는 식별자 기호이다.
| 타입 | 설명 |
|---|---|
| <T> | 타입(Type) |
| <E> | 요소(Element), e.g. List |
| <K> | 키(Key), e.g. Map<k, v> |
| <V> | 리턴 값 or 매핑 값(Variable) |
| <N> | 숫자(Number) |
| <S, U, V> | 2, 3, 4번째 타입 |
아래와 같이 FruitBox에 2가지 타입을 넣어 복수 타입으로 작성도 가능하다.
import java.util.ArrayList;
import java.util.List;
class Apple {}
class Banana {}
class FruitBox<T, S> {
List<T> apples = new ArrayList<>();
List<S> bananas = new ArrayList<>();
public void add(T apple, S banana) {
apples.add(apple);
bananas.add(banana);
}
}
public class Main {
public static void main(String[] args) {
// 복수 제네릭 타입
FruitBox<Apple, Banana> box = new FruitBox<>();
box.add(new Apple(), new Banana());
box.add(new Apple(), new Banana());
}
}제네릭 객체를 통째로 타입 파라미터로 받아서 사용하는 중첩 타입 파라미터도 가능하다. 아래 코드를 보자.
public static void main(String[] args) {
// LinkedList<String>을 원소로서 저장하는 ArrayList
ArrayList<LinkedList<String>> list = new ArrayList<LinkedList<String>>();
LinkedList<String> node1 = new LinkedList<>();
node1.add("aa");
node1.add("bb");
LinkedList<String> node2 = new LinkedList<>();
node2.add("11");
node2.add("22");
list.add(node1);
list.add(node2);
System.out.println(list);
}LinkedList<String> 자체를 타입 파라미터로 받아서 ArrayList<> 안에 넣어준 형태이다...
(가독성 어떡할꺼)
출력해보면 이중 리스트처럼 나온다.
21-3. 제네릭 사용 이유
사실 이 부분이 제일 중요한데, 굳이 우리가 저렇게 생소하고 적응도 안되는 제네릭을 써야하는 이유는 다음과 같다.
- 컴파일 타임에 타입 검사를 통해 예외 방지
- 불필요한 캐스팅을 없애 성능 향상
컴파일 타임에 타입 검사
만약 상속관계에 있는 클래스에서 여러 타입을 다루고 싶은데 제네릭이 없다고 가정하면 아래와 같이 클래스를 작성해야 한다.
class Apple {}
class Banana {}
class FruitBox {
// 모든 클래스 타입을 받기 위해 최고 조상인 Object 타입으로 설정
private Object[] fruit;
public FruitBox(Object[] fruit) {
this.fruit = fruit;
}
public Object getFruit(int index) {
return fruit[index];
}
}모든 클래스의 최상위 클래스인 Object를 타입으로 작성해줘야 한다.
그리고 아래와 같이 개발자가 실수로 Banana 타입을 형 변환 코드를 작성했다고 하자.
public static void main(String[] args) {
Apple[] arr = {
// Apple만 넣었는데
new Apple(),
new Apple()
};
FruitBox box = new FruitBox(arr);
Apple apple = (Apple) box.getFruit(0);
// 프로그램 실행 시 오류 발생
// 코드를 적을 때는 오류 안남
Banana banana = (Banana) box.getFruit(1);
}우리는 코드를 작성하는 과정에서 바로바로 빨간줄로 오류를 뿜어내주면 좋겠지만 안타깝게도 자바는 프로그램을 실행하면 나서야 ClassCastExecption 런타임 에러가 발생한다.
근데 제네릭을 사용하게 되면?
class FruitBox<T> {
private T[] fruit;
public FruitBox(T[] fruit) {
this.fruit = fruit;
}
public T getFruit(int index) {
return fruit[index];
}
}
public static void main(String[] args) {
Apple[] arr = {
new Apple(),
new Apple()
};
FruitBox<Apple> box = new FruitBox<>(arr);
Apple apple = (Apple) box.getFruit(0);
// 프로그램 실행 전에 컴파일 타임에서 잘못된 걸 잡아냄
Banana banana = (Banana) box.getFruit(1);
}제네릭 타입에 Apple로 선언하였으니 코드 상에서 Banana가 오류라고 바로 알려준다.
불필요한 캐스팅 없앰
이 역시 만약 Object 클래스를 사용했다가 다시 가져오려면 다운 캐스팅을 통해 가져와야 하고, 이는 곧 추가적인 오버헤드로 이어진다.
Apple[] arr = { new Apple(), new Apple(), new Apple() };
FruitBox box = new FruitBox(arr);
// 가져온 타입이 Object 타입이기 때문에 일일히 다운캐스팅을 해야함 - 쓸데없는 성능 낭비
Apple apple1 = (Apple) box.getFruit(0);
Apple apple2 = (Apple) box.getFruit(1);
Apple apple3 = (Apple) box.getFruit(2);근데 제네릭을 사용하게 되면?
// 미리 제네릭 타입 파라미터를 통해 형(type)을 지정해놓았기 때문에 별도의 형변환은 필요없다.
FruitBox<Apple> box = new FruitBox<>(arr);
Apple apple = box.getFruit(0);
Apple apple = box.getFruit(1);
Apple apple = box.getFruit(2);제네릭을 통해 선언하는 것 자체가 이미 타입 파라미터를 지정하는 의미이므로, 별도의 형 변환이 필요없어진다.
21-4. 제네릭 클래스 만들기
제네릭 클래스
class Sample<T> {
private T value; // 멤버 변수 val의 타입은 T 이다.
// T 타입의 값 val을 반환한다.
public T getValue() {
return value;
}
// T 타입의 값을 멤버 변수 val에 대입한다.
public void setValue(T value) {
this.value = value;
}
}
public static void main(String[] args) {
// 정수형을 다루는 제네릭 클래스
Sample<Integer> s1 = new Sample<>();
s1.setValue(1);
// 실수형을 다루는 제네릭 클래스
Sample<Double> s2 = new Sample<>();
s2.setValue(1.0);
// 문자열을 다루는 제네릭 클래스
Sample<String> s3 = new Sample<>();
s3.setValue("1");
}클래스명 옆에 <> 다이아몬드 연산자를 통해 제네릭을 선언하면 제네릭 클래스가 된다.
