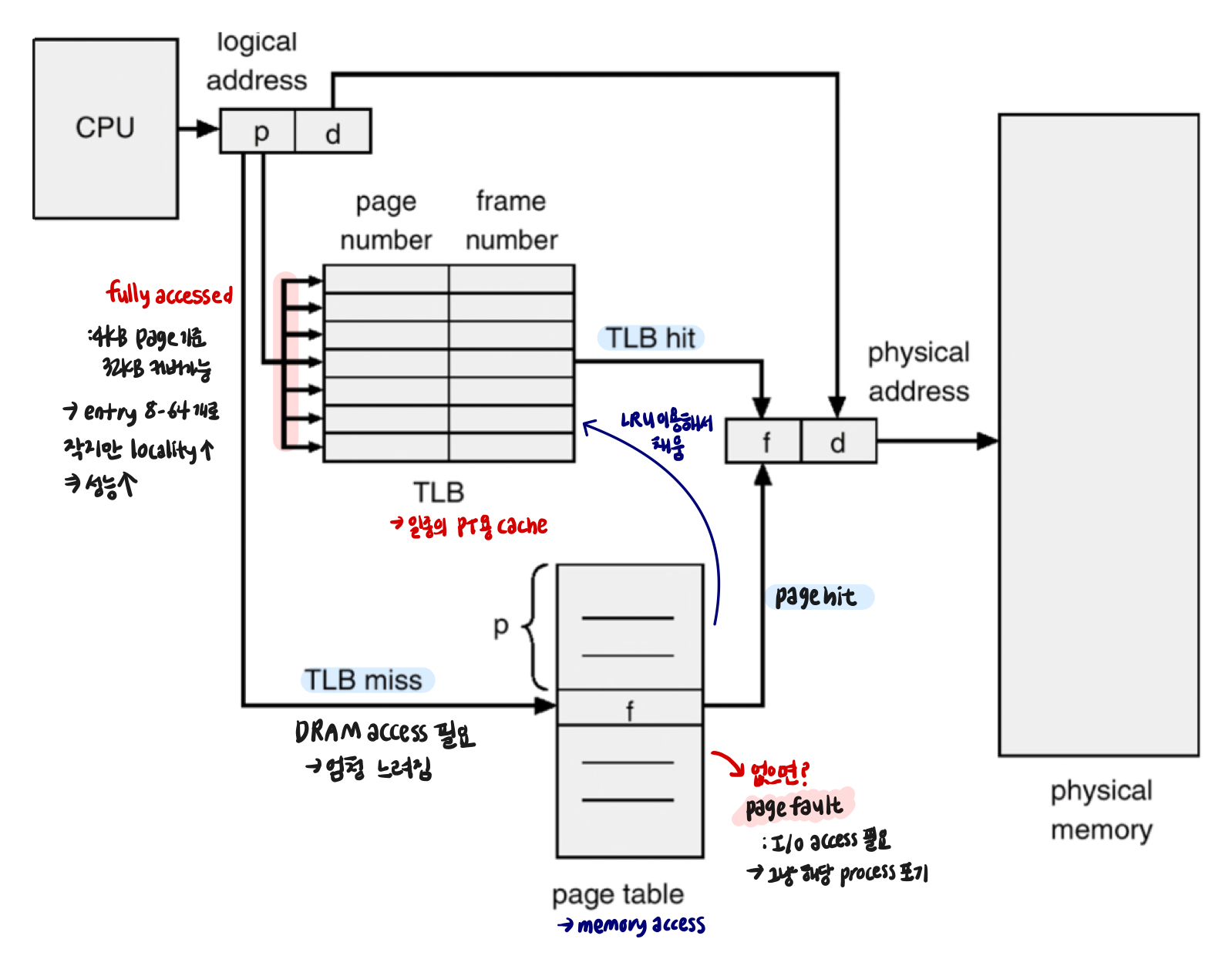
TLB
➀ TLB란?
: Translation Lookaside Buffers
→ VPN당 PFN 정보 저장
→ virtual page #를 PTE로 (physical 주소 필요 x)
-
HW에 구현됨
-
fully associated cache
: 모든 entry가 병렬로 search- cache tag : virtual page number
- cache value : PTE
- PTE + offset으로 PA 계산
-
-
Locality
-
16-64 entries in TLB
-
hit rate 증가
→ entry 몇개 없어도 locality 증가로 성공적
-
종류
spacial locality : 참조한 부분을 참조
temperal locality : 한번 참조한 부분을 계속 참조
-
e.g.
