처음에는 막연하게 Python으로 코딩테스트를 준비해 왔는데... 생각해보니 백엔드 취업을 희망하는 사람으로서 Spring Boot 프레임워크를 주력으로 공부하고 있다.
그래서 주력 언어도 Java로 맞추는게 좋을 거 같아서 지금부터는 Java로 코테 시험을 준비하고자 한다.
해당 포스팅에서 설명할 자바 문법은 코딩테스트에서 주로 사용하는 것들을 위주로 설명할 예정이다.
따라서 문법에 대해 깊은 이해를 원하시는 분들은 다른 포스팅을 보거나 제가 작성한 Java Basics: https://velog.io/@wonotter/series/Java-Basics 시리즈를 보셔도 좋을 것 같다.
그럼 시작하도록 하겠다.
Primitive Type, Reference Type
자바에는 int, long, float, double과 같은 primitive type과 Integer, Long, Float, Double과 같은 Reference Type이 있다. 문법에 대해 공부한 사람들은 알겠지만 레퍼런스 타입은 참조형 변수이므로 프리미티브 타입보다 연산 속도가 더 느리다.
따라서 특별한 경우가 아니라면 대부분 프리미티브 타입을 사용할 것을 권한다.
정수형
간단한 내용이니 잘 안다고 가정하고 코드만 작성하겠다.
정수형 변수 선언
int a = 13;
int b = 4;정수형 산술 연산
System.out.println(a + b); // 13
System.out.println(a - b); // 9
System.out.println(a * b); // 52
System.out.println(a / b); // 3
System.out.println(a % b); // 1정수형 비교 연산
System.out.println(a == b); // false
System.out.println(a != b); // true
System.out.println(a > b); // true
System.out.println(a < b); // false
System.out.println(a >= b); // true
System.out.println(a <= b); // false정수형 비트 연산
System.out.println(a & b); // AND, 4
System.out.println(a | b); // OR, 13
System.out.println(a ^ b); // XOR, 9
System.out.println(~a); // NOT, -14
System.out.println(a << 2); // 왼쪽 시프트, a에 2^2를 곱한 것과 동일, 52
System.out.println(a >> 1); // 오른쪽 시프트, a를 2^1로 나눈 것과 동일, 6부동소수형
부동소수형은 소수를 저장할 때 사용한다.
사칙연산과 모듈러 연산
System.out.println(2.5 + 3.7); // 6.2
System.out.println(7.9 - 4.2); // 3.7
System.out.println(1.5 * 4.8); // 7.19999...
System.out.println(10.0 / 3.2); // 3.125
System.out.println(10.0 % 3.2); // 0.39999...여기서 한가지 주의할 점은 나머지 연산을 수행하는 모듈러 연산의 결괏값이 0.4가 아니라 0.3999... 임을 확인할 수 있다.
이렇게 작은 오차가 발생하는 이유는 자바의 경우 부동소수형 데이터를 이진법으로 표현하기 때문이다. 이를 앱실론이라고 한다. 이 내용을 말하는 이유는 이 작은 수인 앱실론 때문에 문제 통과가 안되는 안타까운 상황을 방지하기 위함이다...
부동소수형 논리 연산
double x = 0.5;
double y = 1.2;
double z = 2.0;
System.out.println(x > y && y < z); // AND 연산, false
System.out.println(x > y || y < z); // OR 연산, true
System.out.println(!(x > y)); // NOT 연산, trueCollection Framework
컬렉션 프레임워크는 여러 개의 값을 저장하고 그 값을 쉬우면서도 효율적으로 처리해주는 표준화 클래스의 집합이다.
우리가 코딩테스트 문제를 해결하기 위해 다양한 자료구조인 리스트, 큐, 스택, 해시맵 등을 직접 구현하지 않아도 손쉽게 제공해주는 집합이라고 생각하면 된다.
본격적으로 프레임워크에 대해 알아보기 전에, ArrayList와 비교를 위해 단순 배열에 대해 먼저 설명하겠다.
배열
배열은 기초 자료형으로 저장할 데이터의 개수가 정해져 있을 때 사용하기에 유용하다.
참고로 Array 클래스의 toString() 메서드를 사용하면 배열의 모든 요소를 쉽게 출력할 수 있으니 디버깅하기에 용이하다.
import java.util.Arrays;
public class Solution {
public static void main(String[] args) {
int[] array = { 1, 2, 3, 4, 5 };
int[] array2 = new int[] { 1, 2, 3, 4, 5};
int[] array3 = new int[5];
array3[0] = 0;
array3[1] = 2;
array3[2] = 4;
array3[3] = 6;
array3[4] = 8;
System.out.println(Arrays.toString(array)); // [1, 2, 3, 4, 5]
System.out.println(Arrays.toString(array2)); // [1, 3, 5, 7, 9]
System.out.println(Arrays.toString(array3)); // [0, 2, 4, 6, 8]
}
}다들 잘 알다시피 배열은 array3[0]과 같이 인덱스를 통해 특정 원소 위치에 빠르게 접근한다. 또한 배열은 생성 이후에는 크기를 변경할 수 없다.
따라서 배열 생성 후 새 데이터를 삽입하거나 삭제하는 기능은 기본적으로 불가능하며, 기존 데이터의 변경만 가능하다.
인덱스를 이용한 배열 요소에 대한 접근, 변경의 시간복잡도는 이다.