제네릭 인터페이스
interface ISample<T> {
public void addElement(T t, int index);
public T getElement(int index);
}
class Sample<T> implements ISample<T> {
private T[] array;
public Sample() {
array = (T[]) new Object[10];
}
@Override
public void addElement(T element, int index) {
array[index] = element;
}
@Override
public T getElement(int index) {
return array[index];
}
}
public static void main(String[] args) {
Sample<String> sample = new Sample<>();
sample.addElement("This is string", 5);
sample.getElement(5);
}인터페이스 역시 제네릭을 적용할 수 있다. 다만 implements 하는 구현체 클래스에서도 오버라이딩한 메서드를 제네릭 타입에 맞춰서 똑같이 구현해 주어야 한다.
제네릭 함수형 인터페이스
// 제네릭으로 타입을 받아, 해당 타입의 두 값을 더하는 인터페이스
interface IAdd<T> {
public T add(T x, T y);
}
public class Main {
public static void main(String[] args) {
// 제네릭을 통해 람다 함수의 타입을 결정
IAdd<Integer> o = (x, y) -> x + y; // 매개변수 x와 y 그리고 반환형 타입이 int형으로 설정된다.
int result = o.add(10, 20);
System.out.println(result); // 30
}
}우리가 이전에 학습한 람다 표현식과 제네릭을 합친 형태이다. 표현이 다소 생소하지만 제네릭을 통해 람다 함수의 타입을 결정하는 것 말고는 크게 어려운 부분은 없다.
제네릭 메서드
제네릭 메서드란 제네릭 클래스의 <T>에서 설정된 타입을 받아와 반환 타입으로 사용하는게 아니다.
class FruitBox<T> {
// 클래스의 타입 파라미터를 받아와 사용하는 일반 메서드
public T addBox(T x, T y) {
// ...
}
// 독립적으로 타입 할당 운영되는 제네릭 메서드
public static <T> T addBoxStatic(T x, T y) {
// ...
}
}우리가 지금까지 사용한 메서드는 일반 메서드이고, 제네릭 메서드는 직접 메서드에 <T> 제네릭을 설정함으로써 동적으로 타입을 받아와 사용할 수 있는 독립적으로 운용 가능한 메서드이다. (그래서 static 키워드와 함께 사용함)
FruitBox.<Integer>addBoxStatic(1, 2);
FruitBox.<String>addBoxStatic("안녕", "잘가");제네릭 타입을 메서드명 옆에 지정해줬으니, 호출할때에도 역시 메서드 왼쪽에 제네릭 타입을 적으면 된다.
이때 컴파일러가 제네릭 타입에 들어갈 데이터 타입을 메서드의 매개변수를 통해 추정할 수 있기 때문에, 대부분의 경우 아래와 같이 생략해서 호출한다.
// 메서드의 제네릭 타입 생략
FruitBox.addBoxStatic(1, 2);
FruitBox.addBoxStatic("안녕", "잘가");헷갈릴 수 있지만 잘 생각해보면 다이아몬드 연산자라고 하는 <>가 선언되면 독립적으로 타입을 받아와 운용한다고 생각하면 이해가 편하다.
(지금까지 일반 메서드는 <T>가 아니라 T만 적었음)
21-5. 제네릭 타입 범위 한정
제네릭에 타입을 지정해줌으로써 클래스 타입을 컴파일 타임에서 잡아낼 수 있는 안정성은 확보했지만, 사실 너무 자유롭다는 문제점이 있다.
// 숫자만 받아 계산하는 계산기 클래스 모듈
class Calculator<T> {
void add(T a, T b) {}
void min(T a, T b) {}
void mul(T a, T b) {}
void div(T a, T b) {}
}
public class Main {
public static void main(String[] args) {
// 제네릭에 아무 타입이나 모두 할당이 가능
Calculator<Number> cal1 = new Calculator<>();
Calculator<Object> cal2 = new Calculator<>();
Calculator<String> cal3 = new Calculator<>();
Calculator<Main> cal4 = new Calculator<>();
}
}위와 같이 숫자만 받아야 하는 계산기 클래스에 String, Object, Main 등 어떤 클래스가 들어가도 실행하기 전 오류는 발생하지 않을것이다.
이런 부분도 미리 제한하고 싶어서 나온게 제한된 타입 매개변수이다. 기본 문법은 다음과 같다.
<T extends [제한타입]>위의 계산기 클래스에서는 <T extends Number>을 딱 적어주면 Number 클래스와 그 하위 클래스들만 받도록 범위를 제한하게 된다.
참고로 클래스 끼리 상속하는 extends와 다른 의미이니 헷갈리지 말자. <> 안에 extends를 쓰면 제한하는 명령이 된다.
인터페이스 타입 한정
아래는 인터페이스 타입 한정 예시 코드이다.
// Readable 인터페이스
interface Readable {
void read(); // 읽는 동작을 정의
}
// Readable 인터페이스를 구현한 Student 클래스
public class Student implements Readable {
private String name;
// 생성자
public Student(String name) {
this.name = name;
}
// 이름 반환
public String getName() {
return name;
}
// 인터페이스의 메서드 구현
@Override
public void read() {
System.out.println(name + " is reading.");
}
}
// 제네릭 클래스 School
public class School<T extends Readable> {
private T member;
// 생성자
public School(T member) {
this.member = member;
}
// 멤버 반환
public T getMember() {
return member;
}
// 멤버의 동작 실행
public void performRead() {
member.read();
}
}
// main 메서드
public class Main {
public static void main(String[] args) {
// Student 객체 생성
Student student = new Student("John");
// School 객체 생성
School<Student> school = new School<>(student);
// 멤버 정보 출력
System.out.println("Member name: " + school.getMember().getName());
// 읽기 동작 실행
school.performRead();
}
}클래스 상속 관계랑 똑같이 생각하고 적용하면 되니 천천히 읽어보면 이해할 수 있을 것이다.
