데이터의 힘 : 나 자신의 모든 것에 대한 꾸준한 기록을 통하여 나 자신도 몰랐던 나를 알 수 있는 작은 프로젝트를 진행해봤다.
Claude 실행 결과
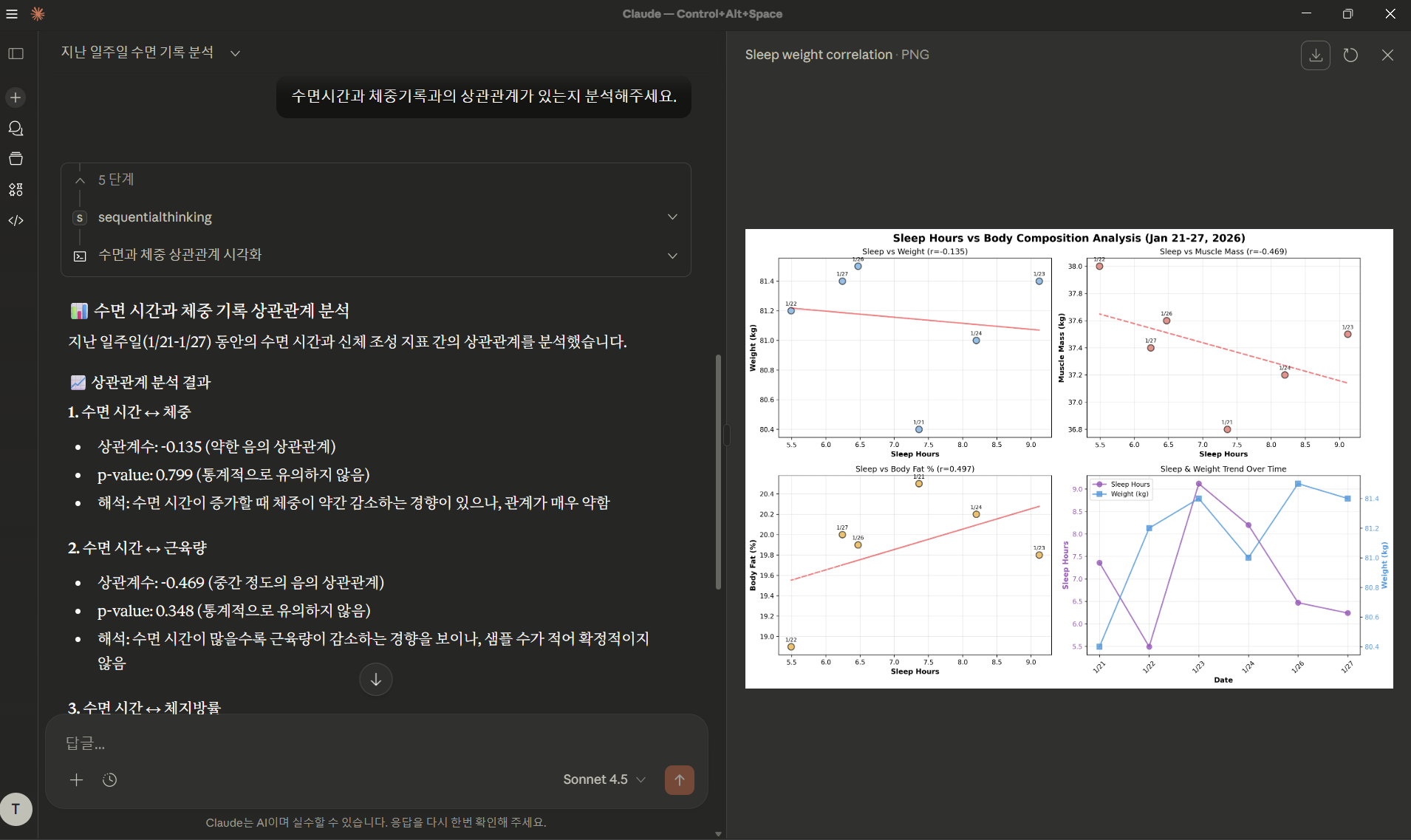
1) 수면 기록 분석
Mongodb_MCP를 이용하여 지난 일주일 간의 수면 기록을 분석해주세요
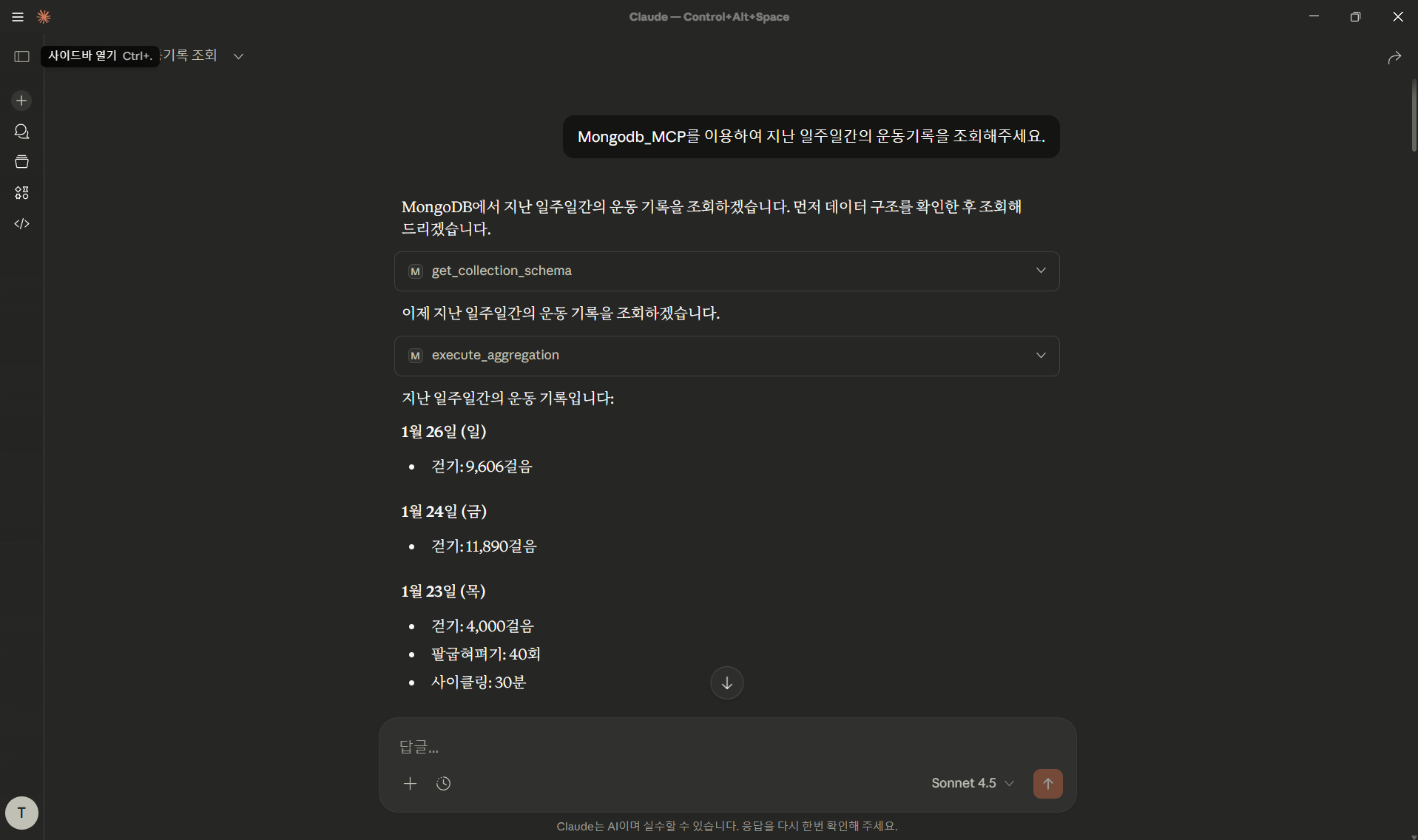
2) 운동 기록 조회
Mongodb_MCP를 이용하여 지난 일주일간의 운동기록을 조회해주세요.
MongoDB : DailyLog Schema
MongoDB를 이용하여 일기쓰듯 DailyLog를 기록하였다. 하루에 있었던 나에 대한 모든 것에 대한 것을 Schema의 내용에 포함시키는 것이 목표다. 향후 MongoDB의 이점인 확장성을 통하여 기록 방법을 개선해나갈 생각이다.