ArrayList
자바의 리스트는 일반적으로 ArrayList를 의미한다. ArrayList는 배열과 다르게 크기가 고정되어 있지 않아 데이터의 삽입, 삭제와 같은 연산이 가능하다.
다만 새 데이터를 맨 뒤에 추가할 때는 , 기존 데이터의 삭제 or 데이터를 중간에 삽입하는 경우 까지 커질 수 있으므로 주의해야한다.
// 리스트 객체 생성
ArrayList<Integer> list = new ArrayList<>();
// 값 추가
list.add(1);
list.add(2);
list.add(4);
list.add(6);
System.out.println(list.get(2)); // 인덱스로 값에 접근
System.out.println(list); // [1, 2, 4, 6]add() 메서드로 데이터 추가
맨 끝에 데이터를 추가하려면 add()를 사용하면 된다.
ArrayList<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);다른 컬렉션의 데이터로부터 초기화
ArrayList의 생성자의 매개변수로 컬렉션을 넘기면 컬렉션에 담긴 데이터로 초기화가 가능하다.
ArrayList<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
ArrayList<Integer> list2 = new ArrayList<>(list);
System.out.println(list2); // [1, 2, 3]get() 메서드로 인덱스를 통해 데이터 접근
특정 인덱스에 있는 데이터에 접근하기 위해 get() 메서드를 사용한다.
ArrayList<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
System.out.println(list.get(1)); // 2remove() 메서드로 데이터 삭제
remove() 메서드를 사용하면 특정 위치의 데이터를 삭제할 수 있다.
ArrayList<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
list.remove(list.size() - 1); // 끝 데이터 삭제
System.out.println(list); // [1, 2]ArrayList 연관 메서드
위에 설명한 메서드 외에 코딩테스트에 자주 등장하는 메서드들을 소개하겠다.
// 배열 전체 데이터 개수 반환
int[] arr = {1, 2, 4, 5, 3};
System.out.println(arr.length); // 5
// 배열의 모든 데이터를 정렬하는 Arrays의 sort()
Arrays.sort(arr); // [1, 2, 3, 4, 5]
System.out.println(Arrays.toString(arr));
ArrayList<Integer> list = new ArrayList<>(Arrays.asList(1, 2, 4, 5, 3));
// ArrayList의 전체 데이터 개수 반환
System.out.println(list.size()); // 5
// ArrayList의 저장된 데이터 유무
System.out.println(list.isEmpty()); // false
// ArrayList의 모든 데이터 정렬하는 Collections의 sort()
Collections.sort(list); // [1, 2, 3, 4, 5]
System.out.println(list);HashMap
해시맵은 키와 값(key와 value) 쌍을 저장하는 해시 테이브로 구현되어 있다. 키를 사용하여 값을 검색하는 자료구조이다.
다음은 key를 String, value를 32비트 정수형을 저장하는 해시맵을 선언한 모습이다.
HashMap<String, Integer> map = new HashMap<>();다음은 해시맵의 데이터 삽입과 출력하는 모습이다.
// 해시맵 값 설정
map.put("apple", 1);
map.put("banana", 2);
map.put("orange", 3);
// 해시맵 값 출력
System.out.println(map); // {banana=2, orange=3, apple=1}다음은 해시맵에 "apple" 문자열과 일치하는 키가 있는지 확인하고 일치하는 키를 찾으면 key-value 값을 출력한다.
String key = "apple";
if (map.containsKey(key)) {
int value = map.get(key);
System.out.println(key + ": " + value); // apple: 1
} else {
Sytem.out.println(key + "는 해시맵에 없습니다.");
}다음은 키 "banana"를 검색하여 해당 키의 값을 4로 바꾼다.
map.put("banana", 4);
System.out.println(map); // {banana=4, orange=3, apple=1}다음은 키 "orange"를 찾아 해시맵에서 삭제한다.
map.remove("orange");
System.out.println(map); // {banana=4, apple=1}문자열
문자열은 문자들을 배열의 형태로 구성한 Immutable(이뮤터블) 객체이다.
자바에서 문자열은 이뮤터블 객체로, 값을 변경할 수 없는 객체이다. 문자열은 큰따옴표로 감싸 사용한다.
String string = "Hello, World!";다음은 문자열을 추가하고 삭제하는 동작이다. 여기서 주목해야할 점은 이뮤터블 객체이므로 기존 객체를 수정하는 것이 아니라, 새로운 객체를 반환한다는 사실이다.
Stirng string = "He";
string += "llo";
System.out.println(string); // "Hello"문자열에서 +=와 같이 연산을 진행하게 되면, "He"와 "llo"를 합쳐 새로운 문자열인 "Hello"를 만들고 string은 새로운 문자열인 "Hello"를 참조한다는 것이다.
그렇다면 기존 문자열을 수정하고 싶다면 어떻게 해야할까?
이런 경우 사용하는 메서드가 replace() 메서드이다.
String string = "Hello";
string = string.replace("l", ""); // "l"을 모두 삭제
System.out.println(string); // "Heo"StringBuffer, StringBuilder
앞에 언급했듯이 자바에서 String 객체는 값을 변경할 수 없는 Immutable 객체이다.
아래 코드를 보자.