: 하나하나 비교 (SW) ↔ fully associated cache (HW) : 한 cycle에 한번에
➁ MMU with TLB
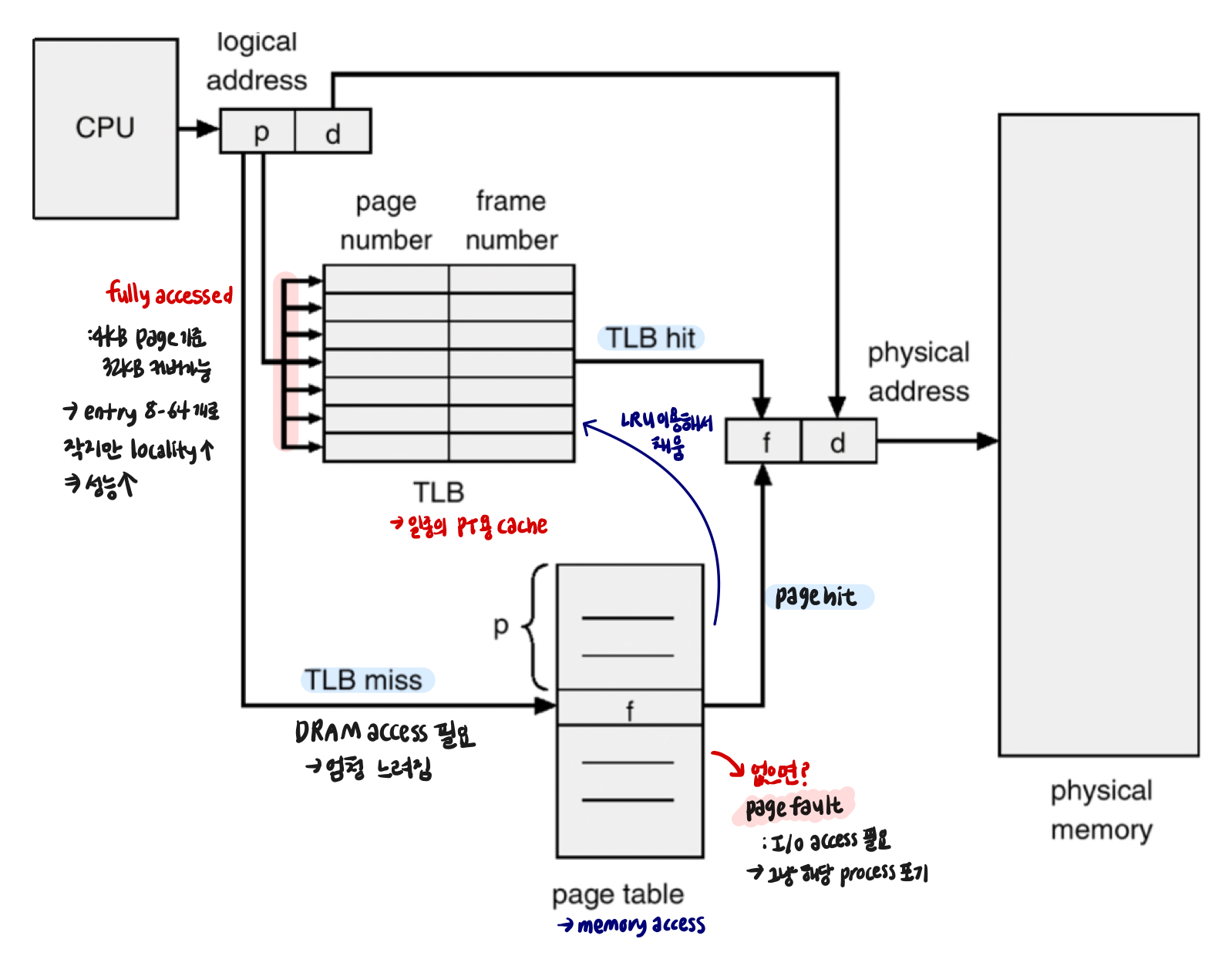
TLB miss, hit는 pipeline에서 execute 상태에 멈춰있음
→ page fault는 process 포기
* PT, TLB의 값은 consistent 항상 유지*
TLB miss vs page fault
: execute이 V→P의 과정
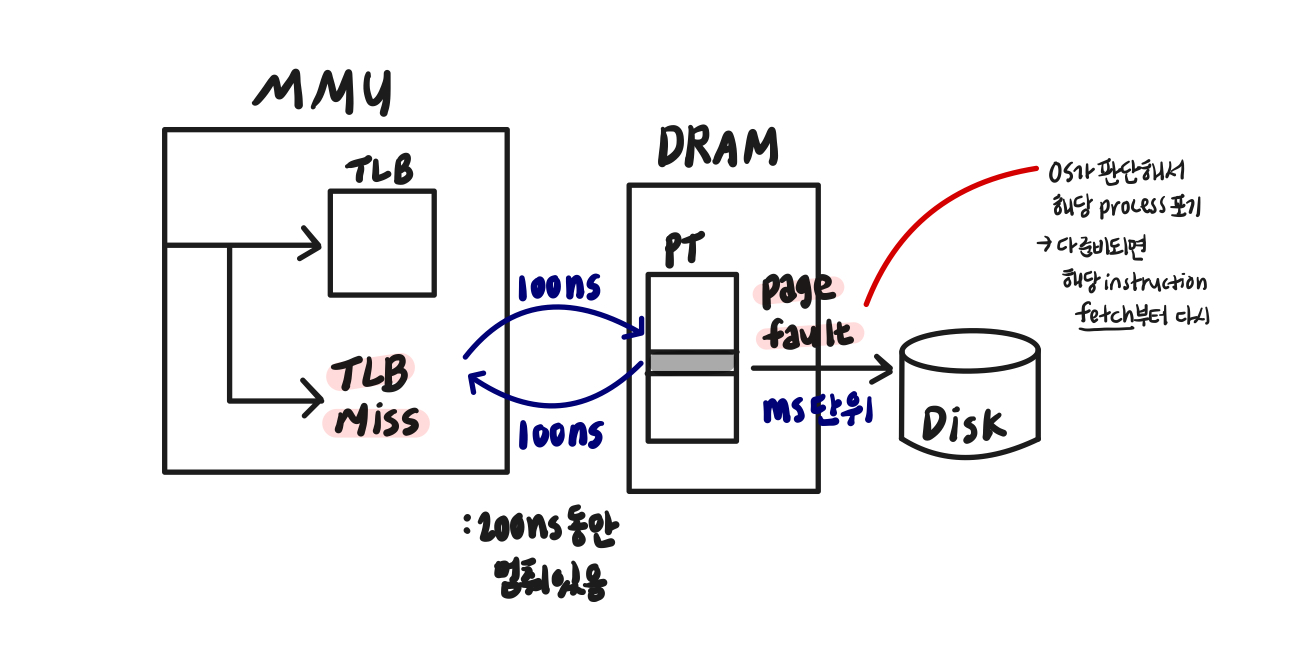
➂ Managing TLBs
- 주소변환의 99%는 TLB에서
1. TLB의 종류
-
HW (memory management unit)
: memory의 어디에 PT가 있는지 알고있음