다중 타입 한정
만약 2개 이상의 타입을 동시에 상속한 경우로 타입을 제한하고 싶다면 "&" 연산자를 이용하면 된다.
이렇게 되면 해당 인터페이스들을 동시에 구현한 클래스가 제네릭 타입의 대상이 된다.
자바는 클래스 다중상속을 지원하지 않으므로, 오직 인터페이스로만 구현이 가능하다.
interface Readable {}
interface Closeable {}
class BoxType implements Readable, Closeable {}
class Box<T extends Readable & Closeable> {
List<T> list = new ArrayList<>();
public void add(T item) {
list.add(item);
}
}
public static void main(String[] args) {
// Readable 와 Closeable 를 동시에 구현한 클래스만이 타입 할당이 가능하다
Box<BoxType> box = new Box<>();
// 심지어 최상위 Object 클래스여도 할당 불가능하다
Box<Object> box2 = new Box<>(); // ! Error
}그리고 아래와 같이 제네릭 타입이 여러개인 다중 타입 파라미터를 사용하는 경우에도 각각 다중 제한을 거는 것도 가능하긴 한데... (솔직히 이쯤되면 개발자 고문시키는 거 같다)
interface Readable {}
interface Closeable {}
interface Appendable {}
interface Flushable {}
class School<T extends Readable & Closeable, U extends Appendable & Closeable & Flushable>
void func(T reader, U writer){
}
}재귀적 타입 한정
자기 자신이 들어간 표현식을 사용하여 타입 매개변수의 허용 범위를 한정 시키는 것을 의미한다. 주로 Comparable 인터페이스와 함께 사용한다.
Comparable은 객체끼리 비교할 때 compareTo() 메서드를 오버라이딩할 떄 구현하는 인터페이스이다.
예를 들어 <E extends Comparable<E>> 와 같이 제네릭 E의 타입 범위를 Comparable<E>로 한정한다는 중첩 표현이 가능하다.
듣기엔 어려워 보이는데 E에 아무 타입이나 대입해 보면 금방 이해한다.
E에 Integer를 대입하면 Integer는 자신과 같은 Integer 타입만 받겠다. == Integer 타입만 허용하겠다와 같은 의미
class Compare {
// 외부로 들어온 타입 E는 Comparable<E>를 구현한 E 객체 이어야 한다.
public static <E extends Comparable<E>> E max(Collection<E> collection) {
if(collection.isEmpty()) throw new IllegalArgumentException("컬렉션이 비어 있습니다.");
E result = null;
for(E e: collection) {
if(result == null) {
result = e;
continue;
}
if(e.compareTo(result) > 0) {
result = e;
}
}
return result;
}
}
public static void main(String[] args) {
Collection<Integer> list = Arrays.asList(56, 34, 12, 31, 65, 77, 91, 88);
System.out.println(Compare.max(list)); // 91
Collection<Number> list2 = Arrays.asList(56, 34, 12, 31, 65, 77, 91, 88);
System.out.println(Compare.max(list2)); // ! Error - Number 추상 메서드는 Comparable를 구현하지않았기 때문에 불가능
}위 코드는 컬렉션을 인자로 받아 컬렉션의 요소들의 최대값을 구해 반환하는 메서드이다.
Comparable<T>를 실제로 사용할 때에는 주로 아래와 같이 구현체 클래스를 직접 대입해서 사용한다.
static class Car implements Comparable<Car> {
int x;
int y;
int cost;
int dir;
public Car(int x, int y, int cost, int dir) {
this.x = x;
this.y = y;
this.cost = cost;
this.dir = dir;
}
@Override
public int compareTo(Car o) {
return this.cost - o.cost;
}
}Car 클래스를 변수 cost를 기준으로 비교하겠다는 의미가 되며, 실제로 우선순위 큐에 해당 Car 클래스를 집어넣거나 하면 cost를 비교하여 작은 값부터 빼올 수 있다.
21-6. 제네릭 와일드 카드
배열과 같은 일반적인 변수 타입과 달리 제네릭 서브 타입 간에는 형변환이 불가능하다. 심지어 대입된 타입이 최상위 클래스인 Object일지라도 말이다.
이전에 설명한 타입 파라미터의 다형성은 포함 원소로서 가능하다는 말이지 형 변환은 객체 대 객체를 말하는 것이니 다른 개념이다.
// 배열은 OK
Object[] arr = new Integer[1];
// 제네릭은 ERROR
List<Object> list = new ArrayList<Integer>();List<Object> listObj = null;
List<String> listStr = null;
// 에러. List<String> -> List<Object>
listObj = (List<String>) listStr;
// 에러. List<Object> -> List<String>
listStr = (List<Object>) listObj;이 특징이 문제되는 이유는 제네릭 객체에 요소를 넣거나 가져올때 캐스팅 문제로 인해 애로사항이 자주 발생하기 때문이다.
아래와 같이 배열을 이용한 코드는 반복문에 변수로 Object를 받아도 큰 문제가 없다.
public static void main(String[] args) {
Apple[] integers = new Apple[]{
new Apple(),
new Apple(),
new Apple(),
};
print(integers);
}
public static void print(Fruit[] arr) {
for (Object e : arr) {
System.out.println(e);
}
}print 메서드의 매개변수로 넘어갈 때 Apple[] 배열 타입이 Fruit[] 배열 타입으로 업캐스팅이 적용되어 문제가 없다.
하지만 아래와 같이 제네릭으로 바꾸면?
public static void main(String[] args) {
List<Integer> lists = new ArrayList<>(Arrays.asList(1, 2, 3));
print(lists); // ! 컴파일 에러 발생
}
public static void print(List<Object> list) {
for (Object e : list) {
System.out.println(e);
}
}제네릭의 경우 타입 파라미터가 오직 똑같은 타입만 받아야 하기 때문에 다형성을 이용할 수 없어서 생기는 문제이다.
