채팅 서비스에서 욕설 필터링은 필수아니겠습니까?
단순히 차단을 하기 보다는 메이플스토리 인게임 욕설 필터링과 최대한 유사한 금칙어 변환 로직을 구현해보았습니다.
1. 어떤 알고리즘을 쓸까?
| 알고리즘 | 특징 | 시간 복잡도 (텍스트 길이 = N, 패턴 길이 = M, 패턴 개수 = k) | 비고 |
|---|---|---|---|
| 순회(Brute Force) | 모든 위치에서 모든 패턴을 하나씩 비교 | O(N × M × k) | 단순하지만 비효율적 |
| KMP | 불일치 시 “실패 함수”로 점프 | O(N + M) | 하지만 단일 패턴에만 적용 가능 |
| Trie | 여러 패턴을 동시에 관리 | O(N × L) (L = 한 글자당 평균 경로 길이) | 다패턴 가능하지만 불일치 처리 비효율적 |
| Aho–Corasick | Trie + KMP 실패 함수 | O(N + ΣM) (ΣM = 모든 패턴 길이 합) | 텍스트 한 번 스캔으로 다패턴 검색 가능 |
처음에는 단순하게 문자열을 하나씩 순회(Brute Force)하거나, 패턴 검색으로 유명한 KMP 알고리즘을 떠올렸습니다. KMP 방식은 단일 패턴 매칭에는 적합하나, 금칙어가 수백, 수천 개로 늘어나면 효율이 급격히 떨어집니다.
다음으로 생각한 것은 Trie 자료구조입니다. 여러 금칙어 패턴을 동시에 관리할 수 있어 효율적이지만, 불일치 처리(실패 시 원점 복귀)가 비효율적이었습니다.
그래서.. 문자열 매칭 알고리즘을 더 찾아본 결과, Trie 기반으로 발전된 Aho–Corasick 알고리즘이 가장 적절했습니다.
아호코라식(Aho–Corasick) 이란?
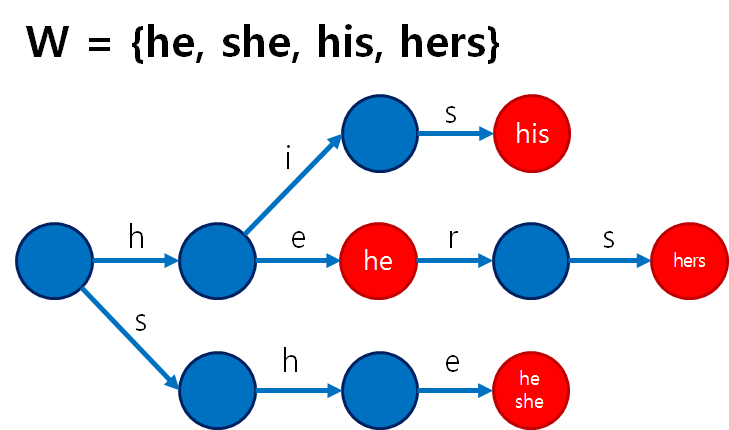
현재 광범위하게 알려진 거의 유일한 일대다 패턴매칭 알고리즘으로 Trie 기반으로 작동한다. 여러 패턴을 동시에 관리하기 위해 Trie(접두사 트리)를 구성하기 때문이다.
KMP(일대일 패턴 매칭 알고리즘)는 불일치가 발생했을 때, “실패 함수(failure function)”를 통해 다시 "처음으로 돌아가지 않고 적절한 위치로 점프"한다는 아이디어가 핵심이다.
Aho–Corasick은 이 실패 함수 개념을 Trie 전체에 일반화하여 각 노드마다 “실패 시 어디로 이동할지”를 미리 계산해두고, 입력 텍스트를 한 번만 스캔하면서 여러 패턴을 동시에 탐색할 수 있다.
즉, KMP + Trie를 통한 일대다 패턴매칭 최적화 알고리즘.
왜 Aho–Corasick이 더 빠른가?
- KMP
- 장점: O(N+M) 보장, 단일 패턴 검색에서 최적 → O(N + M)
- 단점: "여러 패턴"을 동시에 찾으려면 최악의 경우 패턴 수만큼 KMP를 반복해야 함 → O(k × N)
- Aho–Corasick
- 장점: Trie로 "여러 패턴"을 한꺼번에 관리, 실패시 링크로 점프
- 결과: 모든 패턴을 동시에 검색해도 시간 복잡도는 O(N + ΣM)
- 즉, “패턴 개수에 선형적으로 반복”하지 않고 한 번의 스캔으로 모두 처리
2. 구현 방식
직접 알고리즘을 처음부터 구현하기 보다는, 이미 잘 만들어진 라이브러리를 활용했습니다.
2-1. curse.json
해당 json 파일에 금칙어 그룹을 정의했습니다.