→ OS가 관리, HW가 바로 접근
→ Intel에서는 hw가 정해진 format에 맞춰서→ 요즘의 추세
∵ chip당 사용가능한 transister 수 증가 -
Software loaded TLB (OS)
: TLB miss를 OS가, OS가 맞는 PTE찾아서 TLB에 load
→ much simpler MMU
→ 어느 format이어도 상관 x
e.g. RISC : 가능한 모든 것을 sw에, hw 간단하게 만들어 속도 높이기
→ 과거에 사용
∵ MMU 늘리느니 코드 늘림
2. OS가 TLB의 consistent 보장해야함
경우 1 해당 page에 store
: 정보 update
→ modified bit=1
→ PT와 TLB의 내용이 달라짐
→ replace될때나 process switch로 flush 직전에 갱신
: MMU내 HW가 담당
경우 2 PT의 정보 update (보통은 protection)
→ TLB의 해당 정보를 invalid로
: OS가 담당
3. process context swich시
: PT는 process마다
→ process switch시 전부 flush
→ 초반에 TLB miss가 많은 이유
→ process switch의 overhead는 작지 않음
4. TLB miss 발생시, 새 PTE loading시
: cached PTE 교체해야
→ TLB replacement policy에 따라 entry 선택
: 보통 LRU 사용
→ 전부 HW가 manage하기 때문에 format 전부 알고 있어야함
Multilevel Page Table
➀ paging의 문제점
