Claude 쿼리 입력
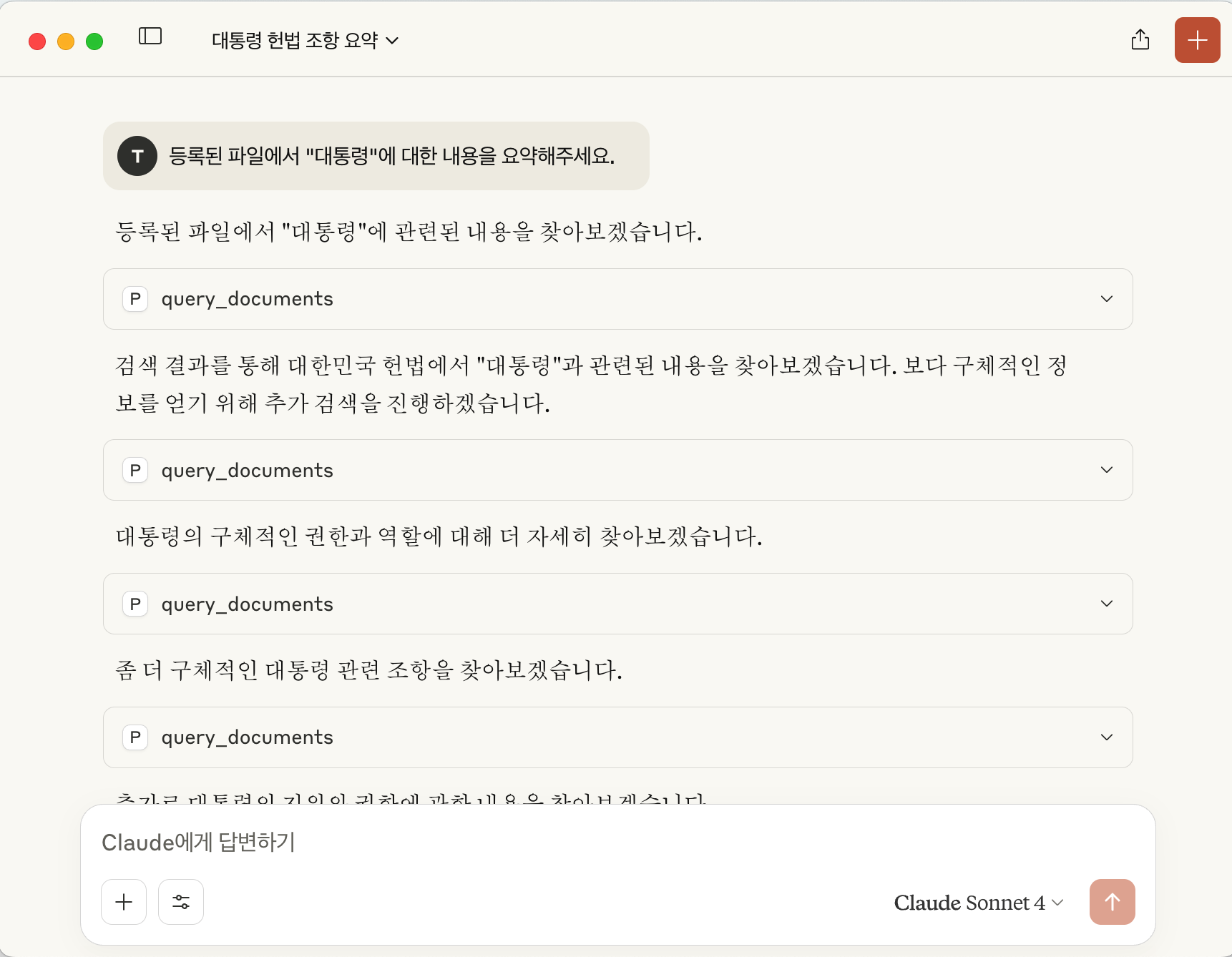
Claude 결과
MCP 코드
# uv 사용법 관련 정리 필요 (250703)
# source .venv/bin/activate # venv 가상환경
# uv pip install fastmcp
# uv pip install sentence_transformers
# uv pip install pdfminer.six
# uv add pdfminer.six
# python docReader.py 를 실행하여 가상환경 설치 내역 확인 (250703)
from mcp.server.fastmcp import FastMCP
import traceback
from sentence_transformers import SentenceTransformer
import os
import chromadb
import numpy as np
import re
from pathlib import Path
# pdfminer.six 관련 import
from pdfminer.high_level import extract_text
from pdfminer.layout import LAParams
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.pdfpage import PDFPage
from pdfminer.converter import TextConverter
#from pdfminer.pdfparser import PDFParser, PDFDocument # 이 부분 에러, 아래와 같이 분할
# https://stackoverflow.com/questions/56023686/error-cannot-import-name-pdfdocument-from-pdfminer-pdfparser
from pdfminer.pdfparser import PDFParser
from pdfminer.pdfdocument import PDFDocument
from pdfminer.pdfpage import PDFPage
#######################################################
from pdfminer.pdfdocument import PDFEncryptionError
from io import StringIO
mcp = FastMCP("docreader")
# 임베딩 모델
model = SentenceTransformer("all-MiniLM-L6-v2")
def get_embeddings(chunks):
return model.encode(chunks)
# 벡터DB (ChromaDB)
chroma_client = chromadb.Client()
collection = chroma_client.get_or_create_collection("pdf_chunks")
def build_or_load_index(chunks):
"""벡터 인덱스 구축 또는 로드"""
if not chunks:
return collection, []
vectors = get_embeddings(chunks)
ids = [f"chunk_{i}" for i in range(len(chunks))]
# 기존 컬렉션 완전 초기화
try:
chroma_client.delete_collection("pdf_chunks")
collection = chroma_client.create_collection("pdf_chunks")
except:
pass
collection.add(
documents=chunks,
embeddings=vectors,
ids=ids
)
return collection, chunks
def search_similar_chunks(query, collection, chunks, top_k=5):
"""유사한 청크 검색"""
if not chunks:
return []
q_vec = get_embeddings([query])[0]
results = collection.query(query_embeddings=[q_vec], n_results=min(top_k, len(chunks)))
return results['documents'][0] if results['documents'] else []
def extract_text_from_pdf(file_path):
"""PDF에서 텍스트 추출 (pdfminer.six 사용)"""
try:
if not os.path.exists(file_path):
print(f"[오류] 파일이 존재하지 않습니다: {file_path}")
return ""
# 방법 1: 간단한 텍스트 추출 (대부분의 경우 사용)
try:
text = extract_text(file_path)
if text and text.strip():
return text
except PDFEncryptionError:
print(f"[오류] PDF가 암호화되어 있습니다: {file_path}")
return ""
except Exception as e:
print(f"간단한 추출 실패, 고급 추출 시도: {e}")
# 방법 2: 고급 텍스트 추출 (레이아웃 분석 포함)
try:
output_string = StringIO()
with open(file_path, 'rb') as file:
# LAParams로 레이아웃 분석 설정
laparams = LAParams(
line_margin=0.5,
word_margin=0.1,
char_margin=2.0,
box_margin=0.5,
detect_vertical=False
)
