마지막 날 결국 밤 새웠지만... Advanced Scheduler를 pass 하지 못 했다
alarm 테스트 케이스들까지 전부 뻑나길래ㅋ...
결국 다 밀어버리고 우리팀 git 레포지토리에서 main 브랜치 pull 받아왔다.
다른 팀원이 성공해서 팀 결과는 all passed였지만, 개인적으로는 pass 하지 못 해서 너무 아쉽다🥹
그래도 시도하고, 과정에서 공부했던 것들이 있으니까 기록은 해봐야겠다
📍Project(1)의 마지막 과제, Adavanced Scheduler 구현
Main Goal: Multi Level Feedback Queue 스케줄러 구현
priority scheduler는 priority에만 의존하기 때문에 우선순위가 낮은 thread들은 cpu를 점유하기 어렵고, 이로 인해 평균 반응 시간이 커질 위험이 있다.
우선순위 donation을 도입한다 해도 여전히 cpu를 점유하지 못 하는 thread가 생길 수 있다.
그래서 advanced scheduler는 위 문제를 해결하고, 평균 반응 시간을 줄이고자 MLFQ 스케줄링 방식을 도입한다.
- Priority에 따라 하나 이상의 Ready_Queue가 존재(= Multi Level)
-> 우선순위가 높은 편인 thread들을 담을 queue와, 우선순위가 낮은 편인 thread들을 queue 이런 식으로 생성하는 느낌- Prioirty 값 실시간으로 조절(= Feedback)
[Priority 값을 실시간으로 조절해 계산하기 위해 생각해야 할 것들]
1) Nice Value
: thread의 친절함을 나타내는 값, 말 그대로 친절할수록 우선순위가 낮아져 양도를 할 확률이 높아진다.
Nice(0): 우선순위에 영향x
Nice(양수): 우선순위 감소
Nice(음수): 우선순위 증가
default value = 0
-> modify: thread_get_nice(), thread_get_nice()2) recent_cpu
: 메모리 사용량, running thread일 경우 1tick마다 +1씩 증가
3) load_avg
: cpu 부하량, running thread와 ready_list에 있는 thread들의 수에 영향을 받음
=> 그만큼 실행하고/실행을 위해 준비된, 실행될 애들이니까
[계산 식]
1) Priority update
priority = PRI_MAX - (recent_cpu/4) - (nice * 2)
thread가 nice한 경우, 우선순위 감소
thread에서 최근 cpu를 많이 사용하고 있는 경우, 우선순위 감소
모든 스레드의 우선순위는 4 clock tick마다 재계산 한다. (1 clock tick = 10msec)
-> 결과는 가장 가까운 정수로 잘린다 (Kernel이 정수만 받아들이기 때문에)
2) recent_cpu update
recent_cpu = decay recent_cpu + nice
decay = (2 load_avg) / (2 load_avg + 1)
-> recent_cpu = {(2 load_avg) / (2 load_avg + 1)} recent_cpu + nice
매 timer_interrupt(1tick마다 호출)때마다 현재 실행 중인 thread의 recent_cpu 1씩 증가
또한, 매초마다 recent_cpu를 decay factor로 감쇠시킨다.
또한, 매초마다 revent_cpu를 nice 단위로 조정한다.
[decay factor]
cpu 부하가 무거우면 decay값이 1에 수렴
cpu 부하가 가벼우면 decay값이 0에 수렴
-> decay를 recent_cpu에 곱함으로써, decay가 0에 수렴할수록 부하가 작다.3) load_average update
load_average = (59 / 60) load_avg + (1 / 60) ready_threads
부팅 시, 첫 load_avg는 0으로 설정
*ready_threads? ready_list에 있는 threads 수와 실행 중인 thread 수 (idle_thread 제외)[최종 요약]
1) 4tick마다 모든 thread의 priority 재계산
2) 모든 clock tick마다 running thread의 recent_cpu를 1씩 증가 (= 모든 timer_interrupt에서 발생)
3) 매초(1초 = 100tick)마다 모든 thread의 load_avg & recent_cpu 재계산
priority = PRI_MAX - (recent_cpu / 4) - (nice * 2)
recent_cpu = decay * recent_cpu + nice
decay = (2 * load_avg) / (2 * load_avg + 1)
load_avg = (59 / 60) * load_avg + (1 / 60) * ready_threads📍 고정 소수점 연산 구현
pintos 기반으로 커널 내부에서는 정수 연산만 할 수 있다. (context switching 할 때 부동 소수점 레지스터를 저장하지 않는다.)