: Page table의 크기가 너무 큼
e.g. 64bits의 경우 (page크기: 4KB)
→ entry의 개수 = 2^52, entry당 4KB
→ 2^52 4 = 2^54 = 2^22 4KB = 4 2^10 4GB
→가 프로세스마다 필요, DRAM에 저장해야함
→ 지원 불가능
→ 해결방법
1. Multilevel PT
2. Inverted PT
➁ Multilevel Page Table
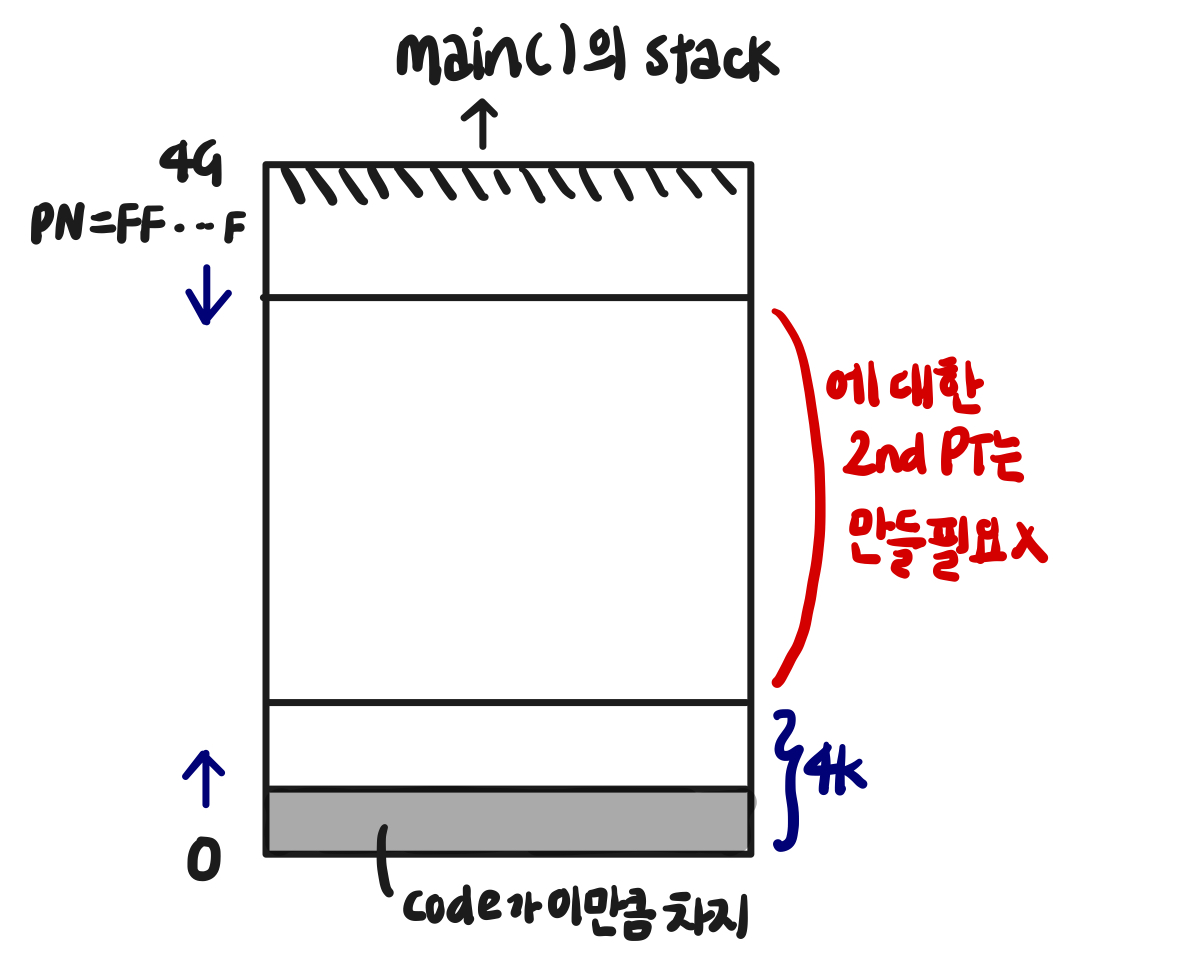
-
one-level
: 2^20의 PT 할당
-
two-level
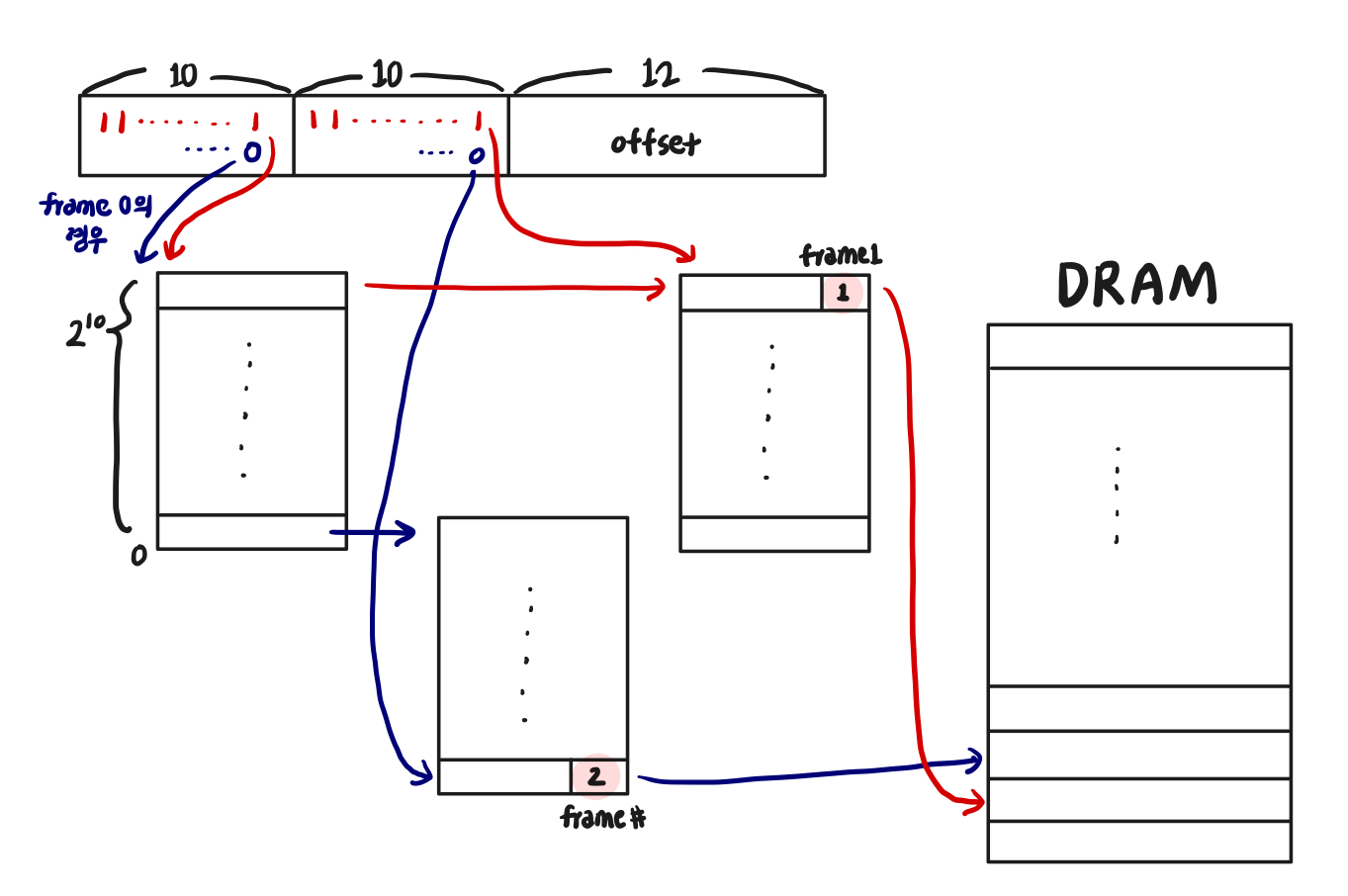
→ 3*2^10만 사용
→ 3번의 access 필요
→ 사용하는 영역에 대한 PT만 만들면 됨 ( ∵ 대부분의 VA 공간은 비어있음)
