결론 A4B 모델을 사용하려면 충분한 GPU RAM을 구축해야 한다...
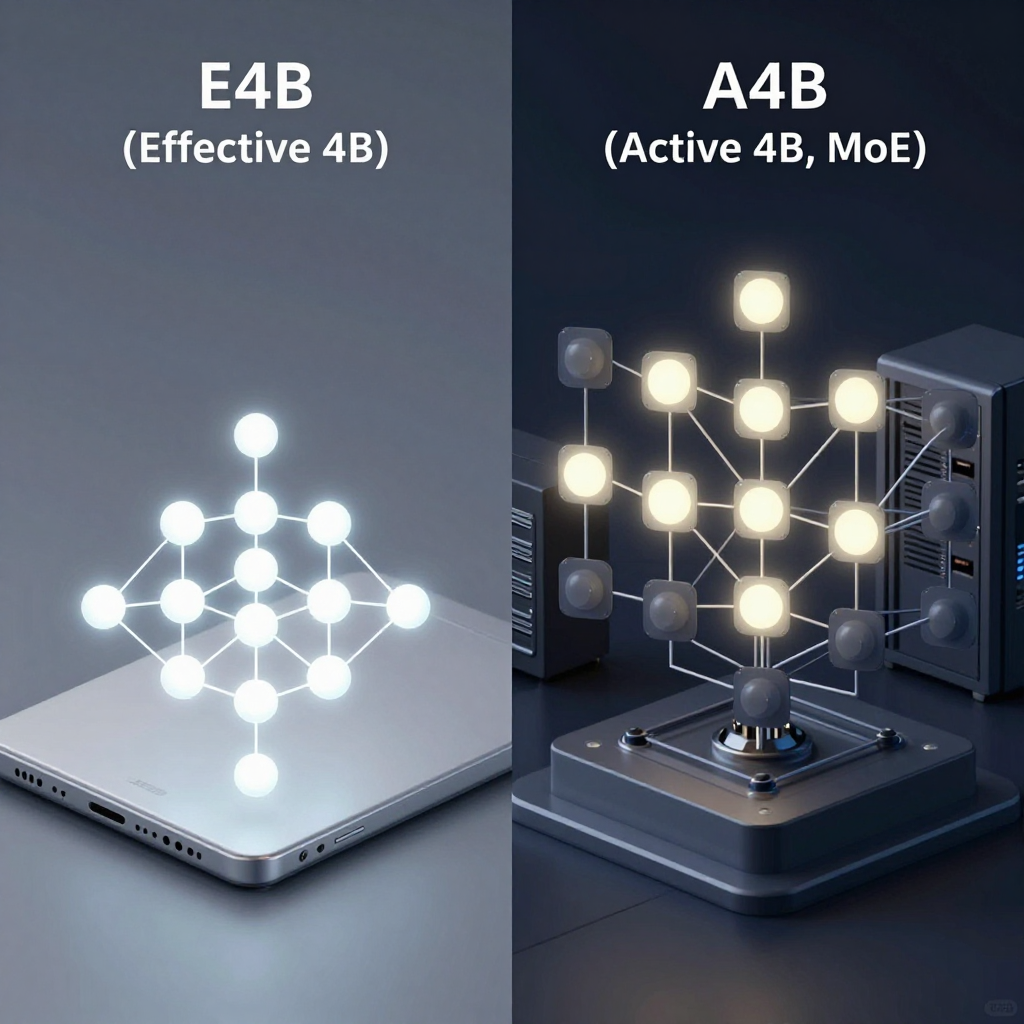
Gemma 4 라인업에서 정의한 “모델 구성 방식”을 의미합니다.
즉, 같은 4B라도 “어떻게 4B를 쓰느냐”의 차이입니다.