String s = "abc";
// 123456
System.out.println(System.identityHashCode(s));
s += "def";
// 678910
System.out.println(System.identityHashCode(s));
System.out.println(s); // abcdefSystem.identityHashCode() 메서드는 객체를 특정할 수 있는 식별값을 의미한다. 위의 설명대로 "abc"에서 "def"를 이어붙인 "abcdef"는 다른 객체이므로 다른 식별값이 출력된다.
위의 연산 과정을 표현하면 아래와 같다.
- 새로운 String s 객체 생성
- s가 가진 "abc" 값을 하나씩 복사
- "abc" 뒤에 "def" 저장
따라서 문자열의 길이를 N이라고 하면 의 시간복잡도가 걸린다.
아래 코드의 경우 단순히 문자열을 더하는 것임에도 불구하고 최소 10초 넘게 시간이 소요되는 문제점이 있다.
long start = System.currentTimeMillis();
String s = "";
for (int i = 1; i <= 1000000; i++) {
s += i;
}
long end = System.currentTimeMillis();
System.out.println(((end - start) / 1000.0) + "초");이러한 문제를 해결하기 위해 StringBuilder, StringBuffer 클래스가 나오게 되었다.
StringBuilder와 StringBuffer는 Mutable(뮤터블)하므로 값을 변경할 때 시간복잡도 관점에서 훨씬 효율적이며, 코딩테스트에서도 String 대신 StringBuilder 클래스를 사용한다.
long start = System.currentTimeMillis();
StringBuilder s = new StringBuilder();
for (int i = 1; i <= 1000000; i++) {
s.append(i);
}
long end = System.currentTimeMillis();
System.out.println(((end - start) / 1000.0) + "초");참고로 StringBuilder와 StringBuffer의 차이는 Thread-Safe 유무로 나뉜다. 하지만 대부분 코테에서는 멀티스레드를 생성할 일이 없으므로 String 대신 StringBuilder만 사용할 것을 기억하면 된다.
StringBuilder의 주요 메서드는 다음과 같다.
// StringBuilder 객체 생성
StringBuilder sb = new StringBuilder();
// 문자열 Add
sb.append(10);
sb.append("ABC");
// 출력
System.out.println(sb); // 10ABC
sb.delete(3); // 3번째 인덱스 문자 삭제
System.out.println(sb); // 10AC
sb.insert(1, 2); // 1번째 인덱스에 2라는 문자 추가
System.out.println(sb); //120AC람다식
람다식(lambda expression)은 JDK 1.8 버전에서 추가되었다. 익명 함수라고도 하며, 코드에서 딱 한번 실행할 목적으로 사용하거나 간결하게 표현하고 싶을 때 사용한다.
기존에 익명 클래스 방식을 사용해서 구현하였던 방식을, 람다식을 통해 더욱 간결하게 바꿀 수 있는 것이다.
코드 구조는 아래와 같다.
// 익명 객체를 사용한 구현방법
타입명 변수명 = new 타입명() {
@Override
public int 메서드명(타입명 o1, 타입명 o2) {
return o1.필드명 - o2.필드명;
}
};
// 람다식을 사용한 구현방법
타입명 변수명 = (o1, o2) -> o1.필드명 - o2.필드명;람다식은 매개변수 타입명과 오버라이딩할 메서드명을 모두 제외하고 ->을 기준으로 왼쪽 부분인 (매개변수1, 매개변수2, ...)와 같이 대입하고 오른쪽 부분에는 return 할 내용을 적어주면 된다.
다만 아래와 같이 return할 경우가 2개 이상이거나, 단일 실행문이 아니고 별도의 계산이 필요한 경우 {}와 함께 return을 작성해 주어야 한다.
PriorityQueue<Integer> queue = new PriorityQueue<>((o1, o2) -> {
int first_abs = Math.abs(o1);
int second_abs = Math.abs(o2);
if (first_abs == second_abs)
return o1 > o2 ? 1 : -1;
else
return first_abs - second_abs;
});우선순위 큐에 특정 순서를 임의로 지정하여 다시 정렬할 수 있도록 작성하는 경우이다. 코테에서 자주 사용하니 함께 숙지해 놓도록 하자.
람다식에 대한 감을 확실히 잡기 위해 한 가지 예제를 더 살펴보도록 하자.
만약 아래와 같이 Node 클래스를 선언한 후
public class Node {
int dest, cost;
public Node(int dest, int cost) {
this.dest = dest;
this.cost = cost;
}
}노드에 값을 넣은 다음 정렬하는 경우를 가정해보자. 이때 람다식과 익명 클래스로 오버라이드 한 코드 모두 동일한 로직을 수행한다. 하지만 아무래도 코드 가독성 측면에서 람다식이 훨씬 보기 좋아보인다.
import java.util.Arrays;
import java.util.Comparator;
public class Main {
public static void main(String[] args) {
Node[] nodes = new Node[5];
nodes[0] = new Node(1, 10);
nodes[1] = new Node(2, 20);
nodes[2] = new Node(3, 15);
nodes[3] = new Node(4, 5);
nodes[4] = new Node(1, 25);
// 람다식 표현
Arrays.sort(nodes, (o1, o2) -> Integer.compare(o1.cost, o2.cost));
// 익명 클래스로 오버라이드
Arrays.sort(nodes, new Comparator<Node>() {
@Override
public int compare(Node o1, Node o2) {
return Integer.compare(o1.dest, o2.dest);
}
});
}
}더블콜론
자바 8에서 도입된 연산자로 메서드 참조 연산자라고도 부른다. 위에서 설명한 람다식과 동일한 역할을 하지만, 람다식과 다르게 매개변수를 작성하지 않는다는 차이점이 있다.
