부트캠프에서 하게 된 2차 프로젝트에 대해 정리합니다. 목차는 기획 단계, 협업 방식, 잘한 점과 아쉬운 점으로 구성했습니다.
기획 단계
원티드

이번에 맡게 된 클론 프로젝트의 대상은 원티드.
원티드란?
채용시장의 수요와 공급을 한 곳에서 해결할 수 있다는 점이 핵심이다. 즉, 기업 입장에서는 자신이 필요로 하는 인재와 그들의 이력서를 한 곳에서 볼 수 있고, 지원자 입장에서는 자신이 필요로 하는 기업과 그들의 정보를 한 곳에서 볼 수 있다. 오프라인의 헤드헌터를 온라인으로 옮겨놓았다고 생각이 든다.
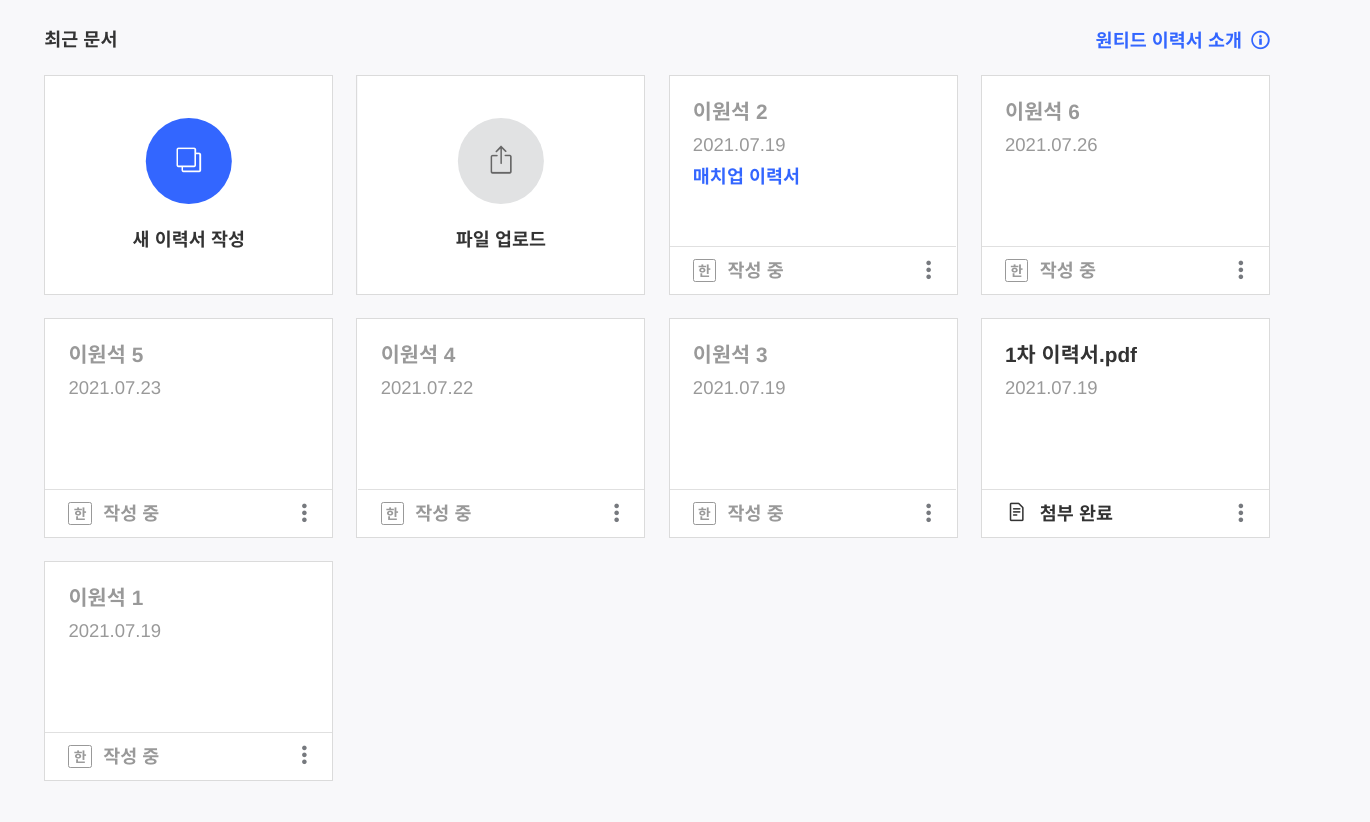
특히 지원자의 경우 여러가지 이력서를 등록하고, 전략에 맞게 이력서를 조합해서 지원할 수 있다는 점이 매력적으로 다가왔다. 또한 당연한 얘기이긴 하지만 기업과 직종에 따라 원하는 이력서의 양식이 다르기 때문에 (PDF, 노션 링크, 이미지, 동영상 등) 파일을 첨부해 이력서로 쓸 수 있게끔 했다는 점이 좋았다.