그래서 제네릭 간의 형변환 성립을 위해 와일드 카드 문법이 나오게 되었다.
<?>: Unbounded Wildcards
타입 파라미터를 대치하는 타입으로 모든 클래스나 인터페이스 타입이 올 수 있다.
<? extends 상위타입>: Upper Bounded Wildcards
타입 파라미터를 대치하는 타입으로 상위 타입이나 상위 타입의 하위 타입만 올 수 있다.
<? extends 하위타입>: Lower Bounded Wildcards
타입 파라미터를 대치하는 타입으로 하위 타입이나 하위 타입의 상위 타입만 올 수 있다.
내용이 너무 길어지는 관계로, 제네릭 와일드 카드에 대한 설명은 Java Basics (+) Generic의 와일드 카드, 공변성/반공변성 를 참고하길 바란다.
22. Collection - List
프로그래밍을 하다 보면 가장 많이 겪게되는 문제가 데이터와 관련된 문제이다. 데이터를 어디에, 어떻게 저장하고, 꺼내고, 관리할 것인지에 대한 부분은 모든 컴공생들의 고민이다.
Collection은 자료구조를 도와주는 도구이며 Collection 인터페이스를 구현한 구현체는 java.util.package에 포함되어 있다. 해당 파트에서는 Collection의 List에 있는 대표적인 도구들을 소개하고자 한다.
순서가 있는 자료구조로 만들어진 경우 List 인터페이스를 구현한다.
List Interface를 구현한 클래스들은 ArrayList, LinkedList, Vector, Stack 등이 있다.
22-1. ArrayList<E>
ArrayList는 가변 배열이다. 내부 구현체는 배열을 이용하여 만들어졌으며 원리는 다음과 같다.
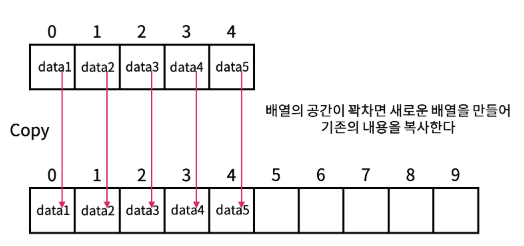
ArrayList 인스턴스가 생성되면 기본값(최초 10) 또는 사이즈에 맞게 배열을 생성한다. 이후 배열이 가득차게 되면 새로운 배열을 만들어서 기존 값을 Copy 하는 단순한 방식으로 이루어져 있다.
만약 ArrayList의 데이터를 삭제할 경우 아래와 같다.
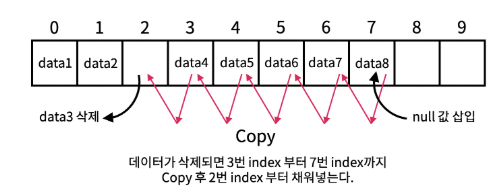
삭제된 데이터의 빈 자리를 다음 데이터가 쭉쭉 앞으로 땡겨와서 채우고 가장 마지막 인덱스에는 null이 저장된다.
import java.util.ArrayList;
ArrayList<String> texts = new ArrayList<>();
// 최초 공간 30으로 지정
ArrayList<String> texts = new ArrayList<>(30);
// ArrayList에 데이터 삽입
texts.add("딸기"); // index 0
texts.add("포도"); // index 1
texts.add("사과"); // index 2
// 논리적 공간의 크기
int size = texts.size();
// 크기 3
// 특정 index에 데이터 삽입
// set(index, 값);
texts.set(1, "포도");
// 특정 값에 접근
// get(index);
String text = texts.get(1);
// 포도전체 ArrayList의 크기는 10이라고 할지라도, 데이터가 할당된 논리적 공간의 크기는 3이다.
set(index, 값)과 get(index) 메서드를 사용할 때 주의해야할 점은 인덱스가 해당된 논리적 공간의 크기를 벗어날 수 없다.
예제 코드에서는 크기 3을 벗어난 인덱스 접근이 불가능하다는 말이다.
import java.util.ArrayList;
ArrayList<String> texts = new ArrayList<>();
// index 0
texts.add("딸기");
// index 1
texts.add("포도");
// index 2
texts.add("사과");
…
// 인덱스를 이용한 값 삭제
texts.remove(1);
// 값을 검색하여 값 삭제
texts.remove("포도");ArrayList는 배열기반이라 remove(index) 메서드의 삭제는 굉장히 빠르지만, remove(value) 메서드를 통해 저장된 값을 찾아 삭제한느 방식은 index가 0번부터 순차적으로 탐색해야하므로 효율이 나쁘다.
22-2. LinkedList<E>
LinkedList는 Node에 의해 데이터들이 연결되어 있는 리스트이다. 그래서 연결 리스트라고 불린다.
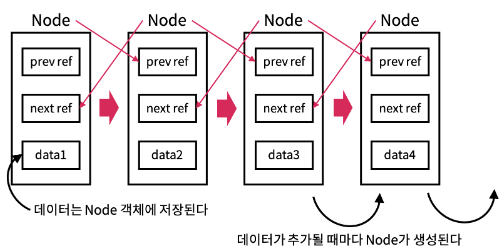
연결 리스트에 대한 개념은 자료구조와 관련된 내용이므로 자세한 설명은 생략하도록 하겠다.
import java.util.LinkedList;
LinkedList<String> texts = new LinkedList<>();
texts.add("딸기");
texts.add("포도");
texts.add("사과");
// 딸기 -> 포도 -> 사과
// 첫 번째 Node의 앞에 삽입
texts.addFirst("시작");
// 시작 -> 딸기 -> 포도 -> 사과
// 마지막 Node의 뒤에 삽입
texts.addLast("마지막");
// 시작 -> 딸기 -> 포도 -> 사과 -> 마지막add(value), addFirst(value), addLast(value) 메서드를 통해 값을 삽입할 수 있다.