// lambda
(a, b) -> Classname.methodName(a, b);
// double colon
className::methodName더블콜론은 크게 아래와 같이 4가지 경우에 사용한다.
- static 메서드 참조
// 람다 표현식 사용
Function<String, Integer> lambda = s -> Integer.parseInt(s);
// 메서드 참조 사용
Function<String, Integer> methodref = Integer::parseInt;- instance 메서드 참조
Main obj = new Main();
// 람다 표현식 사용
Consumer<String> lambdaConsumer = s -> obj.printMessage(s);
// 메서드 참조 사용
Consumer<String> methodReference = obj::printMessage;- 특정 객체의 임의 메서드 참조
List<String> names = Arrays.asList("Alice", "Bob", "Charlie");
// 람다 표현식 사용
names.forEach(name -> System.out.println(name));
// 메서드 참조 사용
names.forEach(System.out::println);- 생성자 참조
class Person {
String name;
Person() {
this.name = "Unknown";
}
}
...
// 람다 표현식 사용
Supplier<Person> lambdaSupplier = () -> new Person();
// 생성자 참조 사용
Supplier<Person> constructorReference = Person::new;처음에는 일반적인 메서드 호출, 람다식, 메서드 참조 연산이 헷갈릴 것이다. 그래서 아래 코드를 기준으로 차이점을 생각해보자.
import java.util.Arrays;
import java.util.List;
public class Main {
public static void main(String[] args) {
List<String> names = Arrays.asList("Alice", "Bob", "Charlie");
// names의 요소를 리스트 형태로 출력
System.out.println(names);
// [Alice, Bob, Charlie]
// 람다 표현식 사용
names.forEach(name -> System.out.println(name));
// Alice
// Bob
// Charlie
// 메서드 참조 사용
names.forEach(System.out::println);
// Alice
// Bob
// Charlie
}
}셋 다 언뜻보면 비슷해보이지만 기능이 조금씩 다르므로 확실히 숙지해 놓자.
스트림(Stream)
Java Stream은 자바 8부터 추가된 기능으로, 컬렉션, 배열과 같은 데이터 소스에서 요소를 처리하고 다양한 연산을 수행할 수 있는 API이다.
스트림의 특징은 다음과 같다.
- 내부 반복을 통해 불필요한 for, if 구문 없이 구현할 수 있어 직관적이며 가독성이 좋음
- 원본 데이터를 변경하지 않음
- 일회성으로 단 한번만 사용이 가능함
- 병렬 처리 지원 (parallelStream() 등)
- 필터-맵 기반의 API를 사용하여 지연 연산을 통해 성능을 최적화
코딩테스트에서는 주로 Collections 객체.스트림생성().중개연산().최종연산()으로 구분된다.
마치 파이프라인 형태로 게속 .을 통해 체인처럼 연결하여 데이터 작업이 가능한 것이다.
스트림생성()
아래는 스트림을 생성하는 방법이다.
List<String> names = Arrays.asList("Kim", "Hong", "JAVA");
names.stream(); // Collection에서 스트림 생성
Double[] dArray = {3.1, 3.2, 3.3};
Arrays.stream(dArray); // 배열로 스트림 생성
Stream<Integer> str = Stream.of(1, 2); // 스트림 직접 생성중개연산()
정말 수많은 중개 연산이 있지만, 그 중 많이 사용하는 메서드들을 위주로 설명하겠다.
filter()
조건에 맞는 것만 찾아서 Stream 반환한다.
List<String> names = Arrays.asList("Kim", "Hong", "JAVA");
Stream<String> s = names.stream().filter(x -> x.contains("K"));
// 결과 : Kimmap()
Stream의 각 요소들에 대해 함수가 적용된 결과의 새로운 요소로 매핑한다.
List<String> names = Arrays.asList("Kim", "Hong");
names.stream().map(x -> x.concat("abc"))
.forEach(x -> System.out.println(x));
// 결과
// Kimabc
// Hongabcsorted()
스트림의 요소를 정렬하는 함수이다.
List<Integer> nums = Arrays.asList(3, 1, 4, 1, 5, 9);
nums.stream()
.sorted()
.forEach(System.out::println); // 결과: 1, 1, 3, 4, 5, 9distinct()
중복된 값을 제거하는 작업을 수행한다.
/* 요소에서 중복된 값들을 제거하는 작업을 수행 한다. */
List<Integer> numbers = Arrays.asList(1, 2, 2, 3, 3, 3, 4, 4, 4, 4, 5, 5, 5, 5, 5);
Stream<Integer> stream = numbers.stream().distinct(); // 중복된 값을 제거하는 Stream이 외에도 아래에 다양한 중개 연산이 존재한다.
