
📌 "Kafka CDC를 활용해서 ETL서비스 구현해볼래요?"
이전 프로젝트에서는 Spring의 스케줄링을 활용하여 polling 방식으로 ETL 서비스를 개발했습니다. 이때 polling 방식의 한계로 많은 불편을 겪었고, 팀 내부적으로 다른 기술 스택을 고민하다 Kafka를 도입하기로 결정했습니다.
메시징 큐 서비스(Kafka, MQTT, RabbitMQ 등)에 대해 이론적으로 알고 있었지만, 실제 프로젝트에 적용해본 경험은 없었습니다. 시행착오가 많겠지만, 열심히 공부하고 개발 과정을 기록하면서 점차 개선해나가겠습니다.
구현해야하는 요구사항
개발 중인 MES(생산 관리 시스템)에서는 ERP(전사적 자원 관리) 데이터의 변경 사항을 통합하여 관리할 수 있어야 한다는 요구가 있습니다.
📌 ETL?CDC?가 무엇인가요?
🤔 ETL 서비스란?
ETL은 데이터를 소스에서 추출(Extract), 변환(Transform), 그리고 최종적으로 데이터 저장소에 로드(Load)하는 과정을 말합니다. 이 세 가지 주요 단계를 통해 데이터는 분석, 보고, 데이터 기반 의사 결정 지원 등 다양한 용도로 활용될 수 있습니다.
데이터 변환/통합 프로세스는 다음과 같이 세 단계로 구성됩니다.
- 추출: 원본 데이터베이스 또는 데이터 소스에서 소스 데이터를 가져오는 과정입니다. ETL에서는 데이터가 임시 스테이징 영역으로 이동합니다. ELT의 경우, 데이터는 직접 데이터 레이크 스토리지 시스템으로 들어갑니다.
- 변환: 정보의 구조를 변경하여 대상 데이터 시스템 및 해당 시스템의 나머지 데이터와 통합할 수 있도록 하는 과정입니다.
- 로드: 정보를 데이터 저장소에 보관하는 과정입니다.
🤔 CDC 란?
CDC는 데이터베이스의 변경을 실시간으로 감지하고 캡처하는 기술입니다. 이를 통해 데이터베이스의 삽입, 수정, 삭제 등 이벤트를 실시간으로 추적하고 이를 다른 시스템으로 전달할 수 있습니다. Kafka와 CDC를 결합하면 대량의 데이터를 실시간으로 ETL 시스템으로 통합할 수 있습니다.
- Kafka와 CDC를 사용한 아키텍처(by debezium.io/documentation)
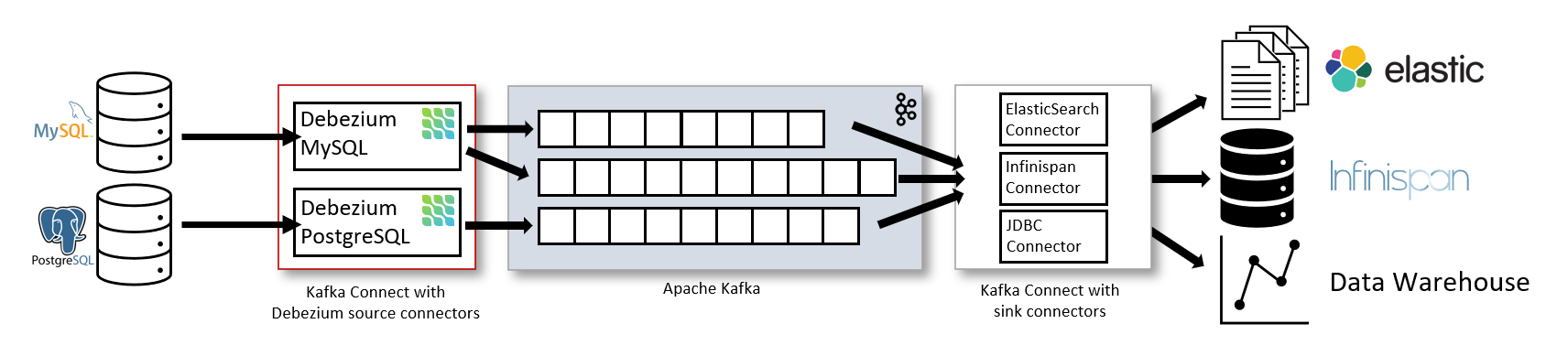
- 데이터 소스 설정: 데이터베이스(예: PostgreSQL, MySQL 등)에 연결합니다.
- CDC Connector 사용: Kafka Connect와 함께 CDC 플러그인(예: Debezium)을 설정하여 데이터베이스의 변경을 감지하고 Kafka 토픽으로 전송합니다.