import java.util.LinkedList;
LinkedList<String> texts = new LinkedList<>();
texts.add("딸기");
texts.add("포도");
texts.add("사과");
int size = texts.size();
// 크기 3ArrayList의 논리적 공간의 개념과 동일하다.
import java.util.LinkedList;
LinkedList<String> texts = new LinkedList<>();
texts.add("딸기");
texts.add("포도");
texts.add("사과");
…
// set(index, 값);
texts.set(1, "귤");
// 딸기 -> 귤 -> 사과
// add(index, 값);
texts.add(1, "중간!");
// 딸기 -> 중간! -> 귤 -> 사과
// get(index);
String text = texts.get(3);
// 사과set(index, value) 메서드를 통해 특정 인덱스에 값 변경이 가능하다.
add(index, value) 메서드를 통해 Node와 Node 사이에 삽입이 가능하다.
get(index) 메서드를 통해 특정 값을 가져오는 것이 가능하다.
set, add, get 메서드 역시 주의할 점은 논리적 공간을 벗어난 인덱스 접근은 불가능하다.
import java.util.LinkedList;
LinkedList<String> texts = new LinkedList<>();
// index 0
texts.add("1");
// index 1
texts.add("2");
// index 2
texts.add("3");
// index 3
texts.add("4");
…
// 인덱스를 이용한 값 삭제
texts.remove(1);
// 값을 검색하여 값 삭제
texts.remove("코드라떼");
// 맨 앞의 값을 삭제
texts.removeFirst();
// 맨 뒤의 값을 삭제
texts.removeLast();LinkedList의 remove(index) 메서드는 맨 앞 또는 맨 뒤 Node 중 접근하기 가장 가까운 Node에서 시작하여 삭제한다.
LinkdedList의 remove(value) 메서드는 index 0번부터 순차탐색을 통해 삭제한다.
23. Map
다른 언어에서는 Dictionary, Symbol Table 등이라고도 불리는 Map은 키(Key)와 값(Value)로 저장하는 자료구조이며, 정말 많이 사용한다.
| key | value |
|---|---|
| ABC | 김철수 |
| AAA | 보리밥 |
| BBB | 자바언어 |
자바의 Map은 인터페이스로 선언되어 있으며, 구현체로는 HashMap, TreeMap, LinkedHashMap이 있다.
23-1. HashMap<Key, Value>
Hash Table을 이용하여 만들어졌으며 간략하게 Hash Table이 뭔지 알아보자.
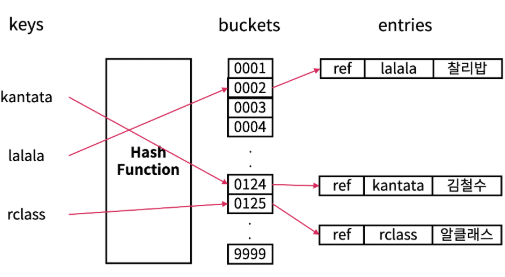
Hash Table은 key, value를 저장하며 key를 이용하여 빠르게 데이터를 찾기 위한 자료구조를 가지고 있다.
- 특정 key는 해시함수를 통해 bucket에 접근할 수 있는 index로 변환된다.
- index를 이용하여 bucket에 접근한다.
- bucket에 맞는 index에 key와 value를 저장한다.
Hash Table은 key를 index로 변경하여 데이터를 접근한다고 보면 된다.
import java.util.HashMap;
// String key, String value
HashMap<String, String> map = new HashMap<>();
// 데이터 삽입
map.put("codelatte", "코드라떼");
map.put("kantata", "김철수");
map.put("cafe", "카페");
String value1 = map.get("codelatte");
// "코드라떼"
String value2 = map.get("cafe");
// "카페"
String value3 = map.getOrDefault("coffee", "커피");
// hashmap에 "coffee" 키가 존재하지 않을 경우 "커피"를 반환한다.put(key, value) 메서드를 통해 데이터를 저장하고, get(key) 메서드를 통해 값에 접근한다.
import java.util.HashMap;
// String key, String value
HashMap<String, String> map = new HashMap<>();
// 데이터 삽입
map.put("codelatte", "코드라떼");
map.put("kantata", "김철수");
map.put("cafe", "카페");
// key 값을 이용하여 삭제
map.remove(“kantata”);
// key 값을 출력
for (String key : map.keySet()) {
System.out.println(key);
}
// value 값을 출력
for (String value : map.values()) {
System.out.println(value);
}remove(key) 메서드를 이용하여 저장된 값을 삭제할 수 있고, keySet() 메서드를 통해 key 값 출력이 가능하다.
values() 메서드를 통해 value 값을 출력할 수 있다.
각 key에 해당하는 value들은 순서가 없어 이를 출력할 경우 정렬되어있지 않다.
HashMap의 key로 Object를 사용할 시 주의점
class Address {
private String city;
private String street;
public Address(String city, String street) {
this.city = city;
this.street = street;
}
}
import java.util.HashMap;
// String key, String value
HashMap<Address, String> map = new HashMap<>();
// 데이터 삽입
map.put(new Address("서울시", "강남서로 20"), "서울시 강남서로 20");
map.put(new Address("서울시", "강남서로 20"), "서울시 강남서로 20");
System.out.println(map);
// Address@610455d6=서울시 강남서로 20, Address@511d50c0=서울시 강남서로 20의미상으로는 동일한 객체로 보일 수 있어도 서로 다른 인스턴스이므로 Hashcode 역시 다르다. 따라서 두 객체 모두 HashMap에 저장된다.
만약 같은 의미의 객체로 만들고 싶으면 Object.equals() 메서드와 Object.hashCode() 메서드를 재정의해야한다.
23-2. TreeMap<Key, Value>
TreeMap은 Red-Black Tree를 이용하여 만들어졌으며 이에 대해 간략하게 알아보자.