- E4B (Effective 4B) → 진짜로 4B짜리 모델
- A4B (Active 4B) → 26B 모델인데, 실행 시 4B만 활성화
👉 둘 다 “4B처럼 동작”하지만
E4B는 작아서 4B / A4B는 크지만 4B만 사용
1. E4B (Effective 4B)
구조
- 전체 파라미터 ≈ 4B
- Dense 모델 (일반적인 Transformer)
특징
- 모든 파라미터가 항상 사용됨
- 구조 단순
- 모바일/엣지 최적화
장점
- 메모리 사용 적음
- 배포 쉬움 (폰, 라즈베리파이 등)
- latency 안정적
단점
- 모델 자체가 작아서 성능 한계 존재
👉 한 줄
“작고 가볍게, 항상 동일하게 동작하는 4B 모델”
2. A4B (Active 4B) – MoE 구조
구조
- 전체 파라미터 ≈ 26B
- Mixture of Experts (MoE) 모델
동작 방식
- 여러 개의 “expert” 네트워크 존재
- 입력마다 일부 expert만 활성화됨
- 실제로 계산에 쓰이는 파라미터 ≈ 4B
핵심 포인트
-
전체는 26B지만
-
매 토큰마다:
- 일부 expert만 선택됨
- → 계산량은 4B 수준
장점
- 4B 계산량으로 26B급 표현력 일부 확보
- 복잡한 reasoning, 수학, 추론에 강함
- 성능 대비 효율 매우 좋음
단점
- 구조 복잡
- GPU/워크스테이션 필요
- latency 변동 가능
👉 한 줄
“큰 모델을 갖고 있지만, 똑똑하게 일부만 써서 빠르게 동작”
직관적인 비유
E4B
- 👨💻 “혼자 일하는 전문가 1명 (능력 = 4B)”
A4B
- 👨💻👩💻👨🔬👩🔬 (26명 팀)
- 근데 매번 4명만 투입
- 상황에 따라 다른 전문가 선택
성능 차이가 나는 이유
A4B가 더 강한 이유:
- 다양한 expert → 다양한 패턴 학습
- 문제별로 “전문가 선택”
- sparse activation → 효율 유지
요약 (중요)
| 항목 | E4B | A4B |
|---|---|---|
| 실제 크기 | 4B | 26B |
| 실행 시 사용 | 4B | 4B |
| 구조 | Dense | MoE |
| 타겟 | 모바일 / 엣지 | 고성능 추론 |
| 성능 | 제한적 | 훨씬 강함 |
| 복잡도 | 낮음 | 높음 |
한 줄 결론
E4B는 “작아서 빠른 모델”,
A4B는 “큰 모델을 똑똑하게 줄여서 빠르게 쓰는 모델”
E4B vs A4B의 “실제 GPU 메모리 사용”을 현실적으로 비교해보겠습니다.
핵심은 “총 파라미터”가 아니라 “동시에 GPU에 올라가야 하는 양”입니다.
1️⃣ 전제: 무엇이 GPU 메모리를 먹는가
LLM 추론 시 메모리는 크게 3가지:
- 모델 weight (가장 큼)
- KV cache (컨텍스트 길이에 비례)
- 중간 activation (일시적, 상대적으로 적음)
2️⃣ E4B (Effective 4B) 메모리
예: Gemma 4 E4B
✔️ Weight 메모리
- 4B parameters
| 정밀도 | 메모리 |
|---|---|
| FP16 | ~8GB |
| INT8 | ~4GB |
| INT4 | ~2GB |
👉 즉:
노트북 GPU (RTX 3060 8GB)에서도 충분히 가능
✔️ KV cache (예: 4K context)
대략:
- ~1 ~ 2GB 추가
✔️ 총합
| 환경 | 총 메모리 |
|---|---|
| FP16 | ~10GB |
| INT4 | ~3~4GB |
3️⃣ A4B (Active 4B, MoE) 메모리
예: Gemma 4 26B A4B
여기서 중요한 포인트 👇
❗ “계산은 4B지만, weight는 26B 전체가 필요”
✔️ Weight 메모리 (핵심)
- 전체 파라미터: 26B
| 정밀도 | 메모리 |
|---|---|
| FP16 | ~52GB |
| INT8 | ~26GB |
| INT4 | ~13GB |
👉 즉:
단일 소비자 GPU로는 거의 불가능 (분산 or 고급 GPU 필요)
✔️ 왜 다 올려야 할까?
Mixture of Experts 구조 때문
- 매 토큰마다 어떤 expert 쓸지 runtime에 결정
- → 모든 expert weight 접근 가능해야 함
즉:
- “안 쓰는 expert라도 GPU 메모리에는 있어야 함”
✔️ KV cache
E4B와 거의 동일:
- ~1~2GB
(이건 active parameter 기준이라 차이 없음)
✔️ 총합
| 환경 | 총 메모리 |
|---|---|
| FP16 | ~55GB |
| INT4 | ~15GB |
4️⃣ 핵심 비교 (진짜 중요한 부분)
| 항목 | E4B | A4B |
|---|---|---|
| 총 파라미터 | 4B | 26B |
| 활성 파라미터 | 4B | 4B |
| GPU 메모리 | 작음 | 매우 큼 |
| 실행 요구사항 | 개인 GPU | 서버급 GPU |
| 계산량 | 낮음 | 낮음 (비슷) |
| 메모리 병목 | 없음 | 매우 큼 |
5️⃣ 직관적 결론
👉 많은 사람들이 착각하는 부분:
❌ “A4B는 4B만 쓰니까 메모리도 4B겠지?”
✅ “아니다. 메모리는 26B급, 계산만 4B급”
6️⃣ 실제 운영 시 시나리오
✔️ E4B
- 노트북 GPU
- 모바일
- 온디바이스 AI
✔️ A4B
- RTX 4090 단독 → ❌ (부족)
- RTX 4090 2장 이상 → ⚠️ 가능
- A100 / H100 → ✅
7️⃣ 한 줄 요약
E4B = 메모리도 4B
A4B = 계산은 4B, 메모리는 26B

Hello, I'm Terry! 👋 Enjoy every moment of your life! 🌱 My current interests are Signal processing, Machine learning, Python, Database, LLM & RAG, MCP & ADK, Multi-Agents, Physical AI, ROS2...