- Stream<T> distinct() 중복을 제거
- Stream<T> filter(Predicate<T> predicate) 조건에 안 맞는 요소 제외
- Stream<T> limit(long maxSize) 스트림의 일부를 잘라냄
- Stream<T> skip(long n) 스트림의 일부를 건너뜀
- Stream<T> peek(Consumer<T> action) 스트림의 요소에 작업수행
- Stream<T> sorted() 스트림의 요소를 정렬
Stream<T> sorted(Comparator<T> comparator)
- Stream<R> map(Function<T,R> mapper) 스트림의 요소를 변환
DoubleStream mapToDouble(ToDoubleFunction<T> mapper)
IntStream mapToInt(ToIntFunction<T> mapper)
LongStream mapToLong(ToLongFunction<T> mapper)
Stream<R> flatmap(Function<T,Stream<R>> mapper)
DoubleStream flatMapToDouble(Function<T,DoubleStream> m)
IntStream flatMapToInt(Function<T,IntStream> m)
LongStream flatMapToLong(Function<T,LongStream> m)최종연산()
모든 데이터 처리가 끝난 후 Stream에 있는 요소들을 적절하게 반환하는 연산이다. 최종연산이라는 특징 상 단 1번만 실행한다.
forEach()
각 요소에 대해 반복하며 출력한다.
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
numbers.stream()
.forEach(System.out::println); // 각 요소를 출력reduce()
초기값을 설정하여 각 요소에 대해 누적합 계산을 하는 함수이다.
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
int sum = numbers.stream()
.reduce(0, (x, y) -> x + y); // 모든 요소의 합을 계산하여 반환
System.out.println(sum); // 15collect()
Stream 요소를 수집하여 다시 컬렉션 형태로 반환해주는 함수이다.
자주 사용하는 수집기로는 toList(), toSet(), toMap()이 있다.
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
List<Integer> evenNumbers = numbers.stream()
.filter(n -> n % 2 == 0) // 짝수만 선택
.collect(Collectors.toList()); // 짝수 요소를 리스트로 수집하여 반환toArray()
모든 요소를 배열로 수집하여 반환한다.
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
Integer[] array = numbers.stream()
.toArray(Integer[]::new); // Integer 배열로 변환하여 반환Stream API에 대한 개념과 자세한 이해는 MangKyu님의 [Java] Stream API에 대한 이해를 참고하면 좋을 것 같다.
[Java] Stream API에 대한 이해: https://mangkyu.tistory.com/112
형 변환
자바에서 형 변환은 자주 사용하는 기술이니 한번 짚고 넘어가자. 어려운 코드는 아니니 금방 이해할 것이다.
String형 -> 숫자형(int, double, float, long, short)
String sNum = "1234";
int i1 = Integer.parseInt(sNum);
int i2 = Integer.valueOf(sNum);
double d1 = Double.parseDouble(sNum);
double d1 = Double.valueOf(sNum);
flaot f1 = Double.parseFloat(sNum);
float f2 = Double.valueOf(sNum);
long l1 = Double.parseLong(sNum);
long l2 = Double.valueOf(sNum);
short s1 = Double.parseShort(sNum);
shrot s2 = Double.valueOf(sNum);숫자형(int, double, float, long, short) -> String 형
int i = 1234;
String i1 = String.valueOf(i);
String i2 = Integer.toString(i);
double d = 1234;
String d1 = String.valueOf(d);
String d2 = Double.toString(d);
float f = 1234;
String f1 = String.valueOf(f);
String f2 = Float.toString(f);
long l= 1234;
String l1 = String.valueOf(l);
String l2 = Long.toString(l);
short s = 1234;
String s1 = String.valueOf(s);
String s2 = Short.toString(s);valueOf는 만능으로 사용가능하지만, 사실 Wrapper 클래스 형태로 반환한 결과를 자동으로 언박싱하는 구조이기 때문에 속도 측면에서 조금 느릴 수 있다.
BufferedReader, StringTokenizer, BufferedWriter
프로그래머스의 경우 입력처리를 해주지 않아도 되므로 몰라도 되지만, 대부분은 코테를 준비하면서 백준도 같이 풀거라고 생각한다.
따라서 주로 백준 문제를 풀때 향상된 입력처리를 제공하는 클래스에 대해 설명하겠다.
지금까지 입력은 Scanner 클래스르 사용한다고 배워왔다. 하지만 Scanner의 경우 다양한 기능을 지원하기 때문에 속도가 느리다는 단점이 있다.
따라서 문자열에 최적화된 BufferedReader와 StringTokenizer 클래스가 등장한다!
먼저 BufferedReader의 기본적인 사용방법은 다음과 같다.
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));기본적으로 System.in을 하게 되면 바이트 단위로 읽어들이기 때문에, 이를 문자로 변환하는 역할이 필요하다. 이때 사용하는 것이 InputStreamReader이며, 바이트 스트림을 문자 스트림으로 변환해주는 클래스이다.
이제 Scanner의 nextInt() 메서드와 같이 입력 받겠다는 메서드 명령이 필요하다. BufferedReader에서는 한 줄 단위로 읽는 readLine() 메서드를 제공한다.
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
String s = br.readLine();
int i = Integer.parseInt(br.readLine());한가지 주의할 점은 무조건 String 형태로 고정되어 반환하므로 이를 다른 타입으로 바꾸고 싶으면 반드시 형 변환이 필요하다.
또한 readLine() 메서드의 경우 체크 예외(Checked Exception)를 선언한 메서드이다! 따라서 이를 사용하기 위해서는 호출한 클래스에 throws IOException을 통해 예외를 위임해 주거나, 아니면 try ~ catch 구문 안에 넣어서 사용해야 한다.