DAILYLOG_SCHEMA = {
"collection": "DailyLog",
"database": "TerryDB",
"description": "일일 건강 및 활동 로그",
"fields": {
"date": {
"type": "date",
"description": "기록 날짜"
},
"sleep": {
"type": "object",
"fields": {
"hours": {"type": "float"},
"quality": {"type": "string"}
}
},
"inbody": {
"type": "object",
"fields": {
"weight": {"type": "float"},
"muscle": {"type": "float"},
"fatper": {"type": "float"}
}
},
"study": {
"type": "array",
"items": {
"subject": {"type": "string"},
"minutes": {"type": "int"}
}
},
"bloodpressure": {
"type": "object",
"fields": {
"systolic": {"type": "int"},
"diastolic": {"type": "int"},
"bpm": {"type": "int"}
}
},
"expenses": {
"type": "array",
"items": {
"category": {"type": "string"},
"amount": {"type": "float"}
}
},
"exercise": {
"type": "array",
"items": {
"subject": {"type": "string"},
"steps": {"type": "int", "optional": True},
"count": {"type": "int", "optional": True}
}
},
"food": {
"type": "array",
"items": {
"type": {"type": "string"},
"menu": {"type": "string"}
}
},
"mood": {
"type": "string"
}
}
}
MongoDB Aggregation MCP Server
Claude에 연결하여 사용할 MCP는 다음과 같다.
#!/usr/bin/env python3
"""
MongoDB Aggregation MCP Server
DailyLog 컬렉션에 대한 Aggregation Query를 실행하는 MCP 서버
"""
import json
import os
from datetime import datetime
from typing import Any, Sequence
from bson import ObjectId
from dotenv import load_dotenv
from pymongo import MongoClient
from pymongo.errors import ConnectionFailure, OperationFailure
from mcp.server import Server
from mcp.types import Tool, TextContent
import mcp.server.stdio
# 환경변수 로드
load_dotenv()
# MongoDB 연결 설정
MONGODB_URI = os.getenv("MONGODB_URI", "mongodb://localhost:27017/")
DATABASE_NAME = "TerryDB"
COLLECTION_NAME = "DailyLog"
# DailyLog 스키마 정의 (수정 : 260128, ChatGPT 스키마 수정)
DAILYLOG_SCHEMA = {
"collection": "DailyLog",
"database": "TerryDB",
"description": "일일 건강 및 활동 로그",
"fields": {
"date": {
"type": "date",
"description": "기록 날짜"
},
"sleep": {
"type": "object",
"fields": {
"hours": {"type": "float"},
"quality": {"type": "string"}
}
},
"inbody": {
"type": "object",
"fields": {
"weight": {"type": "float"},
"muscle": {"type": "float"},
"fatper": {"type": "float"}
}
},
"study": {
"type": "array",
"items": {
"subject": {"type": "string"},
"minutes": {"type": "int"}
}
},
"bloodpressure": {
"type": "object",
"fields": {
"systolic": {"type": "int"},
"diastolic": {"type": "int"},
"bpm": {"type": "int"}
}
},
"expenses": {
"type": "array",
"items": {
"category": {"type": "string"},
"amount": {"type": "float"}
}
},
"exercise": {
"type": "array",
"items": {
"subject": {"type": "string"},
"steps": {"type": "int", "optional": True},
"count": {"type": "int", "optional": True}
}
},
"food": {
"type": "array",
"items": {
"type": {"type": "string"},
"menu": {"type": "string"}
}
},
"mood": {
"type": "string"
}
},
"example_queries": [
{
"description": "지난 7일 평균 수면 시간",
"pipeline": [
{"$match": {"date": {"$gte": "2026-01-19"}}},
{"$group": {"_id": None, "avg_sleep": {"$avg": "$sleep.hours"}}}
]
},
{
"description": "카테고리별 총 지출",
"pipeline": [
{"$unwind": "$expenses"},
{"$group": {"_id": "$expenses.category", "total": {"$sum": "$expenses.amount"}}},
{"$sort": {"total": -1}}
]
},
{
"description": "과목별 총 공부 시간",
"pipeline": [
{"$unwind": "$study"},
{"$group": {"_id": "$study.subject", "total_minutes": {"$sum": "$study.minutes"}}},
{"$sort": {"total_minutes": -1}}
]
}
]
}
# MongoDB 클라이언트 초기화
mongo_client = None
db = None
collection = None
def initialize_mongodb():
"""MongoDB 연결 초기화"""
global mongo_client, db, collection
try:
mongo_client = MongoClient(MONGODB_URI, serverSelectionTimeoutMS=5000)
# 연결 테스트
mongo_client.admin.command('ping')
db = mongo_client[DATABASE_NAME]
collection = db[COLLECTION_NAME]
print(f"MongoDB 연결 성공: {DATABASE_NAME}.{COLLECTION_NAME}")
except ConnectionFailure as e:
print(f"MongoDB 연결 실패: {e}")
raise
def serialize_mongo_result(obj: Any) -> Any:
"""MongoDB 결과를 JSON 직렬화 가능한 형태로 변환"""
if isinstance(obj, ObjectId):
return str(obj)
