
상대적 순위
✏️오늘의 문제
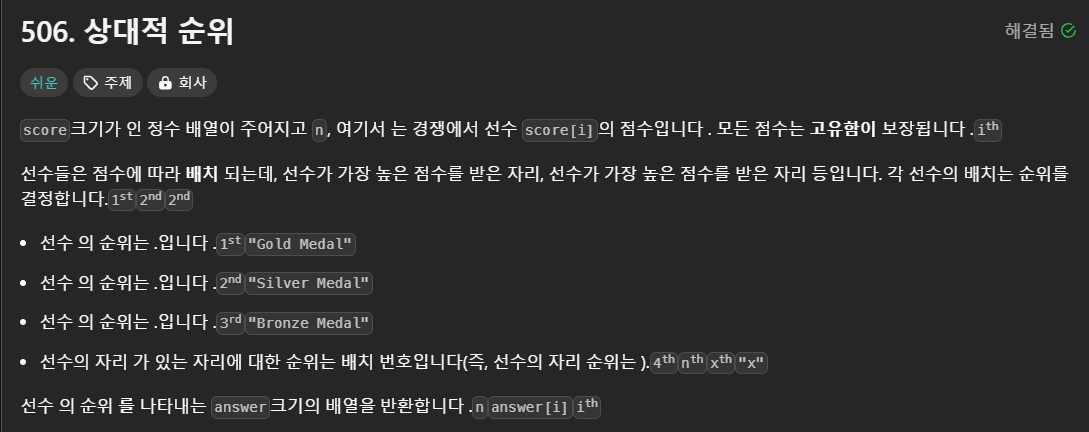
💡나의 풀이
public String[] findRelativeRanks(int[] score) {
int n = score.length;
int[] sortedScores = new int[n];
String[] rank = new String[n];
// 점수 배열 복사
for (int i = 0; i < n; i++) {
sortedScores[i] = score[i];
}
// 점수 배열 정렬
for (int i = 0; i < n; i++) {
for (int j = i + 1; j < n; j++) {
if (sortedScores[i] < sortedScores[j]) {
int temp = sortedScores[i];
sortedScores[i] = sortedScores[j];
sortedScores[j] = temp;
}
}
}
// 순위 매기기
for (int i = 0; i < n; i++) {
int position = 0;
for (int j = 0; j < n; j++) {
if (score[i] == sortedScores[j]) {
position = j; // 위치 찾기
break;
}
}
if (position == 0) {
rank[i] = "Gold Medal";
} else if (position == 1) {
rank[i] = "Silver Medal";
} else if (position == 2) {
rank[i] = "Bronze Medal";
} else {
rank[i] = String.valueOf(position + 1); // 1부터 시작하는 순위
}
}
return rank;
}코드 설명
-
배열 복사: 주어진
score배열을sortedScores배열에 복사합니다. 이는 원본 배열을 보존하기 위함입니다. -
정렬: 중첩된
for루프를 사용하여 점수를 내림차순으로 정렬합니다. 이 부분은 버블 정렬 알고리즘을 기반으로 하고 있습니다. -
순위 부여: 각 점수의 순위를 매기기 위해 또 다른 중첩된
for루프를 사용하여 원래 점수와 정렬된 점수를 비교합니다. 순위에 따라 "Gold Medal", "Silver Medal", "Bronze Medal"을 부여하고, 그 외의 순위는 정수로 표시합니다.
문제점
-
효율성: 이 코드는 정렬을 위해 O(n^2) 복잡도를 가진 버블 정렬을 사용합니다. 점수 배열의 크기가 커질수록 성능이 저하될 수 있습니다. 더 효율적인 정렬 알고리즘(예: 퀵 정렬, 병합 정렬 등)을 사용하는 것이 좋습니다.
-
중복 점수 처리: 같은 점수가 여러 번 등장할 경우, 정확한 순위를 보장하지 않습니다. 예를 들어, 동일한 점수가 여러 번 있을 때, 순위 부여가 중복될 수 있습니다. 이를 해결하기 위해 인덱스를 기준으로 순위를 매기는 방식으로 코드 수정이 필요합니다.
-
가독성: 중첩된 루프가 많아 코드의 가독성이 떨어집니다. 이를 개선하기 위해 각 단계별로 함수를 분리하거나, 더 직관적인 방법으로 코드를 구성할 수 있습니다.