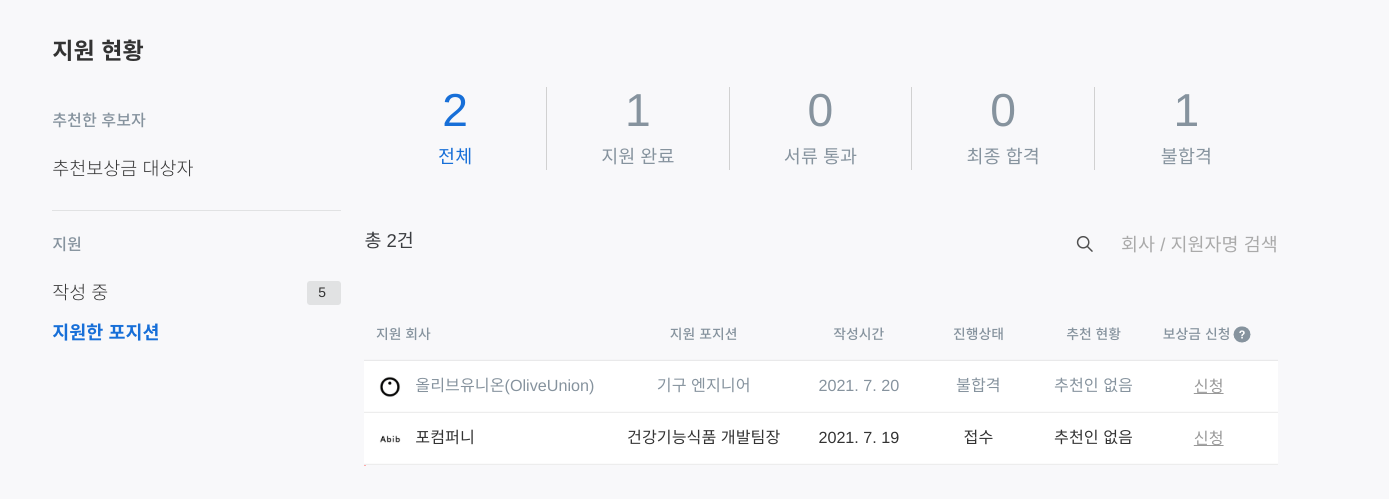
되도 않는 이력서를 넣고 지원해본 두 회사. 한 곳은 벌써 불합격 통지를 주셨다. 반응이라도 해주셔서 감사합니다.
지원 현황 기능도 매력적이었다. 내가 지원한 기업 채용공고의 종류뿐만 아니라, 지원들이 현재 어떤 상태인지를 볼 수 있었다. 당연하게 여길 수도 았겠지만, 나는 이 기능이 매우 강력하다고 생각했다. 쿠팡 잇츠의 강점과 비슷하다. 현재 내가 시킨 음식이 어디쯤에 와있는지를 알려주는 기능. 배달을 시키는 사람은 누구나 생각해본 기능이다. 지원자의 마음도 마찬가지이지 않을까?
기획 방향
팀원과 상의하고 멘토링 받은 결과, 사이트의 우선순위는 다음과 같다.
- 필터에 따른 채용공고 검색
- 회원가입과 로그인
- 채용공고 상세
- 직군별 연봉
- 이력서 CRUD
- 지원
- 마이페이지
- 직군별 연봉
AI 추천기능, 네트워크 연결, 커리어 성장 등의 기능들은 아쉽지만 우선순위에서 밀리게 되었다.