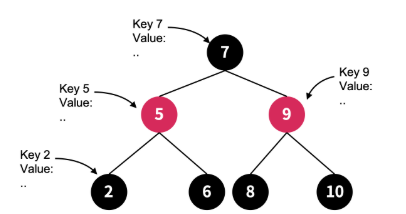
각 Node에는 key와 value가 같이 저장되며, key 값을 기준으로 좌측 우측으로 구분하여 저장한다.
예를 들어 5라는 key를 가진 Node를 기준으로 잡으면, 5보다 작은 key인 2는 좌측 자식 Node, 큰 key인 6은 우측 자식 Node로 저장되어 연결된다.
Red-Black Tree는 새로운 데이터가 저장되거나 삭제될때마다 위의 규칙에 맞춰 Node의 위치를 재배치한다.
import java.util.TreeMap;
// String key, String value
TreeMap<String, String> map = new TreeMap<>();
// 데이터 삽입
map.put("codelatte", "코드라떼");
map.put("kantata", "김철수");
map.put("cafe", "카페");
String value1 = map.get("codelatte");
// "코드라떼"
String value2 = map.get("cafe");
// "카페"
String value3 = map.getOrDefault("coffee", "커피");
// treemap에 "coffee" 키가 존재하지 않을 경우 "커피"를 반환한다.
// key 값을 이용하여 삭제
map.remove(“kantata”);put, get, getOrDefault, remove 메서드는 HashMap과 동일하니 생략하도록 하겠다.
import java.util.TreeMap;
// String key, String value
TreeMap<String, String> map = new TreeMap<>();
// 데이터 삽입
map.put("2", "2");
map.put("3", "3");
map.put("1", "1");
map.put("4", "4");
// key 값을 출력
for (String key : map.keySet()) {
System.out.println(key);
}
// "1", "2", "3", "4"
// value 값을 출력
for (String value : map.values()) {
System.out.println(value);
}
// "1", "2", "3", "4"TreeMap은 HashMap과 달리 Node 간의 순서가 존재하므로 오름차순으로 정렬된 상태로 출력된다.
23-3. LinkedHashMap<Key, Value>
LinkedHashMap은 HashMap을 상속하여 만들어졌다. HashMap과 다른 점은 Node 객체를 Entry 객체로 감싸서 저장된 키의 순서를 보존한다는 점이다.
import java.util.LinkedHashMap;
// String key, String value
LinkedHashMap<String, String> map = new LinkedHashMap<>();
// 데이터 삽입
map.put("2", "2");
map.put("3", "3");
map.put("1", "1");
map.put("4", "4");
// key 값을 출력
for (String key : map.keySet()) {
System.out.println(key);
}
// "2", "3", "1", "4"
// value 값을 출력
for (String value : map.values()) {
System.out.println(value);
}
// "2", "3", "1", "4"key 값이 저장된 순서로 출력하는 것을 볼 수 있다.
24. Collection - Set
집합(Set)이란 중복되지 않는 원소들의 모음을 만들 수 있는 자료구조이다.
Set 인터페이스의 구현체에는 TreeSet, HashSet, LinkedHashSet이 있다.
24-1. HashSet<E>
HashSet은 데이터 저장을 Hash Table을 이용하는 자료구조로 저장하는 Set이다.
// HashSet의 생성자
public HashSet() {
map = new HashMap<>();
}
public HashSet(Collection<? extends E> c) {
map = new HashMap<>(Math.max((int) (c.size() / 0.75f) + 1, 16));
}
...
// 더미 Object
public static final Object PRESENT = new Object();
// HashSet의 데이터 add 메서드
public boolean add(E e) {
return map.put(e, PRESENT) == null;
}HashSet의 생성자를 보면 HashMap을 이용하여 Set 구조를 만드는 것을 알 수 있다.
Map의 특성인 중복 key는 존재할 수 없다는 점을 이용하여 key를 Set의 값으로, 더미 Object를 저장 방식으로 데이터를 추가한다.
따라서 index가 아닌 key를 이용하여 데이터 저장과 접근이 필요한 경우 많이 사용한다.
import java.util.HashSet;
// String value
HashSet<String> set = new HashSet<>();
// 데이터 삽입
set.add("코드라떼");
set.add("codelatte");
boolean isExist = set.contains("codelatte");
// 있으면 true, 없으면 false
// 데이터 삭제
set.remove("카페라떼");add, contains, remove 메서드를 통해 삽입, 존재유무, 삭제 기능이 가능하다.
import java.util.HashSet;
// String value
HashSet<String> set = new HashSet<>();
// 데이터 삽입
set.add("1");
set.add("23");
set.add("2");
set.add("14");
set.add("2");
set.add("5");
for (String value : set) {
System.out.println(value);
}
// "1", "23", "2", "14", "5"HashMap을 이용하여 만들었으니 저장된 값은 정렬되어 있지 않다.
24-2. TreeSet<E>
사실 이쯤되면 독자들은 예측도 가능할거 같다. TreeSet은 TreeMap을 이용하여 만들었다.
// TreeSet의 생성자
public TreeSet() {
this(new TreeMap<E, Object>());
}
…
// 더미 Object
public static final Object PRESENT = new Object();
// TreeSet의 데이터 add 메서드
public boolean add(E e) {
return m.put(e, PRESENT) == null;
}HashSet과 동일하게 중복 key가 존재할 수 없다는 특성을 이용하여 만들었다.
import java.util.TreeSet;
// String value
TreeSet<String> set = new TreeSet<>();
// 데이터 삽입
set.add("1");
set.add("3");
set.add("2");
set.add("4");
set.add("2");
set.add("5");
for (String value : set) {
System.out.println(value);
}
// "1", "2", "3", "4", "5"다른 부분은 HashSet과 동일하니 생략하고, TreeSet은 TreeMap을 이용하여 만들었으므로 저장된 값은 오름차순으로 정렬되어 출력한다.
24-3. LinkedHashSet<E>
LinkedHashSet은 HashSet을 상속하여 만들어졌다.
