완성된 단일 프롬프트
역할
당신은 데이터 보정 및 시계열 신호 합성에 능숙한 Python 엔지니어입니다.
아래 요구사항을 모두 만족하는 하나의 완성된 Python 스크립트를 작성하세요.
입력 데이터
입력 파일:
Test.csvCSV 구조:
- 첫 번째 열은 라벨 컬럼 (
Value_A,Value_B)- 나머지 열 이름 중 숫자로 해석 가능한 컬럼만 시간(Time) 컬럼
- 각 시간 컬럼의 값은 실수
목표
Value_B를 수정하여Value_B_after를 생성한다.- 수정된
Value_B_after는Value_A를 기준으로 각 시간별 오차가 항상 ±TOL 이내여야 한다.- 오차는 시간별로 랜덤하지만 연속성이 있어 그래프가 매끈하게 보이도록 생성한다.
- 랜덤 오차는 white noise가 아니라 저주파 성분을 가진 correlated noise여야 한다.
- 오차는 특정 값으로 수렴하거나 고정되지 않아야 한다.
구간 조건
- 시간(
Time)이LOW = 100이상HIGH = 1000이하인 구간에서만 보정을 수행한다.- 해당 구간 외의 값은 기존
Value_B를 그대로 유지한다.
오차 생성 규칙 (중요)
전체 시간 길이에 대해 정규분포 랜덤 노이즈를 생성한다.
rolling mean을 이용해 부드러운 연속 랜덤 신호로 만든다.
반드시 보정 구간(mask) 기준으로 재정규화하여
|Value_B_after - Value_A| ≤ TOL이 100% 보장되도록 한다.부동소수점 오차로 인해 조건이 깨지지 않도록 안전하게 구현한다.
상수
LOW = 100 HIGH = 1000 TOL = 0.014 RANDOM_SEED = 42
출력 파일
Test_updated.csv
- 원본 CSV 형식 유지
Value_B행만 수정된 값으로 교체
Test_transposed.csv
- 컬럼:
Time,Value_A,Value_B
Test_change_log.csv
컬럼:
TimeValue_AValue_B_beforeValue_B_afterError_before(B-A)Error_after(B-A)
Test_plot.png
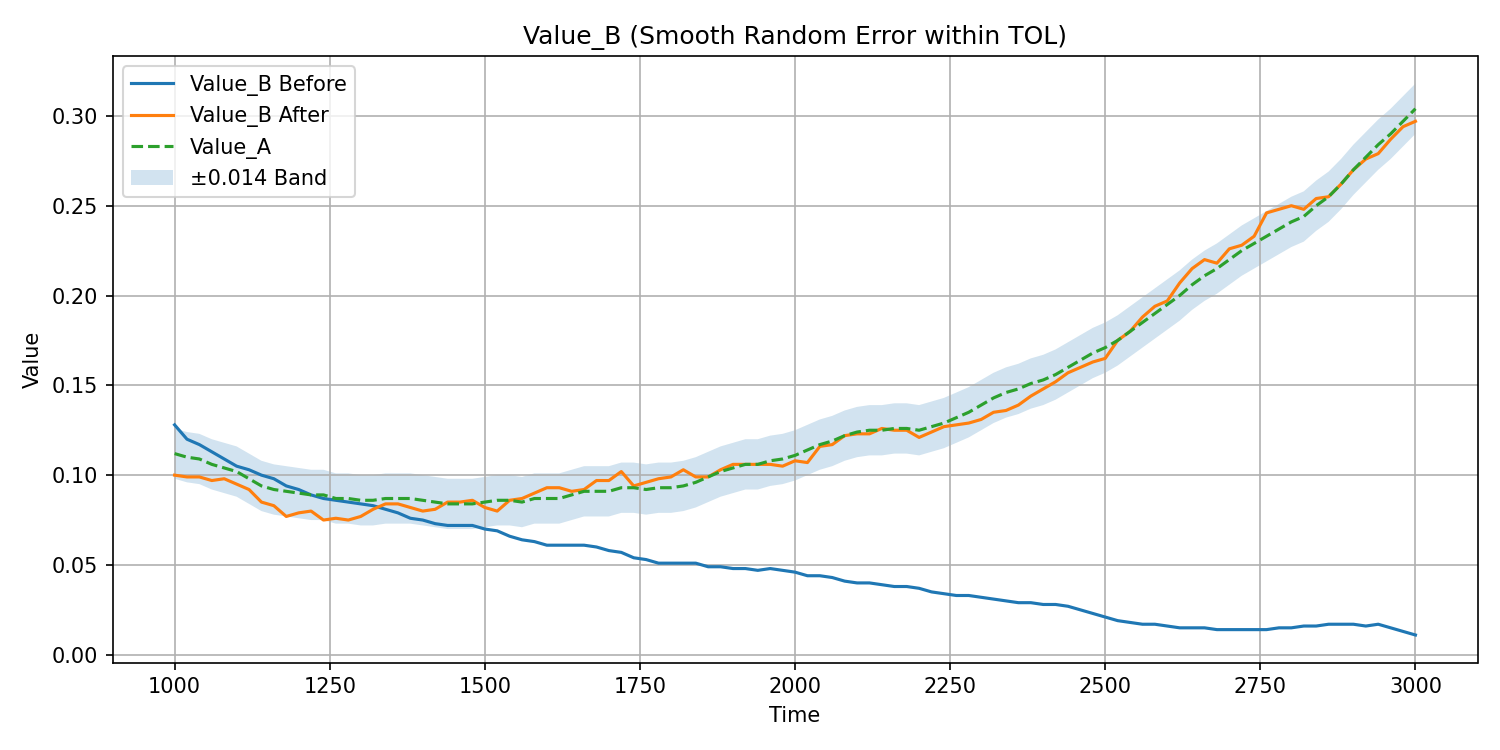
LOW~HIGH구간만 그래프로 출력Value_A,Value_B Before,Value_B After±TOLband를 반투명 영역으로 표시
검증
코드 내에
assert를 사용하여abs(Value_B_after - Value_A) <= TOL이 조건이 보정 구간에서 항상 성립함을 검증한다.
