본 내용은 원티드 프리온보딩 과정을 회고하는 목적으로 작성되었습니다.이번 게시물은 데이터베이스 샤딩을 통한 성능 개선에 관련한 내용입니다.
1-11. 데이터베이스 규모 확장 - sharding
데이터베이스 서버를 분산해도 데이터가 계속 증가하게 되면 하나의 서버나 데이터베이스 인스턴스가 처리하기 어려운 상황이 올 수 있습니다. 이 경우 데이터베이스의 규모를 확장하는 Scale Out(수직적 규모 확장), Scale Up(수평적 규모 확장) 두 가지 방법이 있습니다.
Scale Up의 방식은 하드웨어의 한계성 때문에 하나의 서버에서 모든 데이터, 트랜잭션을 처리하는 것은 I/O 병목현상, CPU 사용률 증가, 메모리 부족, SPOF, 고비용 등 다양한 한계가 있습니다.
Scale Out (Sharding)
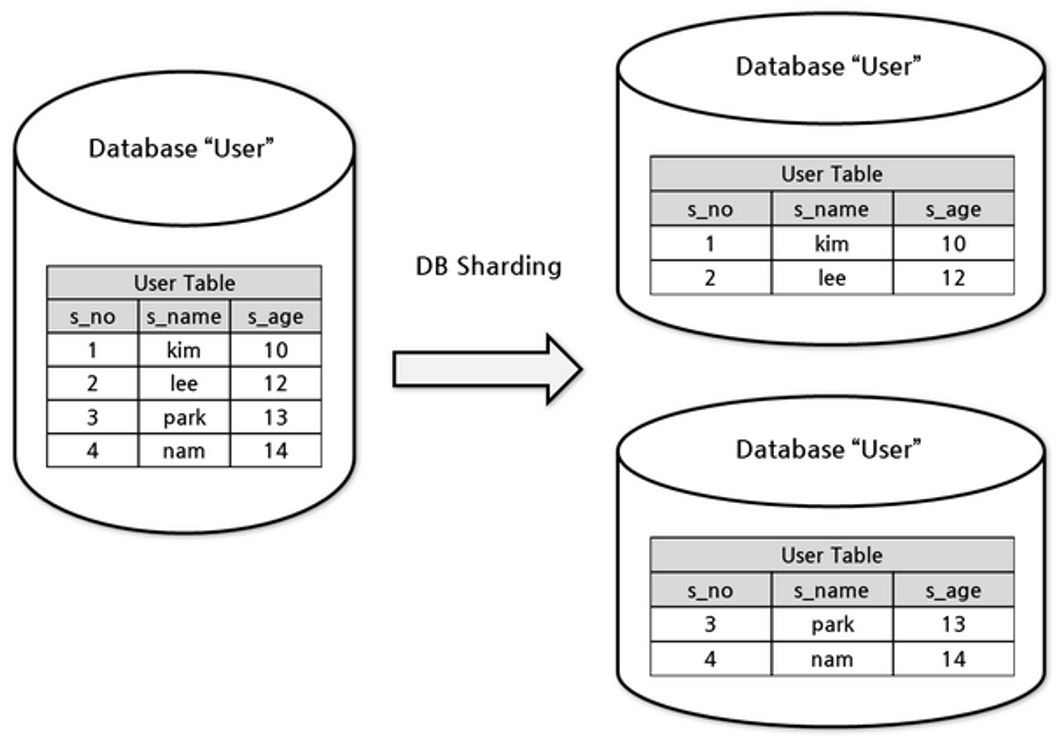
Sharding은 테이블을 수평으로 잘라 파티셔닝하는 것을 의미하며 Scale Out의 방법 중 하나입니다.
구체적으로는 대규모 데이터베이스를 여러 개의 더 작은 독립적인 데이터베이스로 나누는 기술을 의미하며, 이렇게 나누어진 작은 데이터베이스들을 Shard 라고 합니다.