resource_manager = PDFResourceManager()
device = TextConverter(resource_manager, output_string, laparams=laparams)
interpreter = PDFPageInterpreter(resource_manager, device)
# 각 페이지 처리
for page in PDFPage.get_pages(file, check_extractable=True):
interpreter.process_page(page)
device.close()
text = output_string.getvalue()
output_string.close()
return text
except PDFEncryptionError:
print(f"[오류] PDF가 암호화되어 있습니다: {file_path}")
return ""
except Exception as e:
print(f"고급 추출도 실패: {e}")
return ""
except Exception as e:
print(f"PDF 읽기 오류 ({file_path}): {e}")
return ""
def extract_text_from_pdf_with_pages(file_path):
"""PDF에서 페이지별 텍스트 추출 (디버깅용)"""
try:
if not os.path.exists(file_path):
print(f"[오류] 파일이 존재하지 않습니다: {file_path}")
return ""
all_text = ""
with open(file_path, 'rb') as file:
# PDF 파싱
parser = PDFParser(file)
document = PDFDocument(parser)
# 암호화 확인
if document.is_extractable == False:
print(f"[오류] PDF에서 텍스트 추출이 불가능합니다: {file_path}")
return ""
# 레이아웃 분석 매개변수
laparams = LAParams(
line_margin=0.5,
word_margin=0.1,
char_margin=2.0,
box_margin=0.5,
detect_vertical=False
)
resource_manager = PDFResourceManager()
# 각 페이지별로 텍스트 추출
for page_num, page in enumerate(PDFPage.create_pages(document)):
output_string = StringIO()
device = TextConverter(resource_manager, output_string, laparams=laparams)
interpreter = PDFPageInterpreter(resource_manager, device)
try:
interpreter.process_page(page)
page_text = output_string.getvalue()
if page_text.strip():
all_text += f"\n--- 페이지 {page_num + 1} ---\n"
all_text += page_text
print(f"페이지 {page_num + 1}: {len(page_text)} 문자 추출")
else:
print(f"페이지 {page_num + 1}: 텍스트 없음")
except Exception as e:
print(f"페이지 {page_num + 1} 처리 실패: {e}")
finally:
device.close()
output_string.close()
return all_text
except PDFEncryptionError:
print(f"[오류] PDF가 암호화되어 있습니다: {file_path}")
return ""
except Exception as e:
print(f"PDF 읽기 오류 ({file_path}): {e}")
return ""
def split_into_chunks(text, chunk_size=300):
"""텍스트를 청크로 분할 (개선된 버전)"""
if not text.strip():
return []
# 문장 단위로 분할 (마침표, 느낌표, 물음표 기준)
sentences = re.split(r'[.!?]\s+', text)
chunks = []
current_chunk = ""
for sentence in sentences:
sentence = sentence.strip()
if not sentence:
continue
# 현재 청크에 문장을 추가했을 때 크기 확인
potential_chunk = current_chunk + " " + sentence if current_chunk else sentence
if len(potential_chunk) <= chunk_size:
current_chunk = potential_chunk
else:
# 현재 청크가 있으면 저장
if current_chunk:
chunks.append(current_chunk.strip())
# 새 청크 시작
if len(sentence) <= chunk_size:
current_chunk = sentence
else:
# 문장이 너무 길면 강제로 분할
words = sentence.split()
temp_chunk = ""
for word in words:
if len(temp_chunk + " " + word) <= chunk_size:
temp_chunk = temp_chunk + " " + word if temp_chunk else word
else:
if temp_chunk:
chunks.append(temp_chunk.strip())
temp_chunk = word