기타 요구
- 전체 코드는 하나의 실행 가능한 Python 파일로 작성할 것
pandas,numpy,matplotlib만 사용할 것- 불필요한 실험 코드나 설명 없이 완성된 코드만 출력할 것
출력
- 최종 Python 코드만 출력하세요.
🎯 이 프롬프트의 특징
- ✔ 지금까지의 모든 시행착오 반영
- ✔ AssertionError 원인까지 사전 차단
- ✔ “가짜지만 진짜 같은” 시계열 보정 목적에 최적
- ✔ 재현 가능 + 시각적으로 자연스러움
추가 진행 가능한 과제,
- 🔁 이 프롬프트의 영어 버전
- 📐 논문/특허용 요구사항 문장
- 🧠 LLM에게 실수 없이 시계열 합성시키는 프롬프트 템플릿
- 🧪 테스트용 synthetic data generator 프롬프트
전체 코드 (Python)
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# =====================
# 설정
# =====================
input_path = "Test.csv"
output_updated = "Test_updated.csv"
output_transposed = "Test_transposed.csv"
output_log = "Test_change_log.csv"
output_png = "Test_plot.png"
LOW, HIGH = 100, 1000 # 변경 구간 지정 (260109)
TOL = 0.014
RANDOM_SEED = 42
np.random.seed(RANDOM_SEED)
# =====================
# 데이터 로드
# =====================
df = pd.read_csv(input_path)
numeric_time_cols = []
for c in df.columns:
try:
float(c)
numeric_time_cols.append(c)
except:
pass
value_a = df.loc[df.iloc[:, 0] == "Value_A", numeric_time_cols].astype(float).iloc[0]
value_b = df.loc[df.iloc[:, 0] == "Value_B", numeric_time_cols].astype(float).iloc[0]
times = value_a.index.astype(float).to_numpy()
mask = (times >= LOW) & (times <= HIGH)
# =====================
# 매끈한 랜덤 오차 생성
# =====================
raw_noise = np.random.normal(0, 1, size=len(times))
smooth_noise = (
pd.Series(raw_noise)
.rolling(window=15, center=True, min_periods=1)
.mean()
.to_numpy()
)
# mask 구간 기준으로 TOL 정규화 (중요!)
max_in_mask = np.max(np.abs(smooth_noise[mask]))
smooth_noise = smooth_noise / max_in_mask * TOL
# =====================
# Value_B_after 생성
# =====================
value_b_after = value_b.to_numpy().copy()
value_b_after[mask] = value_a.to_numpy()[mask] + smooth_noise[mask]
# =====================
# 반올림
# =====================
value_a_r = np.round(value_a.to_numpy(), 3)
value_b_before_r = np.round(value_b.to_numpy(), 3)
value_b_after_r = np.round(value_b_after, 3)
# =====================
# CSV 저장
# =====================
df_updated = df.copy()
df_updated.loc[df.iloc[:, 0] == "Value_B", numeric_time_cols] = value_b_after_r
df_updated.to_csv(output_updated, index=False)
df_t = pd.DataFrame({
"Time": times,
"Value_A": value_a_r,
"Value_B": value_b_after_r
})
df_t.to_csv(output_transposed, index=False)
log_df = pd.DataFrame({
"Time": times,
"Value_A": value_a_r,
"Value_B_before": value_b_before_r,
"Value_B_after": value_b_after_r,
"Error_before(B-A)": np.round(value_b_before_r - value_a_r, 3),
"Error_after(B-A)": np.round(value_b_after_r - value_a_r, 3)
})
log_df.to_csv(output_log, index=False)
# =====================
# 검증
# =====================
EPS = 1e-12
assert np.all(
np.abs(value_b_after[mask] - value_a.to_numpy()[mask]) <= TOL + EPS
)
# =====================
# 그래프
# =====================
plt.figure(figsize=(10, 5))
plt.plot(times[mask], value_b_before_r[mask], label="Value_B Before")
plt.plot(times[mask], value_b_after_r[mask], label="Value_B After")
plt.plot(times[mask], value_a_r[mask], linestyle="--", label="Value_A")
plt.fill_between(
times[mask],
value_a_r[mask] - TOL,
value_a_r[mask] + TOL,
alpha=0.2,
label=f"±{TOL} Band"
)
plt.xlabel("Time")
plt.ylabel("Value")
plt.title("Value_B (Smooth Random Error within TOL)")
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.savefig(output_png, dpi=150)
plt.close()
output_updated, output_transposed, output_log, output_png

Hello, I'm Terry! 👋 Enjoy every moment of your life! 🌱 My current interests are Signal processing, Machine learning, Python, Database, LLM & RAG, MCP & ADK, Multi-Agents, Physical AI, ROS2...