대부분은 try ~ catch문 쓰면 가독성이 떨어지기 때문에 그냥 main 메서드 옆에 throws IOException을 추가한다.
// BufferedReader 클래스의 readLine() 메서드가 IOException을 throws 하고 있음
// 따라서 main 함수도 예외 처리를 JVM에 넘기기 위해 throws IOException 선언 필요
public static void main(String[] args) throws IOException {
// 빠른 입력 처리를 위해 BufferedReader 사용
// 바이트 스트림을 문자 스트림으로 변환하기 위해 InputStreamReader 사용
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
// 특정 구분자(default 공백)를 기준으로 토큰화 해주는 StringTokenizer 사용
// 한 줄씩 읽어서 String 형태로 반환하는 readLine() 메서드
StringTokenizer st = new StringTokenizer(br.readLine());
}다음으로 StringTokenizer는 주어진 문자열을 특정 구분자(default는 공백)을 기준으로 분리하여 토큰화해주는 클래스이다.
StringTokenizer st = new StringTokenizer(br.readLine());그래서 BufferedReader의 readLine()으로 읽어온 문자열을 공백으로 나누어서 아래와 nextToken() 메서드를 통해 저장할 수 있는 것이다.
// nextToken()을 통해 구분자를 기준으로 토큰화된 문자열들을 하나씩 들고옴
int suNo = Integer.parseInt(st.nextToken());
int quizNo = Integer.parseInt(st.nextToken());만약 공백을 기준으로 하지 않고 다른 구분자를 넣고 싶다면 문자열 뒤에 매개변수로 추가해서 넘겨주면 된다.
String s = "My||name||is|Kim";
StringTokenizer st = new StringTokenizer(s, "||");
while (st.hasMoreTokens()) {
System.out.println(st.nextToken());
}
// My
// name
// is
// Kim마지막으로 BufferedWriter는 출력을 위한 클래스이다. 이 역시 BufferedReader와 동일한 이유로 System.out.println은 속도면에서 다소 떨어져 출력이 잦은 경우 성능을 향상하기 위해 사용한다.
기본적인 사용법은 아래와 같다.
BufferedWriter bw = new BufferedWriter(new OutputStreamReader(System.out));
bw.write("Hello World");
bw.flush();
bw.close();System.out.println과 차이점은 아래와 같다.
-
자동 개행을 지원하지 않는다.
-> 필요할 경우 newLine() 메서드 호출 또는 write("\n') 추가 -
flush() 메서드를 통해 버퍼에 저장되어 있는 모든 문자열을 출력
-> write 메서드는 버퍼에 저장하는 것이고 출력이 아닌 점에 유의하자! -
close() 메서드를 통해 스트림을 종료하여 비움
Comparable, Comparator
자바에서 어떤 타입과 혹은 특정 객체와 비교를 원할 때 사용하는 인터페이스이다. 인터페이스이므로 만약 이를 사용하고자 한다면 인터페이스 내에 선언된 메서드를 반드시 구현해야 한다.
근데 코테에서 보면 비교로 끝나지 않고, 이를 이용하여 정렬하는 알고리즘을 많이 볼 수 있다.
지금부터 이해하기 쉽게 하나씩 설명하도록 하겠다.
먼저 Comparable, Comparator의 목적은 모두 객체를 비교할 수 있도록 만드는 것이다.
잘 알다시피 객체는 어떤 것을 기준으로 비교할지 알 수 없기 때문에 개발자가 특정 필드를 기준으로 비교한다고 지정해주어야 한다.
Comparable
먼저 Comparable은 자기 자신과 매개변수 객체를 비교하는 것이다.
인터페이스 정의는 다음과 같다.
public interface Comparable<T> {
...
@Override
public int compareTo(T o) {
/*
비교 구현
*/
}
}따라서 우리는 compareTo 메서드를 구현해야 하며, 제네릭 T에 비교할 타입을 넣어주면 된다.
아래는 compareTo 메서드를 구현하는 Student 클래스의 예시이다.
class Student implements Comparable<Student> {
int age;
int classNumber;
Student(int age, int classNumber) {
this.age = age;
this.classNumber = classNumber;
}
@Override
public int compareTo(Student o) {
// 자기자신의 age가 o의 age보다 크다면 양수
if (this.age > o.age) {
return 1;
}
// 자기 자신의 age와 o의 age가 같다면 0
else if (this.age == o.age) {
return 0;
}
// 자기 자신의 age가 o의 age보다 작다면 음수
else {
return -1;
}
}
}Student 클래스의 경우 필자가 임의로 age를 기준으로 대소관계를 비교하였다. 물론 어떻게 구현하냐에 따라 classNubmer가 될수도 있고 다른 필드로 비교할 수 있을 것이다.
원래 비교 후 반환하는 전통적인 방식은 수가 더 큰 경우 1, 같으면 0, 작으면 -1을 하는 것이 맞지만, 잘 생각해보면 양수, 0, 음수로만 반환해도 비교하는 데에는 아무런 문제가 없다.
따라서 아래와 같이 코드를 개선할 수 있다.
class Student implements Comparable<Student> {
int age; // 나이
int classNumber; // 학급
Student(int age, int classNumber) {
this.age = age;
this.classNumber = classNumber;
}
@Override
public int compareTo(Student o) {
/*
* 만약 자신의 age가 o의 age보다 크다면 양수가 반환 될 것이고,
* 같다면 0을, 작다면 음수를 반환할 것이다.