current_chunk = temp_chunk
# 마지막 청크 추가
if current_chunk:
chunks.append(current_chunk.strip())
return [chunk for chunk in chunks if chunk.strip()]
def extract_file_path_from_query(query):
"""쿼리에서 파일 경로 추출"""
# 절대 경로 패턴 매칭 (예: /Users/... 또는 C:\...)
absolute_path_pattern = r'(/[^\s]+\.pdf|[A-Za-z]:[^\s]+\.pdf)'
# 상대 경로 패턴 매칭 (예: ./docs/file.pdf, ../file.pdf, docs/file.pdf)
relative_path_pattern = r'(\.{0,2}/[^\s]+\.pdf|[^\s/]+/[^\s]+\.pdf|[^\s]+\.pdf)'
absolute_match = re.search(absolute_path_pattern, query)
if absolute_match:
return absolute_match.group(1)
relative_match = re.search(relative_path_pattern, query)
if relative_match:
return relative_match.group(1)
return None
def find_pdf_files(search_dirs=None, specific_path=None):
"""PDF 파일 찾기 (특정 경로 우선, 여러 디렉토리 검색) - 수정된 버전"""
pdf_files = []
# 특정 경로가 지정된 경우 우선 처리
if specific_path:
# 절대 경로가 아닌 경우 상대 경로로 처리
if not os.path.isabs(specific_path):
# 현재 작업 디렉토리에서 찾기
current_dir_path = os.path.join(os.getcwd(), specific_path)
if os.path.exists(current_dir_path) and current_dir_path.lower().endswith('.pdf'):
pdf_files.append(os.path.abspath(current_dir_path))
print(f"지정된 PDF 파일 발견: {current_dir_path}")
return pdf_files
# 다양한 기본 디렉토리에서 찾기
base_dirs = [
"/Users/wontaelee/Downloads/claude_filesystem_MCP",
"/Users/wontaelee/Downloads/My_MCP_Server/docReader",
os.getcwd()
]
for base_dir in base_dirs:
test_path = os.path.join(base_dir, specific_path)
if os.path.exists(test_path) and test_path.lower().endswith('.pdf'):
pdf_files.append(os.path.abspath(test_path))
print(f"지정된 PDF 파일 발견: {test_path}")
return pdf_files
else:
# 절대 경로 처리
if os.path.exists(specific_path) and specific_path.lower().endswith('.pdf'):
pdf_files.append(os.path.abspath(specific_path))
print(f"지정된 PDF 파일 발견: {specific_path}")
return pdf_files
print(f"지정된 경로를 찾을 수 없습니다: {specific_path}")
# 기본 디렉토리들에서 검색 - 수정된 경로 목록
if search_dirs is None:
search_dirs = [
"/Users/wontaelee/Downloads/claude_filesystem_MCP/docs",
"/Users/wontaelee/Downloads/My_MCP_Server/docReader/docs",
os.path.join(os.getcwd(), "docs"),
"docs/",
"./",
"../",
"uploads/"
]
for dir_path in search_dirs:
# 상대 경로를 절대 경로로 변환
if not os.path.isabs(dir_path):
dir_path = os.path.abspath(dir_path)
if os.path.exists(dir_path) and os.path.isdir(dir_path):
try:
for file in os.listdir(dir_path):
if file.lower().endswith(".pdf"):
full_path = os.path.join(dir_path, file)
pdf_files.append(os.path.abspath(full_path))
print(f"PDF 파일 발견: {full_path}")
except PermissionError:
print(f"디렉토리 접근 권한 없음: {dir_path}")
continue
return pdf_files
def find_pdf_files_recursive(root_path):
"""재귀적으로 PDF 파일 검색"""
pdf_files = []
try:
if not os.path.exists(root_path):
print(f"검색 경로가 존재하지 않습니다: {root_path}")
return pdf_files
for root, dirs, files in os.walk(root_path):
for file in files:
if file.lower().endswith('.pdf'):
full_path = os.path.join(root, file)
pdf_files.append(os.path.abspath(full_path))
print(f"PDF 파일 발견: {full_path}")
except Exception as e:
print(f"재귀 검색 중 오류: {e}")
return pdf_files
def load_and_chunk_documents(search_dirs=None, specific_path=None):
"""문서 로드 및 청킹"""
pdf_files = find_pdf_files(search_dirs, specific_path)
# 기본 검색에서 파일을 찾지 못한 경우 재귀 검색 시도
if not pdf_files and not specific_path:
print("기본 디렉토리에서 PDF를 찾을 수 없어 재귀 검색을 시도합니다...")
search_paths = [
"/Users/wontaelee/Downloads/claude_filesystem_MCP",
"/Users/wontaelee/Downloads/My_MCP_Server/docReader",
os.getcwd()
]
for search_path in search_paths:
if os.path.exists(search_path):
pdf_files = find_pdf_files_recursive(search_path)
if pdf_files:
break
if not pdf_files:
print("PDF 파일을 찾을 수 없습니다.")
print(f"현재 작업 디렉토리: {os.getcwd()}")
print("검색된 디렉토리:")
test_dirs = [
"/Users/wontaelee/Downloads/claude_filesystem_MCP/docs",
"/Users/wontaelee/Downloads/My_MCP_Server/docReader/docs",
os.path.join(os.getcwd(), "docs")
]
for test_dir in test_dirs:
exists = os.path.exists(test_dir)
print(f" - {test_dir}: {'존재함' if exists else '존재하지 않음'}")
if exists:
try:
files = os.listdir(test_dir)
pdf_files_in_dir = [f for f in files if f.lower().endswith('.pdf')]
print(f" PDF 파일: {pdf_files_in_dir}")
except Exception as e:
print(f" 디렉토리 읽기 오류: {e}")
return []
all_chunks = []
for file_path in pdf_files:
print(f"처리 중: {file_path}")
raw_text = extract_text_from_pdf(file_path)
if raw_text.strip():
chunks = split_into_chunks(raw_text)
all_chunks.extend(chunks)
print(f" - {len(chunks)}개 청크 생성")
else:
print(f" - 텍스트 추출 실패")
print(f"총 {len(all_chunks)}개 청크 생성됨")
return all_chunks
# Tool 등록
@mcp.tool(name="query_documents", description="PDF 문서를 검색하고 Claude에 질문을 전달합니다.")
def query_documents(query: str) -> str:
try:
print(f"[질문] {query}")
print(f"[현재 작업 디렉토리] {os.getcwd()}")
# 쿼리에서 파일 경로 추출 시도
specific_path = extract_file_path_from_query(query)
if specific_path:
print(f"추출된 파일 경로: {specific_path}")
# 문서 로드
docs = load_and_chunk_documents(specific_path=specific_path)
if not docs:
return "오류 발생: PDF 파일을 찾을 수 없습니다. 파일 경로를 확인하거나 docs/, ./, ../, uploads/ 디렉토리에 파일을 배치해주세요."
collection, chunks = build_or_load_index(docs)
results = search_similar_chunks(query, collection, chunks)
if not results:
return "관련 문서를 찾을 수 없습니다."
prompt_response = "\n".join([
"다음 문단을 참고하여 질문에 답해주세요:\n",
*[f"- {chunk}" for chunk in results],
f"\n질문: {query}"
])
return prompt_response
except Exception as e:
error_msg = f"오류 발생: {str(e)}"
print(error_msg)
traceback.print_exc()
return error_msg
if __name__ == "__main__":
mcp.run()
Hello, I'm Terry! 👋 Enjoy every moment of your life! 🌱 My current interests are Signal processing, Machine learning, Python, Database, LLM & RAG, MCP & ADK, Multi-Agents, Physical AI, ROS2...