// LinkedHashSet은 HashSet을 상속 받는다
public LinkedHashSet<E> extends HashSet<E> …
// LinkedHashSet의 생성자
public LinkedHashSet() {
super(16, .75f, true);
}다른 부분은 HashSet과 동일하니 생략하도록 하고 이 역시 값이 저장되는 순서가 다르다.
import java.util.LinkedHashSet;
// String value
LinkedHashSet<String> set = new LinkedHashSet<>();
// 데이터 삽입
set.add("1");
set.add("23");
set.add("3");
set.add("14");
set.add("2");
set.add("5");
for (String value : set) {
System.out.println(value);
}
// "1", "23", "3", "14", "2", "5"key 값이 저장된 순서로 출력하는 것을 볼 수 있다.
25. Stack & Queue
Collection 도구에는 Stack, Queue 자료구조를 사용할 수 있도록 만들어진 클래스가 존재한다.
Stack은 나중에 들어간 데이터가 먼저 나오는 LIFO 구조를 가지고 있다.
Queue는 먼저 들어간 데이터가 먼저 나오는 FIFO 구조를 가지고 있다.
Stack, Queue 자료구조에 대한 설명을 하는 게시물은 아니니 개념은 생략하도록 하고, 사용 방법에 초점을 두어 작성하겠다.
25-1. Stack<E>
Stack은 Vector 클래스를 상속하여 만들어졌다. Vector 클래스는 ArrayList와 유사하나 Thread 동기화를 위해 synchronized 키워드가 선언되어 있다.
import java.util.Stack;
Stack<String> stack = new Stack<>();
stack.push("강의A");
stack.push("강의E");
stack.push("강의B");
stack.push("강의D");
stack.push("강의C");
String lessonName1 = stack.pop();
// 강의C
String lessonName2 = stack.pop();
// 강의D
String lessonName3 = stack.pop();
// 강의B
String lessonName1 = stack.peek();
// 강의 Epush, pop 메서드를 통해 데이터를 삽입하고 꺼낼 수 있다.
peel 메서드를 통해 최상단 데이터를 확인할 수 있다.
import java.util.Stack;
Stack<String> stack = new Stack<>();
stack.push("강의A");
stack.push("강의E");
stack.push("강의B");
stack.push("강의D");
stack.push("강의C");
int sequence1 = stack.search("강의A");
// 5
int sequence2 = stack.search("강의E");
// 4
int sequence3 = stack.search("강의B");
// 3
int sequence4 = stack.search("강의D");
// 2
int sequence5 = stack.search("강의C");
// 1
int search = stack.search("강의Z");
// -1search 메서드를 통해 데이터를 확인하고 순서를 파악할 수 있다. 만약 데이터가 없는 경우 -1을 반환한다.
import java.util.Stack;
Stack<String> stack = new Stack<>();
stack.push("강의A");
stack.push("강의E");
stack.push("강의B");
stack.push("강의D");
stack.push("강의C");
int size = stack.size();
// 5
while (!stack.isEmpty()) {
System.out.println(stack.pop());
}size 메서드를 통해 크기를 확인할 수 있고, isEmpty 메서드를 통해 데이터 존재 유무를 판단할 수 있다.
25-2. Queue<E> - Interface
Queue 인터페이스를 구현한 클래스는 LinkedList, ArrayDeque가 있다.
import java.util.Queue;
import java.util.LinkedList;
import java.util.ArrayDeque;
// LinkedList를 이용한 Queue
Queue<E> queue = new LinkedList<>();
// ArrayDeque를 이용한 Queue
Queue<E> queue = new ArrayDeque<>();LinkedList는 가장 앞이나 뒤의 데이터를 삭제하기 쉽고, Queue에서 데이터를 꺼낼 때도 가장 앞의 데이터를 꺼내는 것에 부합하므로 추천한다.
ArrayDeque는 배열을 이용하여 만든 Queue이다.
import java.util.Queue;
import java.util.LinkedList;
Queue<String> queue = new LinkedList<>();
queue.add("전화A");
queue.add("전화E");
queue.add("전화B");
queue.add("전화D");
queue.add("전화C");
String data1 = queue.poll();
// 전화A
String data2 = queue.poll();
// 전화E
String data3 = queue.poll();
// 전화B
String data1 = queue.peek();
// 전화Dadd 메서드를 통해 데이터를 삽입하고, poll 메서드를 통해 데이터를 꺼낸다.
peek 메서드를 통해 맨 앞의 데이터를 확인할 수 있다.
import java.util.Queue;
import java.util.LinkedList;
Queue<String> queue = new LinkedList<>();
queue.add("전화A");
queue.add("전화E");
queue.add("전화B");
queue.add("전화D");
queue.add("전화C");
int size = queue.size();
// 5
boolean isEmpty = queue.isEmpty();Stack과 동일하게 size 메서드를 통해 크기를 반환하고, isEmpty 메서드를 통해 데이터 존재 유무를 판단할 수 있다.
26. Wrapper
자바에는 기본 자료형을 감싸는 Wrapper 클래스가 있다.
이미 예제코드에서는 간간히 나와서 봤을거라고 생각한다.
List<Object> list = new ArrayList<>();
list.add(object);ArrayList의 list.add(object) 메서드는 Object 인스턴스를 상속받는 인스턴스의 참조 값만 전잘할 수 있다.
이와 같이 기본 자료형도 특정 목적에 의해 인스턴스로 바꿔서 사용해야하는 경우가 있다.
(제네릭과 함께 사용하는 경우에는 거의 항상 쓴다.)
따라서 아래와 같이 상수 값을 인스턴스화하여 전달한다.
Integer integer = new Integer(10);아래는 기본 자료형과 매칭되는 클래스들이다.
// 상수 값을 인스턴스화
// byte
Byte bt = new Byte(1);
// short
Short sho = new Short(10);
// int
Integer integer = new Integer(10);
// long
Long long = new Long(10L);
// float
Float flo = new Float(10.2F);
// double
Double dou = new Double(10.2);
// boolean
Boolean bool = new Boolean(true);
// char
Character character = new Character('A');이런 클래스들을 기본 자료형의 Wrapper 클래스라고 부른다.