** 64bits의 경우? level이 더 커져야함 → level이 증가할수록 memory access 횟수 증가
→ TLB의 중요성
Two-level page table
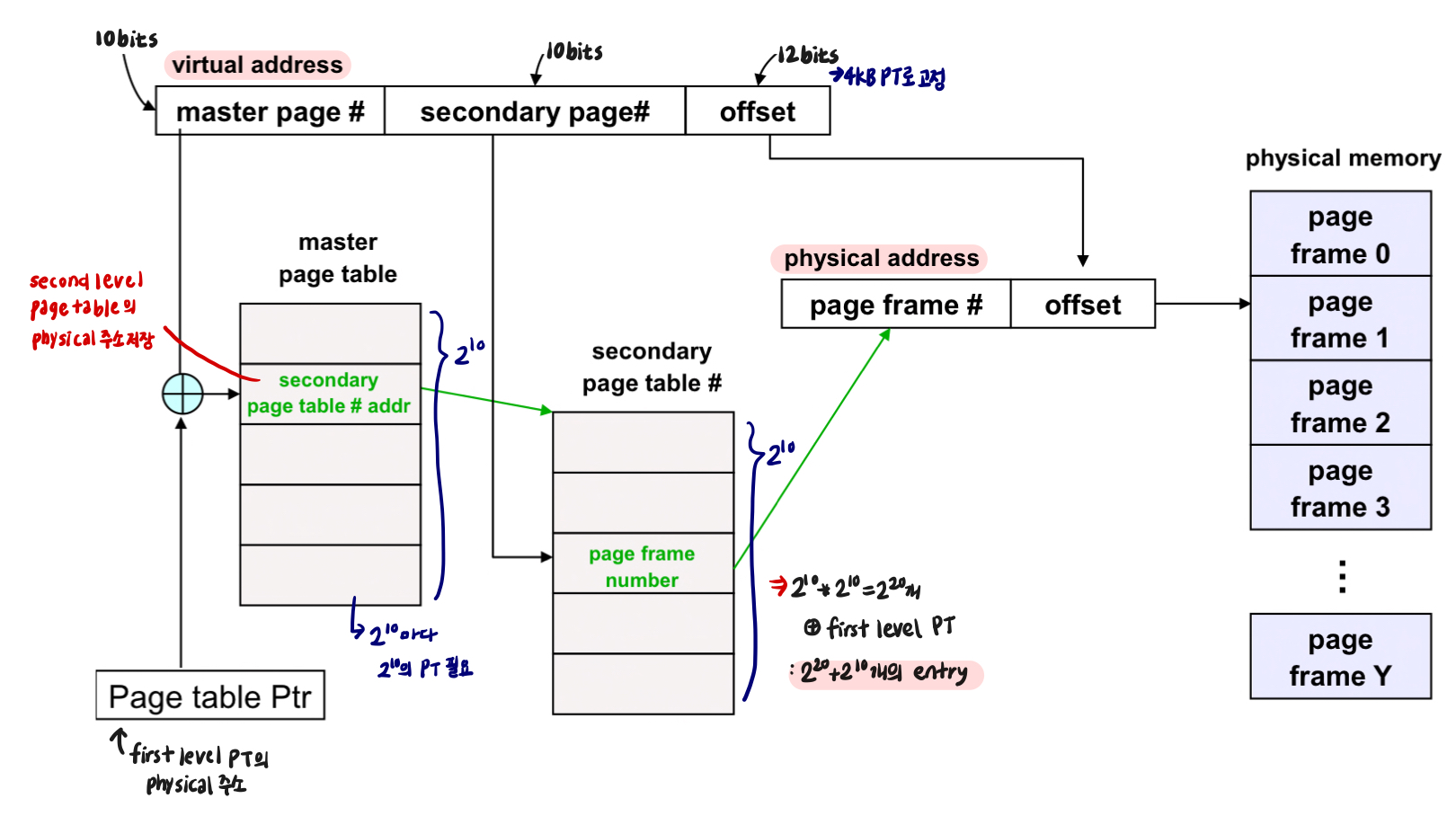
e.g. 4KB pages, 4Bytes
: 12bits 필요 (offset)
- first level bit
: PT in one page로 4KB/4B = 1024 PTE
∴ first level bit = 10bits, offset = 12bits
Inverted page table
-
PT의 크기가 너무 클때의 solution
-
one entry per page frame in real memory
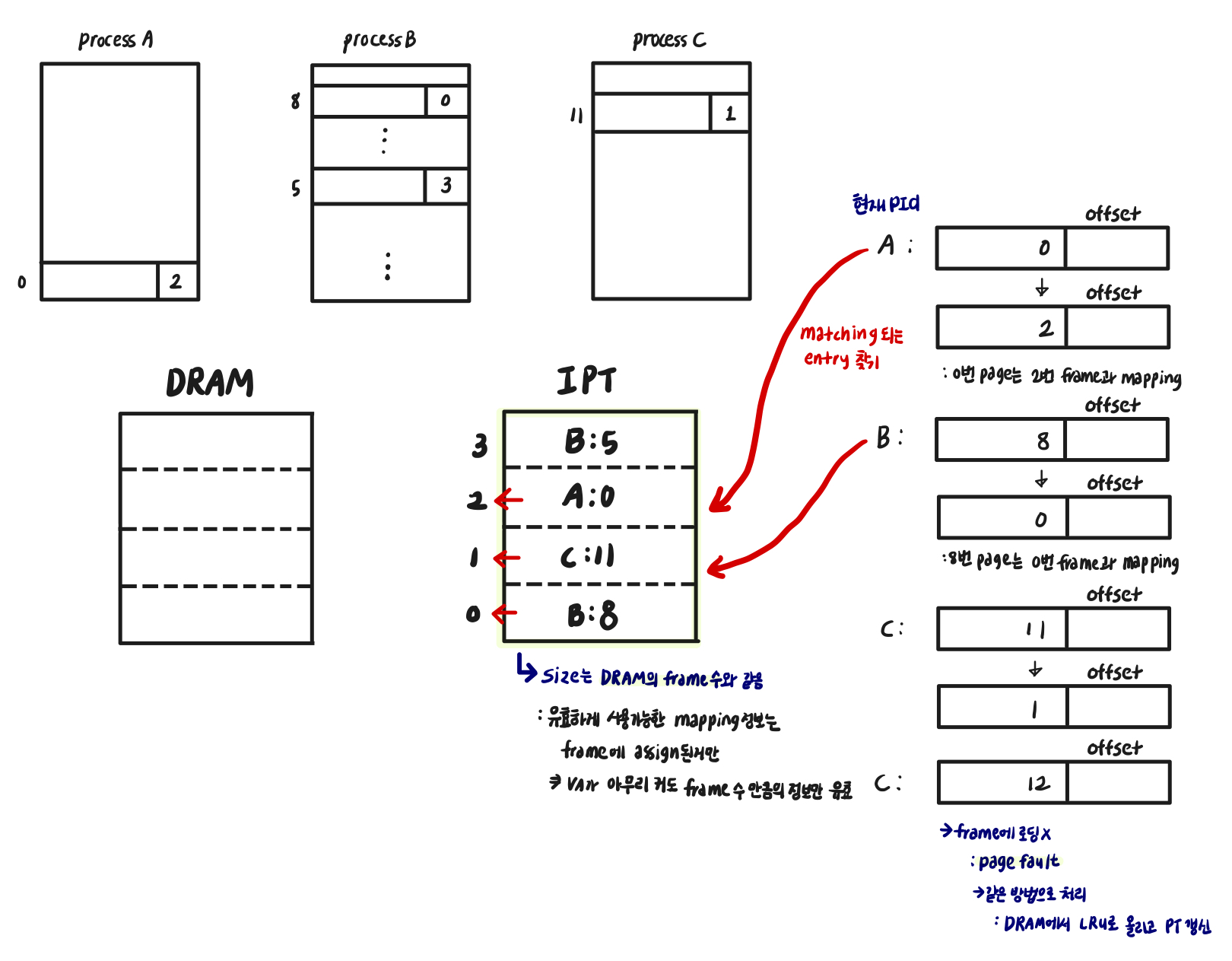