*/
return this.age - o.age;
}
}Comparator
다음으로 Comparator은 두 매개변수 객체를 비교한다. 이 말은 자기 자신이 아니라 파라미터로 들어오는 매개변수끼리 비교한다는 것이다.
@FunctionalInterface
public interface Comparator<T> {
...
@Override
public int compare(T o1, T o2) {
/*
비교 구현
*/
}
}따라서 우리는 compare 메서드를 구현해야 하며 이 역시 제네릭 T에 비교할 타입을 넣어주면 된다.
아래는 compare를 구현하는 Student 클래스의 예시이다.
import java.util.Comparator; // import 필요
class Student implements Comparator<Student> {
int age; // 나이
int classNumber; // 학급
Student(int age, int classNumber) {
this.age = age;
this.classNumber = classNumber;
}
@Override
public int compare(Student o1, Student o2) {
/*
* 만약 o1의 classNumber가 o2의 classNumber보다 크다면 양수가 반환 될 것이고,
* 같다면 0을, 작다면 음수를 반환할 것이다.
*/
return o1.classNumber - o2.classNumber;
}
}compare 메서드 역시 1, 0, -1 대신 양수, 0, 음수로 구분해도 충분하기 때문에 위와 같은 코드가 완성될 것이다.
여기서 눈치챈 사람도 있겠지만 compare 메서드의 경우 호출하기 위해 아무거나 어느 한 객체를 생성하여 이를 통해 메서드를 호출해야 한다는 점이다.
이를 다르게 말하면 일관성이 떨어진다는 단점이 있다.
이를 해결하기 위해 익명 클래스를 사용할 수 있다. 다음 코드를 보자.
import java.util.Comparator;
public class Test {
public static void main(String[] args) {
// 익명 객체 구현방법 1
Comparator<Student> comp1 = new Comparator<Student>() {
@Override
public int compare(Student o1, Student o2) {
return o1.classNumber - o2.classNumber;
}
};
}
// 익명 객체 구현 2
public static Comparator<Student> comp2 = new Comparator<Student>() {
@Override
public int compare(Student o1, Student o2) {
return o1.classNumber - o2.classNumber;
}
};
}
// 외부에서 익명 객체로 Comparator가 생성되기 때문에 클래스에서 Comparator을 구현 할 필요가 없어진다.
class Student {
int age; // 나이
int classNumber; // 학급
Student(int age, int classNumber) {
this.age = age;
this.classNumber = classNumber;
}
}근데 우리는 익명 클래스 대신 람다식을 사용하면 더욱 간결하게 표현이 가능하다고 배웠다. 따라서 람다식까지 적용한 코드는 다음과 같다.
import java.util.Comparator;
public class Test {
public static void main(String[] args) {
// 람다식을 사용한 Comparator 구현 1
Comparator<Student> comp1 = (o1, o2) -> o1.classNumber - o2.classNumber;
}
// 람다식을 사용한 Comparator 구현 2
public static Comparator<Student> comp2 = (o1, o2) -> o1.classNumber - o2.classNumber;
}
class Student {
int age; // 나이
int classNumber; // 학급
Student(int age, int classNumber) {
this.age = age;
this.classNumber = classNumber;
}
}익명 클래스를 람다식으로 바꾸고 싶다면 아래 구조를 참고하길 바란다.
(바로 적용할 수 있도록 암기하는 것을 추천한다)
// 익명 객체를 사용한 구현방법
타입명 변수명 = new 타입명() {
@Override
public int 메서드명(타입명 o1, 타입명 o2) {
return o1.필드명 - o2.필드명;
}
};
// 람다식을 사용한 구현방법
타입명 변수명 = (o1, o2) -> o1.필드명 - o2.필드명;두개를 같이 놓고 보니 매개변수 타입명, 메서드명을 생략하고 ->을 기준으로 왼쪽에는 매개변수, 오른쪽에 리턴할 수식만 적어주면 끝이다.
Comparable, Comparator과 정렬의 관계
이제 드디어 정렬함수인 sort()와 함께 조합하여 사용할 차례이다. 자바에서는 배열의 경우 Arrays.sort(), Collections.sort()를 제공하고 있다. 그리고 디폴트로 오름차순을 기준으로 정렬한다.
하지만 sort 함수는 이 외에도 더욱 확장된 기능을 제공하는데, 바로 우리가 위에서 배운 Comparator 클래스를 2번째 매개변수로 받을 수 있다는 것이다!
public static <T> void sort(T[] a, Comparator<? super T> c) {
...
}따라서 Comparator 파라미터로 넘어온 c의 비교 기준을 가지고 객체 배열 a도 정렬이 가능하다는 의미이다.
우리는 지금까지 Arrays.sort(arr)만 해도 잘 정렬되었는데요?? 라고 물어볼 수 있다.
일반 배열의 경우는 당연히 이미 내부적으로 compare 메서드가 오버라이딩 되어있으니 가능한 얘기이고, 우리가 직접 만든 객체는 정렬 순서도 만들어 주어야 한다는 걸 기억하자.