- 데이터 스트리밍 처리: Kafka Streams 또는 KSQL을 사용하여 스트림 데이터를 실시간으로 변환, 집계 또는 필터링합니다.
- 데이터 로드: 변환된 데이터를 최종 목적지(데이터 웨어하우스, 애널리틱스 플랫폼 등)로 로드합니다.
📌 메시징 큐의 3가지 핵심요소
메시징 큐 서비스들은 Kafka, RabbitMQ, MQTT, AWS SQS와 같은 서비스를 포함하여 주로 세 가지 요소로 구성됩니다.
- Producer (생산자): 데이터를 생성하고 메시지 큐에 전달하는 역할을 합니다. 데이터를 생성하는 애플리케이션, 시스템 또는 사용자가 될 수 있습니다.
- 메시지 큐 (Queue): Producer로부터 받은 메시지들을 일시적으로 저장하는 중간 저장소입니다. 이 큐는 메시지를 순차적으로 관리하며, Consumer가 준비될 때까지 메시지를 보관합니다.
- Consumer (소비자): 메시지 큐로부터 메시지를 검색하고 처리하는 역할을 합니다. 준비가 되면 큐에서 메시지를 가져와 필요한 작업을 수행합니다. Consumer는 한 번에 하나의 메시지만 처리하거나 여러 메시지를 동시에 처리할 수 있습니다.
ETL 서비스 구현 과정
- 변경을 감지할 대상 DB에서 변경사항이 발생합니다.
- Producer가 이를 감지하여 변경된 데이터를 메시지 큐에 저장합니다.
- Consumer가 메시지 큐에 저장된 데이터를 감지하여 변경사항을 반영할 DB에 반영합니다.
📌 어떻게 Kafka CDC를 활용하였는가?
메시지 큐 역할을 하는 Broker, Zookeeper
Kafka에서 메시지 큐의 역할을 하는 서비스는 Broker와 Zookeeper입니다. Broker는 Kafka 시스템의 서버로, 데이터 스트림을 처리하고 저장합니다. Zookeeper는 Kafka 클러스터의 구성 관리와 조정을 담당합니다. 자세한 동작 방식은 복잡하므로 다음에 따로 설명하겠습니다. (공부를 덜 해서 그런건 절대 아님 크흠)
Producer 역할을 하는 Debezium Connector
데이터 베이스의 변경사항을 감지하여 변경사항을 제공할 Producer를 구현해야합니다. Kafka에서 이를 위한 라이브러리가 여러가지 있는데 JDBC Sink Connector, debezium Connector 등이 있습니다.
JDBC Sink Connector는 Polling 방식으로 동작하게되어 데이터 베이스에 새로운 데이터가 들어오게되면(INSERT 동작이 이루어지면) 이를 확인하여 Producing하게 됩니다. 하지만 수정, 삭제에 대한 변경사항은 Polling방식의 한계로인해 감지를 하지 못합니다. 처음에 이것도 모르고 수정, 삭제에 대해서 변경감지를 하지 않지... 하면서 삽질했었습니다...하하
Debezium Connector는 데이터베이스의 트랜잭션 로그를 모니터링하여 데이터베이스에 발생하는 모든 변경사항(삽입, 수정, 삭제)을 실시간으로 캡처하고, 이를 Producing할 수 있습니다. JDBC Sink Connector와 달리 데이터베이스에 CDC활성화를 위한 추가적인 설정일 필요하긴하지만 삽입, 수정, 삭제에 대한 변경사항도 감지하기위해 Debezium Connector를 사용하기로 하였습니다.
Consumer 는 Spring Boot 서비스를 사용
먼저 Kafka에서는 메시지 큐, 데이터와 같은 용어를 아래와 같이 사용합니다.
- 토픽(Topic): 관련 데이터를 분류하고 저장하는 논리적 단위입니다.
- 파티션(Partition): 토픽의 데이터를 물리적으로 나누어 저장하며 병렬 처리를 가능하게 합니다.
- 레코드(Record): 실제 데이터가 저장되는 형태로, 키와 값, 타임스탬프를 포함할 수 있습니다.
간단한게 메시지 큐가 토픽이고, 저장되는 데이터를 레코드라고 생각하시면 됩니다.
=> 위 용어에 대한 자세한 설명을 하면 너무 길어지기 때문에 추후에 포스팅 하겠습니다.
Consumer는 Spring Boot를 사용하여 토픽에서 레코드를 받아 이를 핸들링하고 DB에 저장합니다. Kafka Sink Connector를 사용하여 코드를 작성하지 않고도 Consuming이 가능하나 데이터의 필터링과 가공을 위해 Spring Boot를 선택했습니다.
➡️ 다음으로
지금까지 개념적인 내용에 대해 작성하였습니다. 다음 포스팅에 구현한 코드에 대해 설명하겠습니다.