모델링과 ERD
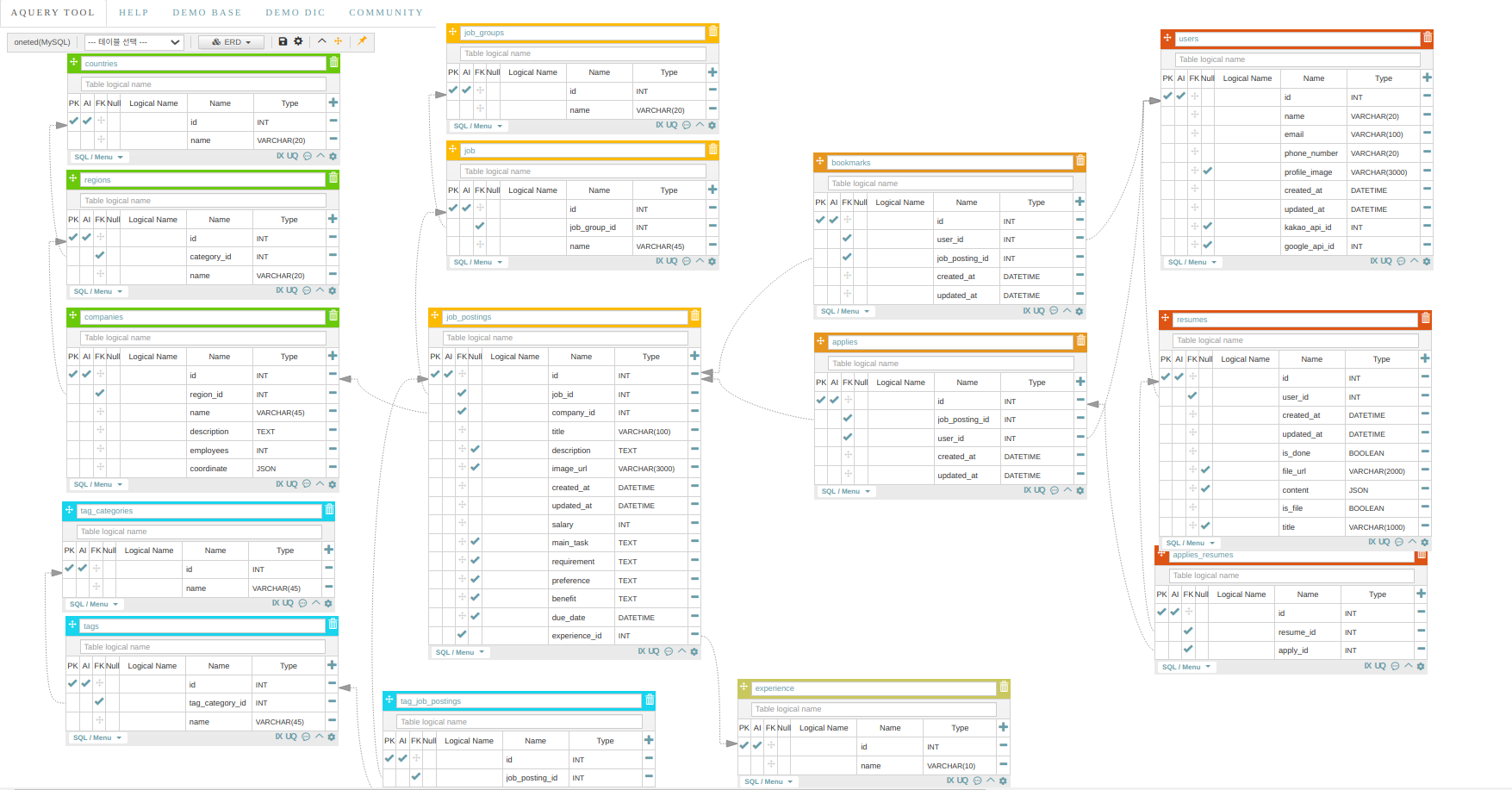
핵심 테이블은 채용공고와 이력서이다.