따라서 정렬을 적용한 코드는 다음과 같이 작성할 수 있다.
import java.util.Arrays;
import java.util.Comparator;
public class Test {
public static void main(String[] args) {
MyInteger[] arr = new MyInteger[10];
// 객체 배열 초기화 (랜덤 값으로)
for(int i = 0; i < 10; i++) {
arr[i] = new MyInteger((int)(Math.random() * 100));
}
// 정렬 이전
System.out.print("정렬 전 : ");
for(int i = 0; i < 10; i++) {
System.out.print(arr[i].value + " ");
}
System.out.println();
Arrays.sort(arr, comp); // MyInteger에 대한 Comparator을 구현한 익명객체를 넘겨줌
// 정렬 이후
System.out.print("정렬 후 : ");
for(int i = 0; i < 10; i++) {
System.out.print(arr[i].value + " ");
}
System.out.println();
}
static Comparator<MyInteger> comp = (o1, o2) -> o1.value - o2.value;
}
class MyInteger {
int value;
public MyInteger(int value) {
this.value = value;
}
}Comparator를 람다식 기법으로 바꿔 이를 스트림과 함께 짬뽕하여 적용하는 문제가 매우 많으므로 잘 기억하도록 하자.
(대표적으로 프로그래머스 실패율 42889번이 있으며 아래 문제풀이에 위 개념이 적용되었으니 참고바람)
[프로그래머스 실패율 문제풀이]: https://velog.io/@wonotter/%ED%94%84%EB%A1%9C%EA%B7%B8%EB%9E%98%EB%A8%B8%EC%8A%A4-%EC%8B%A4%ED%8C%A8%EC%9C%A8
Iterable, Iterator
위에서 배운 Collection 프레임워크에 존재하는 List, Set, Queue, Deque 상위 인터페이스로 Iterable 인터페이스가 존재한다.
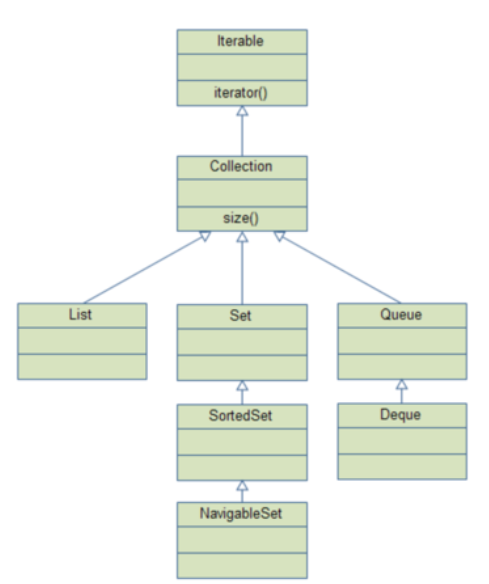
그리고 Iterable 인터페이스 내부에 iterator() 메서드가 존재한다. 따라서 모든 컬렉션 프레임워크에서는 반복자 메서드인 iterator 사용이 가능하다는 뜻이다.
public interface Iterable<T> {
Iterator<T> iterator();
}그러면 iterator 메서드를 반환하는 Iterator 타입은 무엇인지 알아야 한다. 이를 따라 들어가보면 아래와 같이 hasNext(), next(), remove() 메서드를 제공한다
public interface Iterator<E> {
boolean hasNext();
E next();
default void remove() {
throw new UnsupportedOperationException("remove");
}
}따라서 이를 활용하면 아래와 같이 사용이 가능하다.
import java.util.Iterator;
import java.util.LinkedList;
public class Test {
public static void main(String[] args) {
LinkedList<String> list = new LinkedList<>();
list.add("Lee"); list.add("ekk"); list.add("eww");
Iterator it = list.iterator();
while (it.hasNext()) {
System.out.print(it.next() + " ");
}
}
}☃️ 코딩테스트 구현 팁
코딩테스트에서 구현할 때 그나마 에러를 줄여주는 팁들을 몇가지 소개한다.
(사실 가장 좋은 팁은 문제를 많이 풀어보는 것)
조기 반환
코드 실행 과정이 함수 끝까지 도달하기 전에 반환하는 기법이다.
public static void main(String[] args) {
System.out.println(totalPrice(4, 50));
}
static int totalPrice(int quanitity, int price) {
int total = quantity * price;
if (total > 100)
return (int)(total * 0.9);
return total;
}보호 구문
본격적인 로직을 진행하기 전 예외 처리 코드를 추가하는 기법이다.
import java.util.List;
static double calculateAverage(List<Integer> numbers) {
if (numbers == null)
return 0;
if (numbers.isEmpty())
return 0;
int total = numbers.stream().mapToInt(i -> i).sum();
return (double) total / numbers.size();
}제네릭
제네릭은 빌드 레벨에서 타입을 체크하여 타입 안정성을 제공하고 타입 체크와 형 변환을 생략할 수 있게 해준다.
List list = new ArrayList();
list.add(10);
list.add("abc");
// 런타임 오류 발생
int sum1 = (int)list.get(0) + (int)list.get(1);
List<Integer> genericList = new ArrayList<>();
genericList.add(10);
// 빌드 오류 발생
genericList.add("abc");
int sum2 = genericList.get(0) + genericList.get(1);제네릭의 사용 이유 중 하나인 타입 강제를 통해, List를 정의할 때 <Integer>와 같이 사용하면 타입에 맞지 않는 데이터를 추가하려 할 때 문법 오류를 발생시켜 실수를 예방할 수 있다.

좋은 글 잘 보고 갑니다 ㅎ