개요
트라이(Trie)는 영어 단어와 같이 모음으로 나타낼 수 있는 데이터의 저장을 전문으로 하는 트리(Tree)입니다.
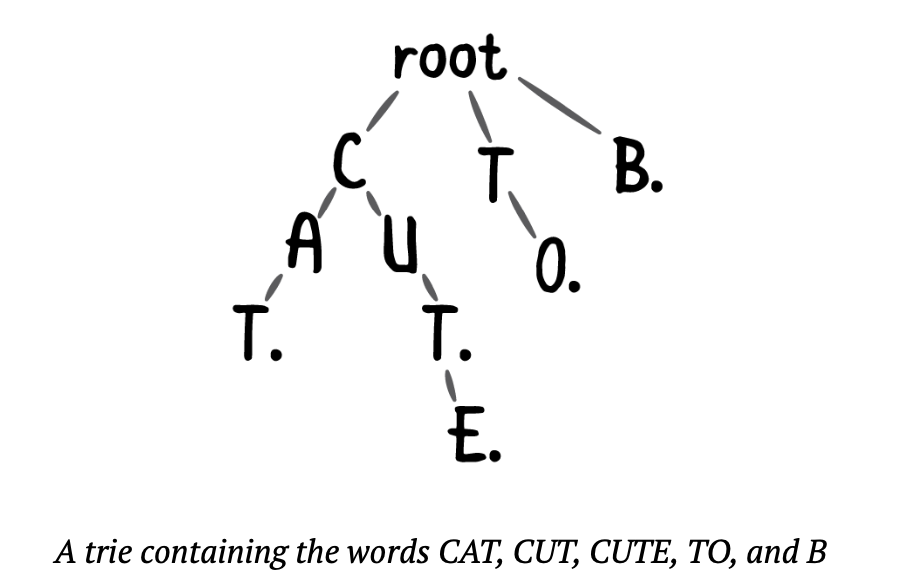
문자열의 각 문자는 노드에 매핑됩니다.
각 문자열의 마지막 노드는 종료 노드로 표시됩니다. (위 이미지에서는 점으로 표시됨)
트라이 자료구조의 장점은 아무래도 접두사 일치(prefix matching) 과정에서 가장 잘 드러날 수 있습니다.
만약 문자열의 콜렉션이 주어졌을 때, 개발자는 어떻게 접두사 일치(prefix matching)를 처리하는 로직을 구현할 수 있을까요?
class EnglishDictionary {
private val words: ArrayList<String> = ...
fun words(prefix: String) = words.filter { it.startsWith(prefix) }
}만약 위 코드에서 words 배열의 크기가 작다면, 해당 로직은 괜찮은 전략이 될 것입니다.
그런데 만약 수천, 수만가지의 단어들을 다루고자 한다면, 이건 한마디로 대재앙일 것입니다. (엄청난 시간이 소요될 것으로 예상됨)
왜냐하면, 위 코드의 words() 메서드의 시간복잡도는 O(k*n)이기 때문입니다. (단, k는 컬렉션에서 가장 긴 문자열이고, n은 확인해야 하는 단어의 수)
트라이 자료구조는 점으로 표시되는 종료자를 사용하여 root에서 노드까지 문자 콜렉션을 추적하여 단어를 형성합니다.
또한, 트라이 자료구조에서 흥미로운 점은 여러 단어가 동일한 문자를 공유할 수 있다는 것입니다.
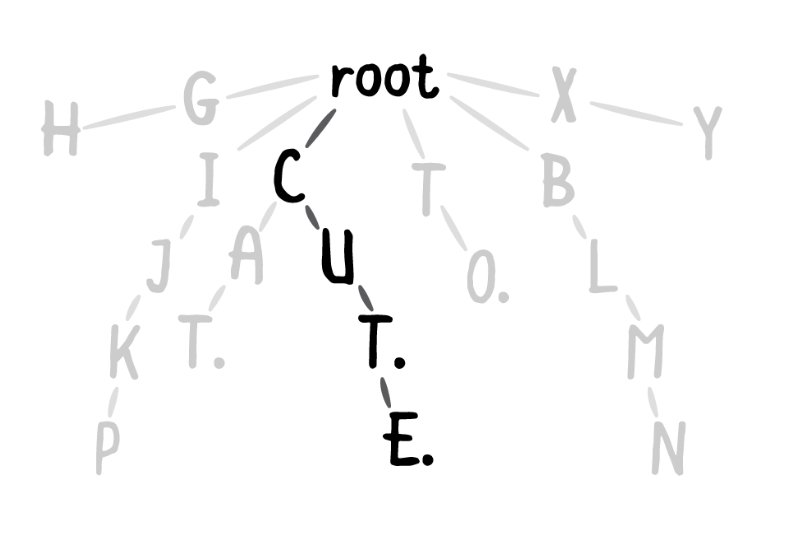
이러한 트라이의 장점을 보여주기 위해, CU라는 접두사를 활용하여 단어를 찾는 예시를 아래에서 보여드리도록 하겠습니다.