채용공고는 각각의 회사, 태그, 경력과 관계를 맺는다.
이력서는 각각의 유저와 일대다 관계를 맺는다.
그리고 채용공고와 이력서는 지원이라는 테이블을 사이에 두고 다대다관계를 맺는다.
내가 맡게 된 역할
- 검색(필터링)
- 이력서 CRUD
- 직군별 연봉
- 태그와 카테고리, 직군과 직종
- 유저 정보
협업 방식
이번 협업의 핵심 포인트는 스케줄링, 데일리 스탠드업 미팅, 그리고 API 문서화였다.
스케줄링
우선 우리 팀은 노션을 이용해서 스케줄링했다.
진행전, 진행중, PR staging, 완료 목록을 각각의 팀원이 업데이트 해주고, 그걸 한 눈에 볼 수 있도록 했다.
기능별로 카드를 구분했고, 각각의 기능을 누가 맡고 있는지 명시해뒀다.
스탠드업 미팅을 포함해서 거의 모든 미팅은 스케줄링을 참고하여 진행했다.
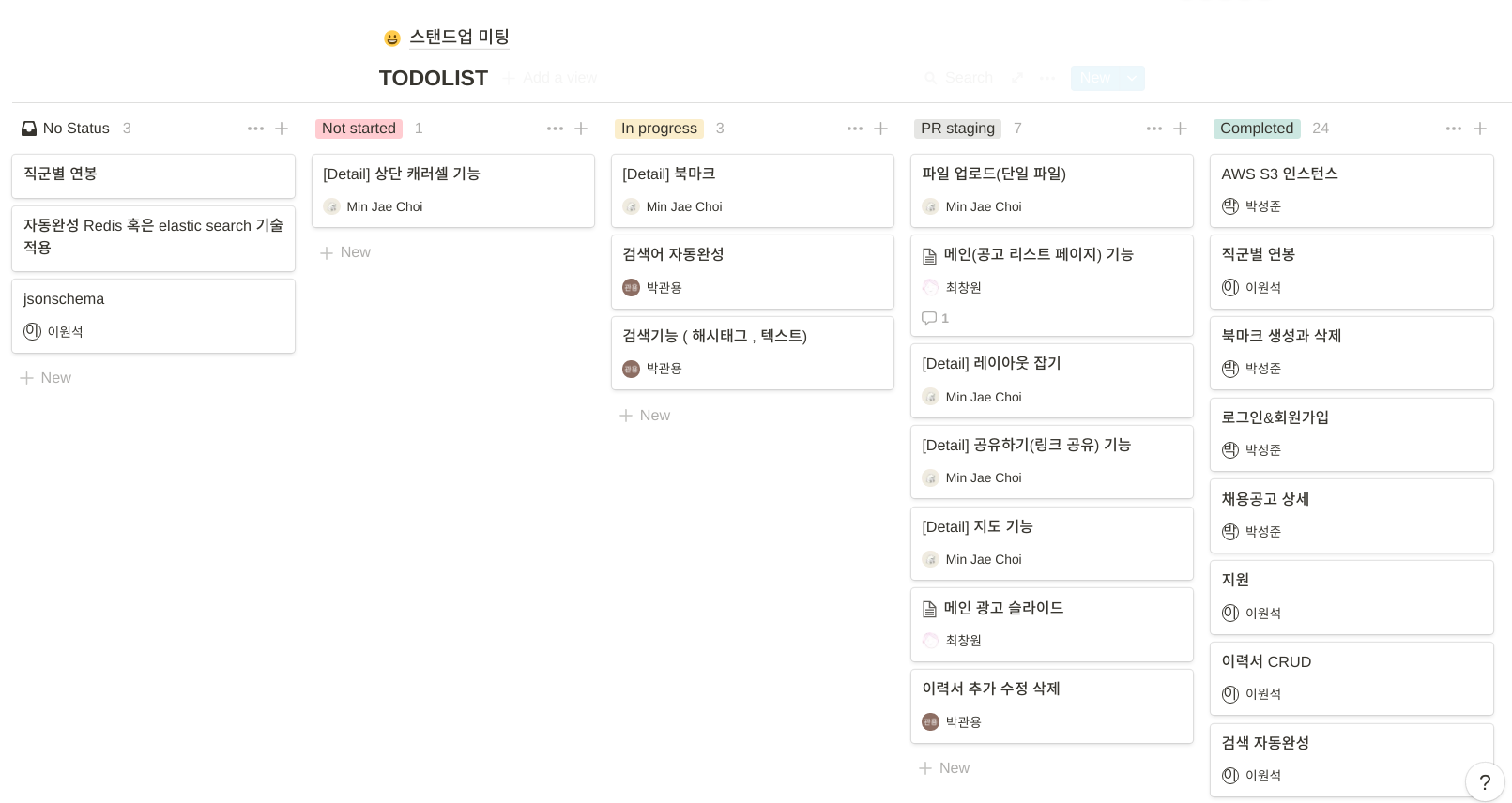
스탠드업 미팅
날마다 각 팀원이 어제 한 일, 오늘 할 일, blocker을 정리했다. 스케줄링 기능에서 자세히 표현할 수 없는 부분을 중점적으로 썼다. 일단 미팅에서는 각자의 진행과정을 말하면서 서로의 진행상황을 알 수 있어 좋았다. 그리고 각자가 정리하는 과정에서 의문들과 급하게 해결해야 할 부분들이 정리되기도 해서 좋았다.

POSTMAN API 문서화
백엔드와 프론트엔드가 서로 말을 맞춰야 할 것들중, 가장 중요한 정보는 API, 즉 통신에 대한 서로의 약속이라고 생각한다. 1차 프로젝트를 진행할 때엔 API가 중간에 바뀌어서 서로 혼동이 생기거나, 애초에 서로가 인식하지 못하는 경우가 많이 발생했다.

그래서 차용한 것이 POSTMAN 문서화이다. 문서화로 정리한 정보는 다음과 같다.
