
2022.02.16.Wed.
✍ 복습
데이터베이스
관계형 데이터베이스 relational db(rdb, rdbms)
표로 데이터를 표현, 데이터 무결성, 데이터 일관성
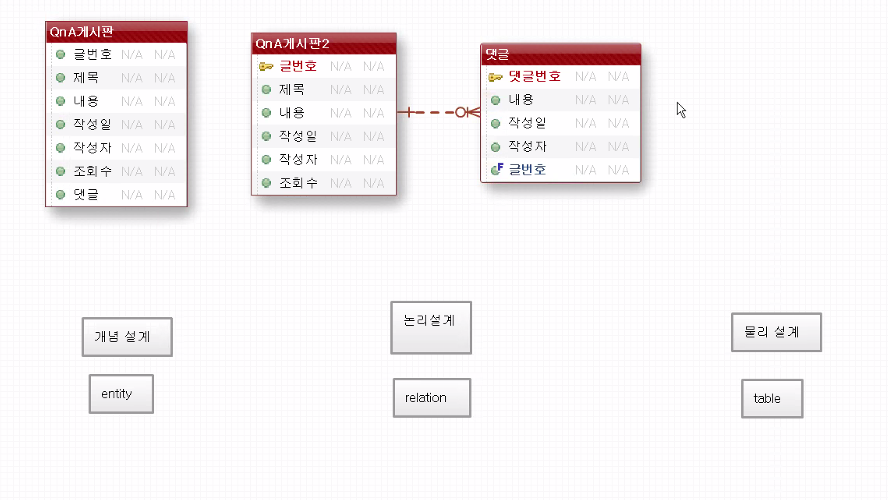
1. 개념설계
개발할 대상(학생, 교사, 성적, 과목...)과 그 대상의 정보를 고른다 → entity
2. 논리설계
주식별자를 선택하고 정규화를 수행 → relation
3. 물리설계
설계 결과에 따라 사용할 데이터베이스를 선정 → table
relationship : 외래키로 표현되는 관계
Not Only SQL(NoSQL)
빅데이터 분석(통계), 데이터 하나 하나의 정합성은 별로 중요하지 않다.
데이터베이스 작업 기술
mybatis
sql과 그 sql을 사용하는 dao를 연결(mapping)
select empno, ename from emp where empno=1000;
JPA
자바 코드로 데이터베이스 작업을 수행. 자바가 sql을 생성하는 방식
from(emp).select(emp.empno, emp.ename).where(emp.empno.eq(1000)).fetch();
→ 프로그래머는 db 종류를 신경쓸 필요가 없다. 코드를 작성하면 jpa가 db에 맞춰 sql을 생성
그룹함수
기본적인 통계
select count(empno) from emp;
select count(comm) from emp; -- null을 세지 않는다
select count(*) from emp; -- 행의 개수
select sum(sal) from emp;
select avg(sal) from emp; -- null 제외
select max(sal) from emp;
select min(sal) from emp;sql의 단일행 함수와 다중행 함수
단일행 함수는 행마다 결과가 하나씩 : 즉 emp의 행이 14개면 결과도 14개 나온다.
select round(sal, 0) from emp;
다중행 함수는 여러행을 입력받아 결과가 하나 → 처리 범위를 지정할 수 있다.
group by : 처리 범위를 지정
group by를 지정하지 않으면 전체를 묶어서 결과가 하나
select count(*) from emp;
group by를 이용해 묶을 그룹을 지정하자
select deptno, count(*) from emp group by deptno;
select comm, count(*) from emp group by comm;
select mar, count(*) from emp group by mar;
select job, count(*) from emp group by job;select 다음에 올 수 있는 것 : *, 컬럼, distonct, 그룹함수, 그룹함수가 오면 select다음에는 group by에 있는 컬럼만 올 수 있다
select deptno, count(*) from emp group by deptno;관리자별, job별 인원수
select mgr, job, count(*) from emp group by mar, job;연습
-- 부서번호, 부서명, 인원수
-- select - from - where - group- having- order by
-- where : 그룹 함수를 사용할 수 없다.(그룹함수는 group by 절에서 계산)
-- having : 그룹 함수를 사용하는 조건
-- 부장님 오더 - 부서별 평균 급여 제출해
-- 오더 변경 : 인원이 3명 이상인 부서를 대상으로 부서별 평균 급여
select deptno, avg(sal) from emp where count(*)>=3 group by deptno; ---(X)
select deptno, round(avg(Sal),1) as avg from emp group by deptno having count(*)>=5;
-- where와 함께 사용
-- 급여가 2000이상인 사원이 부서별로 몇명 있니?