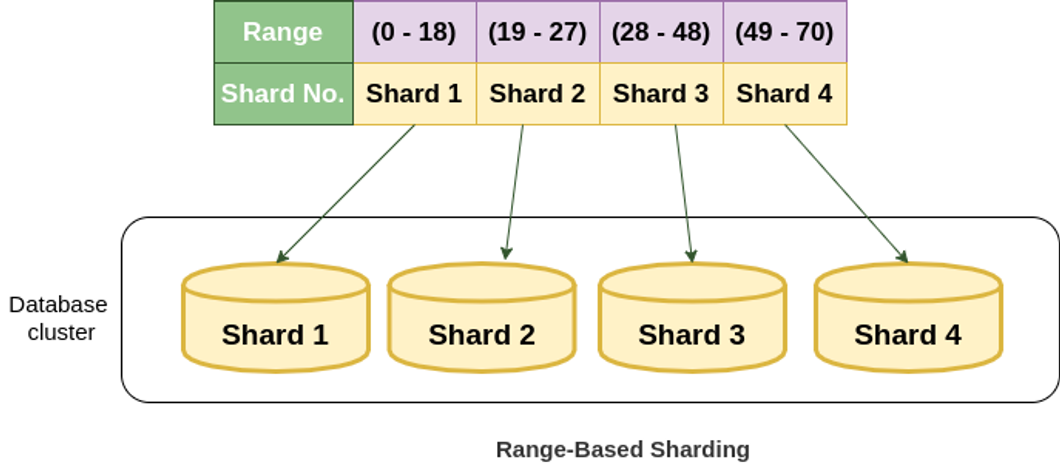
대표적인 샤드 분할 방식에는 범위 샤딩(Range-based-sharding)이 있습니다.
고려해야 할 점
Sharding은 데이터베이스의 규모를 확장하는 기술이지만 완벽하지 않고, 시스템의 복잡도가 증가하는 단점이 있습니다.
하나의 데이터베이스를 여러 샤드로 분리하게 되면 Join 작업이 더 복잡해집니다. 이를 해소하기 위한 방법들을 알아보겠습니다.
글로벌 조인(Global Join)
글로벌 조인은 다른 샤드 간의 테이블을 Join 하는 경우를 의미합니다.
- 방출 조인 (BroadCast Join)
작은 테이블을 상대적으로 큰 테이블의 모든 샤드에 복제하여 각 샤드에서 로컬 조인을 수행하는 방식입니다. 이 방법은 작은 참조 테이블이 있는 경우에 유용합니다.
주문 테이블 > 제품 정보 테이블
방출 조인의 경우, 상대적으로 작은 제품 정보 테이블의 데이터를 모든 주문 테이블의 샤드에 복제하여 각 주문 샤드에서 로컬 조인을 수행합니다.
- 병합 조인 (Merge Join)
두 테이블은 이미 키 기준으로 정렬되어 있을 때 사용하는 방법으로, 각 샤드에서 정렬된 데이터 를 가져와 병합하며 조인합니다.
정렬된 연관관계가 있는 두 테이블
병합 조인의 경우, 주문과 제품정보 테이블을 제품의 ID를 기준으로 정렬 합니다.
제품정보 테이블의 데이터 스트림: 1, 2, 3
주문 테이블의 데이터 스트림: 1, 2, 2, 3, 3, 3
각 데이터를 비교하며 조인 키가 일치하는 경우 조인 작업을 수행합니다.
(주문1-제품정보1, 주문2-제품정보2, 주문2-제품정보2...)
- 해시 조인 (Hash Join)
큰 테이블의 일부 데이터를 메모리의 해시 테이블에 로드하여 조인하는 방식입니다.
주문 테이블 > 제품 정보 테이블
해시 조인의 경우, 상대적으로 작은 제품 정보 테이블의 조인 키를 해시 테이블로 생성합니다. 일반적으로 크기가 작은 테이블(제품 정보 테이블)을 선택하는 것이 효율적입니다.
해시 테이블:
해시 값 | 제품 정보
해시1 | 제품1
해시2 | 제품2
해시3 | 제품3
그 다음, 주문 테이블의 조인 키인 제품ID에 해시 함수를 적용하여 해시 값을 생성하고, 해시 테이블에서 일치하는 고객의 정보를 찾습니다.
(주문1-제품정보1, 주문2-제품정보2, 주문2-제품정보2...)
조인 키를 기준으로 데이터가 정렬되어야 하는 병합 조인에 비해 해시 함수를 사용하기 때문에 더 빠르게 동작하는 장점이 있습니다.
따라서 데이터의 특성과 사용 사례에 따라 병합 조인 또는 해시 조인을 선택하면 됩니다.
비정규화(de-normalization)
정규화 된 연관관계가 있는 데이터베이스를 비정규화하여 하나의 테이블에서 질의가 수행될 수 있도록 합니다. 추후 포스팅을 통해 자세하게 다루도록 하겠습니다.
참고문헌
원티드 교육자료