- URI가 어떤 형태인가
- 프론트단에서 어떤 데이터를 줘야 하는가 : headers, path parameter, query parameter 등
- 백엔드에서 어떤 응답을 줄 것인가
- 기타 기록할 내용
프론트쪽에서 mock data를 만들어 테스트할 때에도 수월하게 진행됐고, 백엔드쪽에선 매번 따로 전달할 필요가 없으니 코딩에만 집중할 수 있었다.
잘한 점
우선 백엔드 두 명이서 API를 완성했다는 점이 뿌듯했다. (고생하셔씁니다 성준님!) 그리고 적은 인원으로도 작업을 빨리 처리할 수 있었던 원인은 빠른 우선순위 판단에 있었다고 생각한다.
빠른 우선순위 판단
일단 기획 단계에서 우선순위에서 밀리는 사항들에 대해 욕심을 크게 부리지 않았기 때문에 모델링이 비교적 수월하게 진행되었고, 따라서 프로젝트 진행기간 동안 migration이 충돌되거나 DB를 삭제해야 할 경우가 많이 없었다.
또한 역할분담이 확실하되, 유동적으로 이루어졌다. 경험 범위 내에 있는 태스크에 대해서는 확실하게 결정하되, 경험 범위 밖에 있는 (예를 들면 S3를 이용한 파일 첨부, 직군별 연봉 등) 태스크들은 상황에 따라 역할 분배할 수 있도록 했다.
API 문서화
1차때는 몰랐는데, POSTMAN이 정말 좋은 툴이었구나, 느꼈다.
API를 테스팅해보는 것이 중심이기는 하지만, 그 응답결과를 바로바로 save버튼 하나로 온라인으로 공유할 수 있다는 점이 정말 편했다.
그러면 하나하나의 함수가 완성될 때마다 프론트엔드쪽에선 실제 응답결과를 볼 수 있어 안심하고 fetch함수를 쓸 수 있다.
그 외에도 URI와 기타 정보에 대해서 나중에 혼동이 생길 일이 없어 좋았다.