먼저 C가 포함된 노드로 이동합니다.
그러면 검색 작업에서 트리의 다른분기(branch)가 빠르게 제외됩니다. (그림에서는 T와 B로 시작하는 분기)

다음으로 다음 문자인 U가 있는 단어들을 찾아야 합니다.
U 노드로 이동합니다.

이것이 접두사의 끝이므로, 트라이는 U 노드의 노드 체인에 의해 형성된 모든 컬렉션을 반환합니다.
이 경우에는 CUT 및 CUTE라는 단어가 반환됩니다.
만약 이러한 트라이 자료구조에 수십만 개의 단어가 포함되어 있다고 상상해 보면...?
트라이를 사용하여 피할 수 있는 경우의 수는 상당합니다.
그럼 이제 구현 코드를 한 번 살펴볼까요?
구현
TrieNode
우선 트라이 자료구조를 위한 노드를 만들어야합니다.
class TrieNode<Key>(var key: Key?, var parent: TrieNode<Key>?) {
val children: HashMap<Key, TrieNode<Key>> = HashMap()
var isTerminating = false
}이 인터페이스는 지금까지 본 다른 노드와 약간 다릅니다.
키(key)는 노드의 데이터를 보유합니다. 트리의 루트 노드는 키(데이터)가 없기 때문에 이것은 선택 사항(nullable)입니다.TrieNode는 부모에 대한 참조를 보유합니다. 이 참조는 나중에 remove()를 단순화합니다.이진 검색 트리(binary search tree)에서 노드에는 왼쪽, 오른쪽 자식이 있습니다. 트라이에서 노드는 여러 다른 자식들을 보유해야 합니다. 이를 위해childern HashMap을 선언했습니다.- 앞에서 설명한 것처럼,
isTerminating은 컬렉션의 끝을 알리는표시기(indicator)역할을 합니다.
Trie
다음으로 노드들을 관리할 트라이 클래스를 만듭니다.
class Trie<Key> {
private val root = TrieNode<Key>(key = null, parent = null)
}트라이 클래스는 키(Key)를 포함하는 컬렉션을 저장할 수 있습니다.
다음으로, 트라이에 사용될 4가지 함수(insert, contains, remove, prefix match)를 정의할 것입니다.
Insert
트라이는 리스트를 가져와 각 노드가 리스트의 요소에 매핑되는 일련의 노드로 나타냅니다.
fun insert(list: List<Key>) {
// 1
var current = root
// 2
list.forEach { element ->
if (current.children[element] == null) {
current.children[element] = TrieNode(element, current)
}
current = current.children[element]!!
}
// 3
current.isTerminating = true
}current는 루트 노드에서 시작하는 순회를 추적합니다.- 트라이는 리스트의 각 원소를 별도의 노드에 저장합니다. 목록의 각 원소에 대해 먼저 노드가 현재
children HashMap에 있는지 확인합니다. 그렇지 않은 경우 새 노드를 만듭니다. 루프 가 한번 돌면current는 다음 노드로 이동합니다. - for 루프를 반복한 후,
current는 리스트의 끝을 나타내는 노드를 참조해야 합니다. 해당 노드를 종료 노드로 표시합니다.
이 알고리즘의 시간 복잡도는 O(k)입니다.
여기서 k는 삽입하려는리스트의 원소 갯수입니다.
왜냐하면 새 리스트의 각 원소를 나타내는 각 노드를 통과하거나 생성해야 하기 때문입니다.
(위 예제 코드의 주석 2번째 로직이라고 보면 됨)
Contains
contains는 insert와 유사합니다.
다음 메서드를 트라이(Trie) 클래스에 추가해봅시다.
fun contains(list: List<Key>): Boolean {
var current = root
list.forEach { element ->
val child = current.children[element] ?: return false
current = child
}
return current.isTerminating
}코드를 보면 insert와 비슷한 방식으로 트라이를 순회하는 것을 알 수 있습니다.
우선 리스트의 모든 원소를 확인하여 트리에 있는지 확인합니다.
다음, 리스트의 마지막 원소에 도달하면 그것이 종료 노드일 경우 참을 반환하고,
그렇지 않은 경우에는 거짓을 반환합니다.
contains의 시간 복잡도는 O(k)입니다.
여기서 k는 찾고 있는리스트의 원소 갯수입니다.
리스트가 트라이에 있는지 여부를 확인하려면 k개의 노드를 통과해야 하기 때문입니다.
참고
이런식으로 확장함수를 구현하여 위 두가지의 메서드를 표현할 수 있습니다.
fun Trie<Char>.insert(string: String) {
insert(string.toList())
}
fun Trie<Char>.contains(string: String): Boolean {
return contains(string.toList())
}Remove
트라이에서 노드를 제거하는 것은 좀 더 까다롭습니다.