elif isinstance(obj, datetime):
return obj.isoformat()
elif isinstance(obj, dict):
return {key: serialize_mongo_result(value) for key, value in obj.items()}
elif isinstance(obj, list):
return [serialize_mongo_result(item) for item in obj]
else:
return obj
# MCP 서버 생성
app = Server("mongodb-aggregation-server")
@app.list_tools()
async def list_tools() -> list[Tool]:
"""사용 가능한 도구 목록 반환"""
return [
Tool(
name="get_collection_schema",
description=f"Get the schema and structure information for the {COLLECTION_NAME} collection in {DATABASE_NAME} database. "
"Returns field definitions, types, descriptions, and example queries. "
"Use this tool first to understand the data structure before creating aggregation queries.",
inputSchema={
"type": "object",
"properties": {},
"required": []
}
),
Tool(
name="execute_aggregation",
description=f"Execute a MongoDB aggregation pipeline on the {COLLECTION_NAME} collection. "
"Accepts a pipeline as a JSON array of aggregation stages. "
"Common stages include: $match, $group, $sort, $project, $unwind, $limit, $skip. "
"Returns the aggregation results. "
"Always use get_collection_schema first to understand the data structure.",
inputSchema={
"type": "object",
"properties": {
"pipeline": {
"type": "array",
"description": "MongoDB aggregation pipeline as an array of stage objects. "
"Example: [{'$match': {'date': {'$gte': '2026-01-01'}}}, {'$group': {'_id': null, 'avg': {'$avg': '$sleep.hours'}}}]",
"items": {
"type": "object"
}
},
"limit": {
"type": "number",
"description": "Maximum number of results to return (default: 100, max: 1000)",
"default": 100
}
},
"required": ["pipeline"]
}
)
]
@app.call_tool()
async def call_tool(name: str, arguments: Any) -> Sequence[TextContent]:
"""도구 실행"""
if name == "get_collection_schema":
try:
# 스키마 정보 반환
schema_info = json.dumps(DAILYLOG_SCHEMA, indent=2, ensure_ascii=False)
# 추가로 실제 컬렉션 통계 정보 제공
stats = {
"document_count": collection.count_documents({}),
"sample_document": None
}
# 샘플 문서 조회 (최신 1개)
sample = collection.find_one(sort=[("date", -1)])
if sample:
stats["sample_document"] = serialize_mongo_result(sample)
result = {
"schema": DAILYLOG_SCHEMA,
"statistics": stats
}
return [TextContent(
type="text",
text=f"DailyLog Collection Schema and Information:\n\n{json.dumps(result, indent=2, ensure_ascii=False)}"
)]
except Exception as e:
return [TextContent(
type="text",
text=f"Error retrieving schema: {str(e)}"
)]
elif name == "execute_aggregation":
try:
pipeline = arguments.get("pipeline", [])
limit = min(arguments.get("limit", 100), 1000) # 최대 1000개로 제한
if not isinstance(pipeline, list):
return [TextContent(
type="text",
text="Error: pipeline must be an array of aggregation stages"
)]
# limit 스테이지 추가 (결과 크기 제한)
pipeline_with_limit = pipeline + [{"$limit": limit}]
# Aggregation 실행
results = list(collection.aggregate(pipeline_with_limit))
# 결과 직렬화
serialized_results = serialize_mongo_result(results)
response = {
"success": True,
"pipeline": pipeline,
"result_count": len(results),
"results": serialized_results
}
return [TextContent(
type="text",
text=json.dumps(response, indent=2, ensure_ascii=False)
)]
except OperationFailure as e:
return [TextContent(
type="text",
text=f"MongoDB operation failed: {str(e)}\nPlease check your aggregation pipeline syntax."
)]
except Exception as e:
return [TextContent(
type="text",
text=f"Error executing aggregation: {str(e)}"
)]
else:
return [TextContent(
type="text",
text=f"Unknown tool: {name}"
)]
async def main():
"""서버 실행"""
# MongoDB 초기화
initialize_mongodb()
# MCP 서버 실행
async with mcp.server.stdio.stdio_server() as (read_stream, write_stream):
await app.run(
read_stream,
write_stream,
app.create_initialization_options()
)
if __name__ == "__main__":
import asyncio
asyncio.run(main())
Hello, I'm Terry! 👋 Enjoy every moment of your life! 🌱 My current interests are Signal processing, Machine learning, Python, Database, LLM & RAG, MCP & ADK, Multi-Agents, Physical AI, ROS2...