Thread와 Process
process
: 실행중인 프로그램
-> 운영체제로부터 시스템 자원을 할당받는 작업의 단위
-> 독립적인 address space를 갖고, 독립적인 resource를 가진다
thread
: 경량화된 프로세스로 process가 갖는 resource 전부 공유
-> 생성, 사용에 대한 오버헤드가 적음
-> 병렬성 향상
-> context switch시 빠름 ∵ 캐쉬 메모리 비울 필요 x
- thread는 single process에 <-> process는 여러개의 thread 가질 수 있음
- thread가 스케줄링/컨텍스트 스위치의 단위가 됨
: process는 각 thread가 동작하는 컨테이너의 역할만
Process
Process의 정의
- 실행 중인 프로그램
-> 운영체제로부터 시스템 자원(CPU)을 할당받는 작업의 단위
특징
- OS의 실행을 위한 추상화
-> 실행, 스케줄링의 단위 - job, task, sequential process라고도 불림
- 독립된 메모리 영역을 가짐
: virtual address space, code, data, SP, PC 등 - OS에서의 process는 유니크하게 구분 가능한 ID를 가짐 -> PID
- 각 프로세스는 별도의 주소공간에서 실행 -> 다른 프로세스의 변수, 자료구조 접근 x
- 다른 프로세스의 자원 접근시 프로세스 간 통신(IPC) 이용
생성
- 한 process가 다른 process를 생성
: unique한 ID를 갖게 되고, 권한은 보통 물려받음 fork()
: 새 PCB 만들고 초기화 -> 새 address space 생성 -> parent process의 address space 전체 복사해서 address space 초기화-> kernel resources는 parent의 resource로 초기화exec()
: 새 process가 자신의 메모리 이미지 변경하고 새 프로그램 수행
종료
- 종료의 조건
- normal exit
- error exit
- fatal exit : os의 판단 아래
- killing by another process : process가 가진 resource 전부 반환
상태
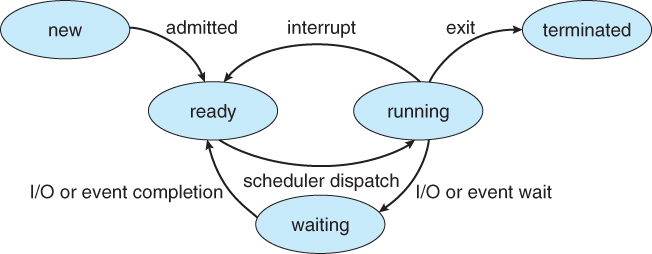
- ready : 실행가능하지만 다른 process가 CPU 사용중 -> CPU할당 시 아무 문제없이 사용 가능
- running: executing on the CPU
- blocked : 외부 이벤트가 발생할 때 까지 실행x
Thread
Thread의 사용
-
sequential process에서 순차적으로 처리하므로 CPU 4개나 1개나 성능이 같음
-> parallel programming 도입
-> 문제점? CPU를 활용 가능한 algorithm은?? -
process가 1개일때 각 function이 다른 CPU에서 돌기 위한 조건은?
-> CPU의 상태가 여러개가 됨으로 각자의 CPU상태를 저장해야함
-> 각 CPU가 메모리를 사용하므로 stack이 겹치지 않게 분리해야함
-> 연산의 결과 전달은 ??
(i) file : I/O라 너무 느림
(ii) shared memory : system call 이용하므로 오버헤드가 큼
(iii) socket : 오버헤드가 큼
-> process는 한개지만 각 function을 다른 CPU에서 실행할 수 있게 Thread 사용
Thread란
- address space를 공유 -> 모든 code, data, privileges, resource를 공유
- 각각의 thread는 각자의 hw execution stack을 가짐
-> PC, registers, stack pointer, stack - execution state, light weight process라고 불림
Thread 이용의 장점
- 한번에 여러 동작 가능
-> Thread의 programming model이 더 단순함 - thread가 process보다 가벼움: 생성, 제어에 용이
- 성능 개선 : overlapping I/O, CPU activities, blocking system calls

Hongik CE