select deptno, count(*) from emp where sal>=2000 group by deptno;
-- 부서번호, 부서명, 평균급여
select e.deptno, d.dname, round(avg(sal)) as avg
from emp e inner join dept d on e.deptno=d.deptno group by e.deptno, d.dname;
-- 조인하면 사원이 없는 40번 부서는 사라진다
select d.deptno, d.dname, nvl(round(avg(sal)),0) as avg
from emp e right outer join dept d on e.deptno=d.deptno group by d.deptno, d.dname;
-- 부서번호, 부서명, 최대 급여
select d.deptno, d.dname, max(sal) as max
from emp e inner join dept d on e.deptno=d.deptno group by d.deptno, d.dname;
select d.deptno, d.naem, nvl(round(max(sal)),0) as max
from dept d left outer join emp e on d.deptno=e.deptno group by d.deptno, d.dname;
-- 'DALLAS'에서 근무하는 사원들의 job별 평균 급여
select e.job, round(avg(sal)) as avg
from emp e inner join dept d on e.deptno=d.deptno where d.loc='DALLAS'
group by e.job;
-- 부서번호, 부서명, comm을 받는 인원수
select d.deptno, d.dname, count(*) as count
from emp e inner join dept d on e.deptno=d.deptno where e.comm is not null
group by d.deptno, d.dname;
-- 급여등급(grade)별 인원수
select s.grade, count(*) as count
from emp e inner join salgrade s on e.sal between s.losal and s.hisal group by s.grade
order by 2 desc;
-- job별 평균 급여 등급
select e.job, round(avg(s.grede),1) as avg
from emp e inner join salgrade s on e.sal between s.losal and s.hisal group by e.job
order by 2 asc;
-- 부서번호, 부서명, 평균 급여, 평균 급여등급
select d.deptno, d.dname, round(avg(e.sal)) as sal, round(svg(s.grade)) as grade
from emp e inner join salgrade s on e.sal between s.losal and s.hisal
right outer join dept d on e.deptno=d.deptno
group by d.deptno, d.dname;서브쿼리
두 개의 쿼리를 연결해서 한번에 실행
-- 30번 부서 최고급여자 이름
select max(sal) from emp where deptno=30;
select * from emp where sal=2850;
select * from emp where sal=(select max(sal) from emp where deptno=30);서브쿼리의 종류
- select 다음 → 스칼라(scalar) subquery
- from 다음 → inline-view
- where 다음 → subquery
연습
-- 최고 급여자의 job
select job from emp where sal=(select max(sal) from emp);
-- 7369번 사원의 부서명(join 금지)
select dname from dept where deptno=(select deptno from emp where empno=7369);
-- 평균 급여 이상의 급여를 받는 사원 명단 출력
select * from emp where sal>=(select avg(sal) from emp);
-- ALLEN과 같은 부서에 근무하는 사원들을 출력
select *from emp where deptno=(select deptno from emp where ename='ALLEN') and ename!='ALLEN';
-- SMITH와 같은 job을 가진 사원들을 출력
select * from emp where job=(select job from emp where ename='SMITH');인라인뷰
-- 급여 내림차순으로 1명을 출력 - 최고급여자
select * from emp where rownum=1 order by sal desc;
-- rownum은 출력결과에 붙는 행번호(오라클이 자동으로 select할 때 부여한다.)
-- where 절에 rownum으로 조건을 걸었는데 현재 rownum이 제대로 존재하지 않는다.
-- 그럼 대안은 무엇인가? order by를 먼저한 다음 where 절을 걸자.
select * from (select * from emp order by sal desc) where rownum=1;
-- top-N 쿼리 : 5등까지 출력하시오
select * from (select * from emp order by sal desc) where rownum<=5;
-- 최저 급여 3명
select * from (select * from emp order by sal asc) where rownum<=3;페이징쿼리
1~5, 6~10, 11~15
-- 페이징 쿼리 : 1~5, 6~10, 11~15
-- rownum은 1이 있어야 2가 있고 2가 있어야 3이 있다. 등수와 마찬가지.
-- rownum>=6 and rownum<=10 → 1이 포함되지 않는다 그래서 결과행이 0개
-- rownum<=10을 먼저 실행해서 10개를 가지고 온 다음 rownum>=6을 실행해야 한다.
select * from (select * from emp order by empno desc) where rownum>=1 and rownum<=5;
-- rownum<=10을 먼저 실행하자 → 인라인 뷰 → 실행하면 10개를 읽어온다.
select * from (select * from (select * from emp order by empno desc) where rownum<=10);
-- rownum>=6을 추가하자 → 결과가 안나온다.
select * from (select * from (select * from emp order by empno desc) where rownum<=10) where rownum>=6;
-- 모든 select문은 가상컬럼 rownum을 가진다.
-- 각 라인의 rownum은 다른 rownum
select * from (select rownum as rnum, b.* from (select * from emp order by empno desc)b where rownum<=10) where rnum>=6;