여러 다른 컬렉션 간에 노드를 공유할 수 있으므로 각 노드를 제거할 때 특히 주의해야 합니다.
코드를 한 번 살펴보겠습니다.
fun remove(collection: CollectionType) {
// 1
var current = root
collection.forEach {
val child = current.children[it] ?: return
current = child
}
if (!current.isTerminating) return
// 2
current.isTerminating = false
// 3
val parent = current.parent
while (current.children.isEmpty() && !current.isTerminating) {
parent?.let {
it.children[current.key] = null
current = it
}
}
}- 이 부분은 기본적으로
contains의 구현이므로 익숙해 보일 것입니다. 컬렉션이 트라이의 일부인지 확인하고 현재 컬렉션의 마지막 노드를 가리킵니다. current노드가 다음 단계의 루프에서 제거될 수 있도록isTerminating을false로 설정합니다.- 여기가 좀 까다로운 부분입니다. 노드는 공유될 수 있으므로 다른 컬렉션에 속한 원소를 부주의하게 제거하고 싶지 않습니다.
current노드에 다른 자식이 없으면 다른 컬렉션이 현재 노드에 종속되지 않음을 의미합니다. 또한 현재 노드가종료 노드(isTerminating = true)인지 확인합니다. 그렇다면 다른 컬렉션에 속합니다.current노드가 이러한 조건을 충족하는 한 계속해서parent노드를역추적(backtrack)하고 노드를 제거합니다. (조건이 충족되지 않으면 while 문에서 계속 다음 루프로 돌아간다는 의미)
이 알고리즘의 시간 복잡도는 O(k)입니다.
여기서 k는 제거하려는 컬렉션의 원소 갯수를 나타냅니다.
remove 메서드를 다음과 같이 간단한 확장함수로 구현할 수 있습니다.
fun Trie<Char>.remove(string: String) {
remove(string.toList())
}Prefix matching
트라이 자료구조의 가장 상징적인 알고리즘은 접두사 일치(Prefix matching) 알고리즘입니다. 코드를 한 번 살펴봅시다.
fun collections(prefix: List<Key>): List<List<Key>> {
// 1
var current = root
prefix.forEach { element ->
val child = current.children[element] ?: return emptyList()
current = child
}
// 2
return collections(prefix, current)
}- 트라이에
접두사(prefix)가 포함되어 있는지 확인하는 것으로 시작합니다. 그렇지 않으면empty list를 반환합니다. 접두사(prefix)의 끝을 표시하는 노드를 찾은 후도우미 재귀함수(recursive helper method)를 호출하여 현재 노드 이후의 모든 시퀀스를 찾습니다. (다음 코드 확인)
다음은 도우미 재귀함수(recursive helper method)의 코드입니다.
private fun collections(prefix: List<Key>, node: TrieNode<Key>?): List<List<Key>> {
// 1
val results = mutableListOf<List<Key>>()
if (node?.isTerminating == true) {
results.add(prefix)
}
// 2
node?.children?.forEach { (key, node) ->
results.addAll(collections(prefix + key, node))
}
return results
}- 결과를 보관할
MutableList를 만듭니다. 만약 현재 노드가 종료 노드일 경우, 해당접두사(prefix)를results에 추가합니다. - 다음으로 현재 노드의
children을 확인해야 합니다. 모든 자식 노드에 대해collections()를 재귀적으로 호출하여 다른 종료 노드를 찾습니다.
collection()메서드의 시간 복잡도는 O(k x m)입니다.
여기서 k는접두사(prefix)와 일치하는 가장 긴 컬렉션을 나타내고,
m은접두사(prefix)와 일치하는 컬렉션의 수를 나타냅니다.
참고로, 배열의 시간 복잡도는 O(k x n)입니다. 여기서 n은 컬렉션의 요소 수입니다.
결론적으로, 각 컬렉션이 균일하게 분산된 대규모 데이터 집합의 경우,
트라이(Trie)는 배열(Array)에 비해 접두사 일치(prefix matching) 알고리즘에 있어서 훨씬 더 나은 성능을 제공합니다.
마지막으로 다음과 같은 확장함수를 사용하여 간단하게 구현할 수 있습니다.
fun Trie<Char>.collections(prefix: String): List<String> {
return collections(prefix.toList()).map
{ it.joinToString(separator = "") }
}요약
- 트라이는
접두사 일치 알고리즘(prefix matching)에 있어서 훌륭한 성능을 낼 수 있습니다. - 트라이는 개별 노드가 여러 다른 값 간에 공유될 수 있으므로 상대적으로 메모리 효율적이기도 합니다. 예를 들어 "car", "carbs" 및 "care"는 단어의 처음 세 글자를 공유할 수 있습니다.