-
IPT의 size는 DRAM의 frame 개수와 같음
: process가 아무리 많고 VA가 아무리 커도 frame의 수 만큼의 정보만 유효함
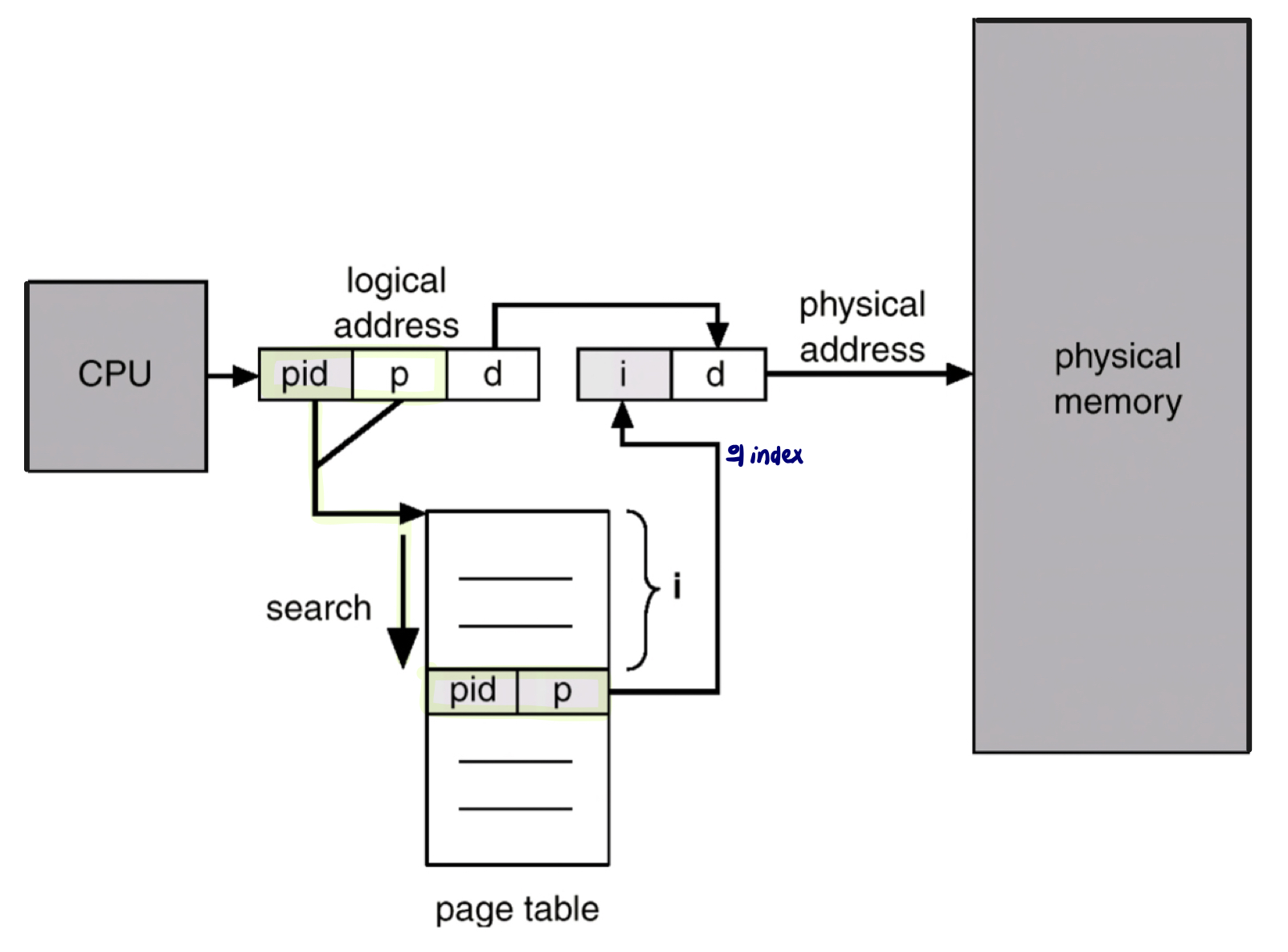
→ index로 접근
: mapping의 정보를 하나하나 찾아가야함
→ 찾고자하는 정보가 있는 곳까지 i번의 memory access
Hash Table
- array access : index access인 Inverted Page Table의 한계 극복
- hash함수 이용해 큰 도메인 → 작은 도메인으로 mapping
- entry size는 IPT와 마찬가지로 DRAM의 frame size와 같음
- collision?
: 여러 값들이 같은 값으로 mapping