결론
위 코드는 기본적인 상대 순위 계산을 수행하지만, 성능과 가독성 측면에서 개선의 여지가 많습니다. 향후 개선 방향으로는 효율적인 정렬 알고리즘 사용, 중복 점수 처리 로직 추가, 코드 구조 개선 등을 고려할 수 있습니다.
💡다른 사람의 풀이
import java.util.Arrays;
import java.util.HashMap;
class Solution {
public String[] findRelativeRanks(int[] score) {
int n = score.length;
String[] rank = new String[n];
int[] sortedScores = score.clone(); // 점수 배열 복사
// 점수 배열 정렬
Arrays.sort(sortedScores);
// 순위 매기기 위한 HashMap
HashMap<Integer, String> rankMap = new HashMap<>();
// 순위 설정 (내림차순)
for (int i = n - 1; i >= 0; i--) {
if (i == n - 1) {
rankMap.put(sortedScores[i], "Gold Medal");
} else if (i == n - 2) {
rankMap.put(sortedScores[i], "Silver Medal");
} else if (i == n - 3) {
rankMap.put(sortedScores[i], "Bronze Medal");
} else {
rankMap.put(sortedScores[i], String.valueOf(i + 1));
}
}
// 원래 점수에 대한 순위 반환
for (int i = 0; i < n; i++) {
rank[i] = rankMap.get(score[i]);
}
return rank;
}
}코드 설명
- 점수 배열 복사:
score.clone()을 사용하여 원본 점수를 복사합니다. - 정렬:
Arrays.sort()를 사용하여 점수를 오름차순으로 정렬합니다. - 순위 매기기: 내림차순으로 순위를 매기기 위해
HashMap을 사용하여 각 점수에 대한 순위를 저장합니다. - 순위 반환: 원래 점수 배열을 기반으로
rank배열에 순위를 할당합니다.
장점
- 효율성: 정렬에 O(n log n) 시간 복잡도를 가지며, 순위 매기기도 O(n)으로 처리됩니다.
- 중복 점수 처리:
HashMap을 사용하여 동일한 점수에 대해 올바른 순위를 부여합니다. - 가독성: 코드가 깔끔하고 이해하기 쉬워 유지보수에 용이합니다.
➕HashMap이란?
HashMap은 Java에서 제공하는 데이터 구조로, 키-값 쌍을 저장하는 해시 테이블 기반의 맵입니다. 다음은 HashMap의 주요 특징과 장점입니다.
주요 특징
-
키-값 쌍:
HashMap은 각 데이터 요소를 키와 값의 쌍으로 저장합니다. 키는 고유해야 하며, 동일한 키를 사용하여 값을 저장하면 기존 값이 새로운 값으로 덮어씌워집니다. -
빠른 검색: 해시 테이블을 사용하여 요소를 저장하므로, 평균적으로 O(1) 시간 복잡도로 데이터를 검색할 수 있습니다. 하지만 최악의 경우 O(n) 시간이 걸릴 수도 있습니다.
-
순서 없음:
HashMap은 요소의 순서를 보장하지 않습니다. 따라서 저장한 순서와는 관계없이 데이터가 저장됩니다. -
null 값 허용:
HashMap은 하나의 null 키와 여러 개의 null 값을 허용합니다. -
동기화되지 않음:
HashMap은 기본적으로 스레드 안전하지 않습니다. 여러 스레드에서 동시에 접근할 경우 문제를 일으킬 수 있으므로, 스레드 안전이 필요한 경우ConcurrentHashMap을 사용하는 것이 좋습니다.
사용 예시
import java.util.HashMap;
public class Example {
public static void main(String[] args) {
HashMap<String, Integer> map = new HashMap<>();
// 요소 추가
map.put("Apple", 1);
map.put("Banana", 2);
map.put("Cherry", 3);
// 요소 검색
System.out.println("Apple의 값: " + map.get("Apple")); // 출력: Apple의 값: 1
// 요소 삭제
map.remove("Banana");
// 모든 요소 출력
for (String key : map.keySet()) {
System.out.println(key + ": " + map.get(key));
}
}
}장점
- 효율적인 데이터 관리: 대량의 데이터를 빠르게 검색하고 관리할 수 있습니다.
- 유연한 키 사용: 다양한 데이터 타입을 키로 사용할 수 있어 유연성이 높습니다.