빠른 AWS 배포
1주차에 완성된 필수기능 코드들을 짜집기해서 branch 관리를 했고, 멘토링을 받지 않아 불확실한 버전이기는 하지만 일단 URI와 응답결과는 프론트엔드분들과의 약속과 같기 때문에, 아예 AWS에 배포해서 서버를 켜두었다.
그 결과 주말에 따로 만나지 않고도 프론트엔드 분들은 서버 테스팅을 할 수 있었고, 백엔드는 나머지 기능 구현에 집중할 수 있었다.
이때 branch 버전관리의 맛(?)을 조금이나마 알게 된 것 같다. 완성된 코드를 merge하고, 테스팅한 뒤의 고칠 코드는 또 다시 수정하는 사이클.
ORM 최적화
django를 쓰는 사람으로서 너무 당연한 얘기일 수는 있지만, ORM 최적화에 신경을 썼고 쿼리문의 횟수와 속도를 개선할 수 있었다. 20번 이상 날라갈 쿼리문을 select_related와 prefetch_related를 이용해서 1번으로 단축시켰고, annotate 와 JOIN개념을 응용해서 단축시키기도 했다.
갓병민님의 ORM 최적화 & 부하테스트 세션을
아쉬운 점
소통은 아직 어렵다.
같은 백엔드끼리도, 프론트엔드끼리도 소통은 정말 어려웠다.
일이 꼬이지 않게 하는 것이 일을 빠르게 하는 것보다 중요하다는 것을 알게 됐다. 미팅 때 나눈 이야기와 약속들은 그대로 일에 적용되어야 한다. 그러나 나는 기획단계에 결정된 (인간적으로 기획 단계가 짧기는 했다..) 사항에 대한 문제제기를 이틀 뒤에 한 적도 있다. 팀원분들은 이해는 해주셨지만, 이미 역할분담이 끝난 일에 대해 의문을 던지는 것은 다른 사람에게 피해를 줄 수 있겠다는 생각을 했다.
맡게 된 프로젝트의 기한이 짧을수록, 미팅 때 집중력과 순발력을 발휘해서 빠르고 정확한 의견제기를 하는 것이 생명이겠다는 생각이 든다.
그리고 기본적인 의사소통의 문제. A를 B라고 전달하거나, A를 B로 이해하는 경우가 있었다.
사람들이 공통적으로 이해할 수 있는 언어를 쓰고, 사람들의 말을 이해할 수 있는 능력을 기르는 것이 아직 내가 넘어야 할 큰 산이다.
jsonschema
JSONField를 써서 테이블은 줄였는데, 타입 체킹을 하지 못했다. django Model에서 모델마다 정의하는 Field의 타입은 해당 column의 데이터 타입을 만들고, 실제로 그 타입에 맞지 않는 데이터가 들어갈 경우 에러를 발생시킨다. 그 결과로 DB 테이블을 만드는 동시에 각 column에 대한 데이터 타입을 정할 수 있다.
그러나 JSONField는 너무나 자유롭다. 안에 들어갈 데이터 타입이 JSON 그 이상 그 이하도 아니기 때문에, 안에 숫자가 들어가든 배열이 들어가든 DB는 불평하지 않는다. 이는 나중에 데이터를 관리할 때 문제를 야기할 수 있다.
그래서 JSONField에 들어갈 데이터에 대해 타입을 체크하는 모듈인 jsonschema를 알아봤는데, 이번 프로젝트에선 시간 부족으로 쓰지 못했다.
검색어 자동완성
이름은 자동완성이지만, 사실상 자동완성이 아닌 수동완성이었다. 이름이 일치하는 데이터를 filter하는게 끝이다. 멘토링을 받은 결과, 진짜 자동완성은 머신러닝을 시킨 뒤에 머신이 자동적으로 인풋을 조합해 단어를 완성시키는 것이 자동완성이라는 사실을 알게 됐다.
언젠가 elastic search를 사용해서 머신러닝을 구현해보고 싶다.
부하테스트
ORM 최적화는 해놓고 아직 부하테스트를 한번도 안해봤다. 얼른 해봐야지!

원석님 2차 마무리까지 고생하셨습니다 👏🏻👏🏻👏🏻
앞으로 남은 기간 심력, 체력 관리도 뽜이링 ✨