→ collision 많으면 memory access 수가 늘어남
→ 일반적으로 frame의 size만큼의 PTE이므로 collision이 매우 적음
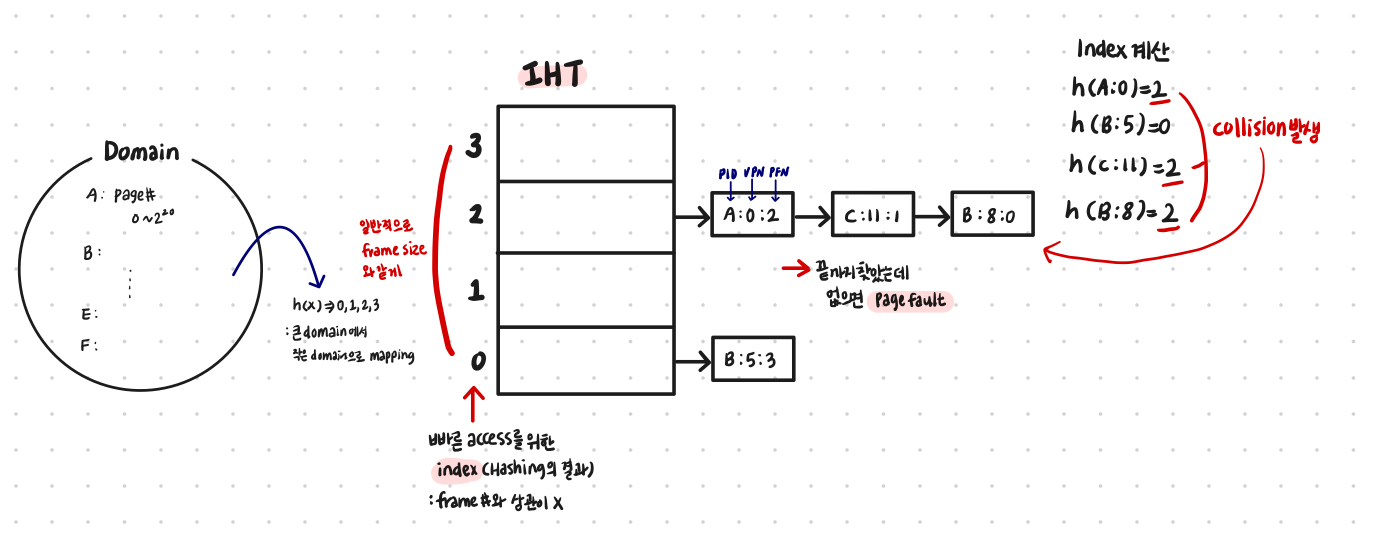
e.g. IHT 참고 과정
-
process A의 0번 페이지 → h(A:0) = 2
→ IHT[2]에서 search
→ A:0은 frame 2에 있음을 알 수 있음
→ array access로 변환됨 -
process C의 11번 페이지 → h(C:11) = 2
→ IHT[2]에서 search -
process E의 11번 페이지 → h(E:11) = 1
→ IHT[1]에서 search
→ 끝까지 찾아도 없으면 page fault
→ 페이지 교체 알고리즘 이용해서 새로 할당