// Integer로 명시
List<Integer> list = new ArrayList<>();
// list에 값 저장
list.add(new Integer(10));
list.add(new Integer(20));
list.add(new Integer(30));이렇게 int 대신 Integer로 감싸서 전달해주면 참조 자료형만 전달해줘야하는 문제를 해결할 수 있다.
반대로 참조 자료형에서 기본 자료형으로 반환받기 위해서는 아래와 같이 사용한다.
Byte bt = new Byte((byte) 0);
byte bt1 = bt.byteValue();
Short sho = new Short((short) 10);
short sho1 = sho.shortValue();
Integer integer = new Integer(10);
int integer1 = integer.intValue();
Long lo = new Long(10L);
long lo1 = lo.longValue();
Float fl = new Float(10.2F);
float fl1 = fl.floatValue();
Double dou = new Double(10.2);
double dou1 = dou.doubleValue();
Character character = new Character('A');
char character1 = character.charValue();
Boolean bool = new Boolean(true);
boolean bool1 = bool.booleanValue();xxxValue() 메서드를 호출하면 기본 자료형 값을 반환받을 수 있다.
26-1. Auto Boxing, Auto UnBoxing
위와 같이 매번 new 구문을 이용하여 값을 저장하는 것은 번거롭고 코드를 작성하는 시간도 오래 걸린다.
그래서 아래와 같이 Auto Boxing, Auto UnBoxing 방식이 도입되었다.
Integer integer = 1;이렇게 작성해도 내부적으로 인스턴스로 변환 가능하도록 만들어준다.
1이라는 상수가 Auto Boxing을 통해 new Integer(1) 인스턴스가 자동으로 생성되고 참조 자료형 변수에 저장된다.
Integer integer = 10;
int integer1 = integer;반대로 Auto UnBoxing을 통해 참조 자료형에서 기본 자료형으로 쉽게 변환할 수 있다. 굳이 xxxValue() 메서드를 호출하지 않아도 되는 것이다.
26-2. Number
Number 클래스는 Byte, Short, Integer, Long, Float, Double 같은 Wrapper 클래스의 슈퍼 클래스이다.
Number 클래스는 추상 클래스이지만 Auto Boxing이 적용된다.
Number number1 = 1;
Number number2 = 2.0;다만 Auto UnBoxing은 불가능하다.
Number number1 = 1;
Number number2 = 2.0;
// 명시적 변환이 필요
double sum = number1.doubleValue() + number2.doubleValue();Number 변수에 인스턴스를 이미 저장된 후에는 참조 값만 저장하므로 Byte, Short, Integer, Long 정수인지 Float, Double 실수인지 판단할 수 없기 때문이다.
따라서 xxxValue() 메서드를 사용한 명시적 형 변환이 필요하다.
26-3. ParseXXX(string), toString(xxx)
String numberText = "1";
// 문자열 -> 정수
int number = Integer.parseInt(numberText);
// 정수 - > 문자열
String text = Integer.toString(number);Integer.ParseInt(string) 정적 메서드를 통해 int 정수형으로 변환할 수 있다.
또한 Integer.toString(int) 정적 메서드를 통해 문자열로 변환할 수 있다.
String numberText = "1";
// 문자열 -> 정수
byte number = Byte.parseByte(numberText);
// 정수 - > 문자열
String text = Byte.toString(number);이 외에도 Byte.parseByte(string), Byte.toString(byte)도 적용할 수 있다.
정리하면 parseXXX(string), toString(xxx) 형식으로 다른 자료형에도 똑같이 적용할 수 있으니 유용하게 사용하도록 하자.
27. Deque
Double Ended Queue의 줄임말로 큐의 양쪽에서 삽입과 삭제가 가능한 자료구조이다. 스택과 큐는 기본이고, 덱 역시 코딩테스트에서 정말 많이 사용하니 숙지해놓도록 하자.
양방향으로 값의 삽입과 삭제가 가능하므로 스택과 큐의 원리를 모두 적용한 구조라고 보면 된다.
먼저 값을 삽입하는 메서드는 다음과 같다.
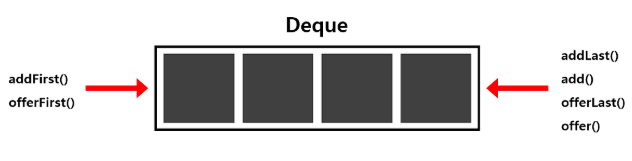
- add(), addLast(): 마지막에 원소 삽입
- addFirst(), offerFirst(): 맨 앞에 원소 삽입
※ offer로 시작하는 메서드는 성공 시 true, 실패 시 false를 반환함
Deque에 값을 삭제하는 메서드는 다음과 같다.
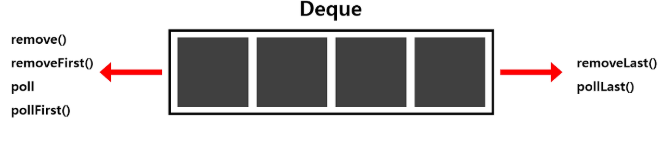
-
remove(), removeFirst(), poll(), pollFirst(): 맨 앞의 원소 제거 후 해당 원소를 리턴
-
removeLast(), pollLast(): 마지막 원소 제거 후 해당 원소 리턴
※ poll로 시작하는 메서드는 덱이 비어있는 경우 null 리턴
다음은 원소를 확인하는 메서드이다.
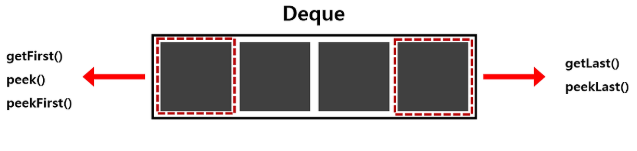
- getFirst(), peek(), peekFirst(): 맨 앞의 원소를 리턴
- getLast(), peekLast(): 마지막 원소를 리턴
※ peek으로 시작하는 메서드는 덱이 비어잇는 경우 null 리턴