2-2. BadWordFilter.class (도메인 정책)
@Service
public class BadWordFilter {
// Aho–Corasick Trie 구조체
private Trie trie;
// 매칭된 키워드를 치환어로 바꾸기 위한 매핑 테이블
private final Map<String, String> keywordToReplacement = new HashMap<>();
@PostConstruct
public void init() throws Exception {
// 1. curse.json 파일 로드
ObjectMapper mapper = new ObjectMapper();
InputStream is = getClass().getClassLoader()
.getResourceAsStream("curse.json");
// 2. {치환어: [욕설1, 욕설2...]} 형태를 Map으로 파싱
Map<String, List<String>> rawMap = mapper.readValue(is, new TypeReference<>() {});
// 3. Trie 빌더 생성
Trie.TrieBuilder builder = Trie.builder();
// 4. JSON에서 읽은 각 치환어 그룹을 Trie에 추가
for (Map.Entry<String, List<String>> entry : rawMap.entrySet()) {
String replacement = entry.getKey(); // 치환어
for (String keyword : entry.getValue()) {
// Trie에 욕설 키워드 등록
builder.addKeyword(keyword);
// 나중에 대체할 때 쓰기 위해 매핑 저장
keywordToReplacement.put(keyword, replacement);
}
}
// 5. Trie 완성 (겹치는 매칭은 무시)
trie = builder.ignoreOverlaps().build();
}
public String filter(String input) {
// 1. 입력 텍스트에서 모든 매칭 구간 추출
Collection<Emit> emits = trie.parseText(input);
// 2. 인덱스 변형 방지를 위해 뒤에서부터 처리
List<Emit> sorted = new ArrayList<>(emits);
sorted.sort((a, b) -> b.getStart() - a.getStart());
// 3. StringBuilder로 원본 수정
StringBuilder sb = new StringBuilder(input);
for (Emit emit : sorted) {
String keyword = emit.getKeyword();
String replacement = keywordToReplacement.get(keyword);
// 매칭된 범위를 치환어로 교체
sb.replace(emit.getStart(), emit.getEnd() + 1, replacement);
}
return sb.toString();
}
}2-3. 알고리즘 적용 구간
입력 텍스트에서 모든 매칭 구간 추출
Collection<Emit> emits = trie.parseText(input);input = "미친놈아"
keyword = "미친"input 문자열 전체를 처음부터 끝 까지 스캔하며, 미리 등록한 금칙어(Tire)에 매칭된다면 시작 인덱스와 끝 인덱스 정보를 Emit 객체로 반환합니다.
ex) Emit(start=0, end=1, keyword="미친")
인덱스 변형 방지를 위해 뒤에서부터 처리
List<Emit> sorted = new ArrayList<>(emits);
sorted.sort((a, b) -> b.getStart() - a.getStart());이렇게 매칭된 금칙어 인덱스 정보를 담은 Emit 객체를 역순으로 정렬합니다. (왜 역순으로 정렬하지?)
만약 앞에서부터 매칭을 하게되면 어떤일이 발생할까요?
input = "미친놈아"
0. 욕설 매핑
- 미친 → 이상한
- 놈 → 아이
1. 정순인 경우
Emit(start=0, end=1, keyword="미친") -> "이상한놈아"
Emit(start=2, end=2, keyword="놈") -> "이상아이놈아"
- 기대했던 값: "이상한아이아"
- 결과 값: "이상아이놈아"
2. 역순인 경우
Emit(start=2, end=2, keyword="놈") -> "미친아이아"
Emit(start=0, end=1, keyword="미친") -> "이상한아이아"
- 기대했던 값: "이상한아이아"
- 결과 값: "이상한아이아"위와 같이 정순으로 금칙어 변환 시, 다음 Emit 객체의 변환이 적절하지 않은 위치에서 발생할 수 있습니다.
최종 변환
StringBuilder sb = new StringBuilder(input);
for (Emit emit : sorted) {
String keyword = emit.getKeyword();
String replacement = keywordToReplacement.get(keyword);
sb.replace(emit.getStart(), emit.getEnd() + 1, replacement);
}3. 전체 흐름 요약
1. 초기화 (@PostConstruct)
- curse.json에서 {치환어: [욕설 리스트]}를 읽어옴.
- Trie에 욕설 키워드를 등록하고, 해당 키워드가 어떤 치환어로 바뀌는지 Map에 저장.
- 최종적으로 Aho–Corasick Trie를 완성.
2. 실행 (filter 메서드)
- 입력 텍스트를 Trie로 스캔 → 모든 욕설 키워드 위치(Emit)를 찾음.
- 인덱스 꼬임 방지를 위해 뒤에서부터 치환.
- 최종적으로 욕설이 치환어로 바뀐 문자열 반환.
4. 마무리
그동안 알고리즘은 주로 코딩테스트 문제 풀이용으로만 접했는데, 이번에는 실제 프로젝트에 직접 적용해볼 수 있었습니다. Dijkstra, DFS/BFS, 분리집합, MST 같은 탐색 알고리즘은 당장 프로젝트에 활용하기가 쉽지 않았지만, 문자열 매칭 알고리즘은 실시간 채팅 서비스라는 테마와 맞아떨어졌습니다.
요즘 점점 코딩테스트 난이도가 어려워지는데.. 앞으로도 단순히 문제 풀이에 그치지 않고 적절하게 알고리즘을 사용하는 경험을 더 쌓아가보고 싶다는 생각을 할 수 있는 경험이었습니다.
참고문헌
아호코라식(Aho-Corasick)