그래서 우리는 정수 연산을 이용해 고정 소수점 연산을 구현해야 한다.
priority & nice & ready_threads = 정수
recent_cpu & load_avg = 실수
우리는 17.14 고정 소수점 숫자 표현을 사용해 고정 소수점 산술을 구현한다.
17.14 고정 소수점 숫자 표현?
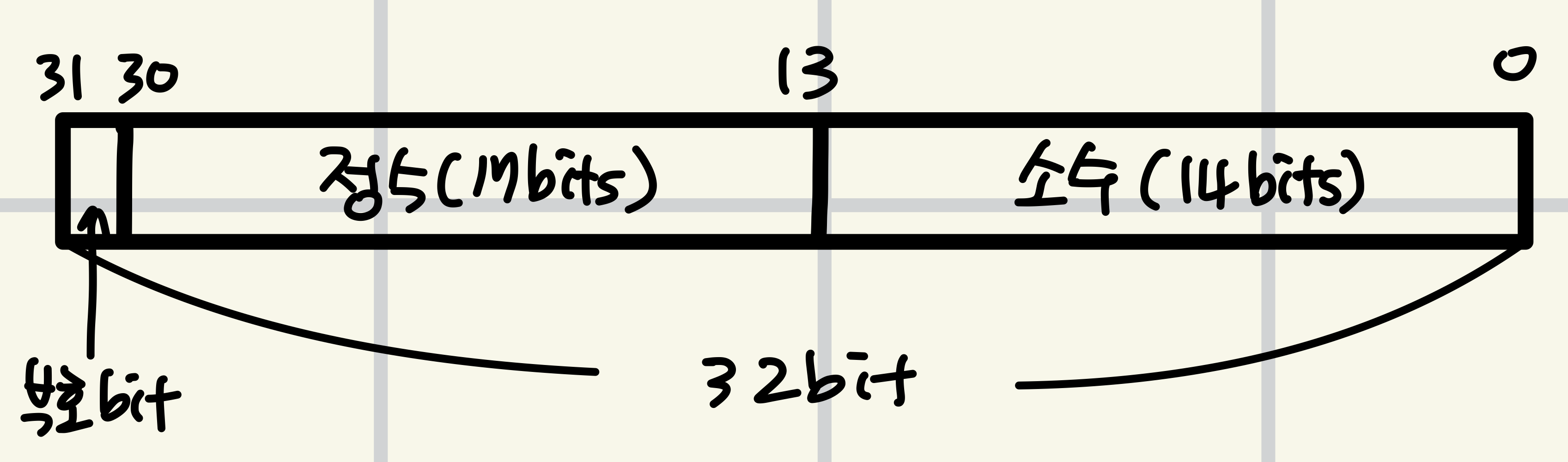
[정의 할 연산 식]

📍 최종적으로 추가 & 수정 할 부분들
[추가]
1) thread 구조체에 nice, recent_cpu 멤버 변수 추가
2) 추가할 함수 목록
- recent_cpu와 nice를 이용해 priority를 계산하는 함수
- recent_cpu 계산 함수
- load_avg 계산 함수
- recent_cpu를 1 증가시키는 함수 (1tick 마다 호출)
- 모든 thread의 priority 재계산 하는 함수 (4tick, 1초 마다 호출)
- 모든 thread의 recent_cpu(load_avg 또한) 재계산 하는 함수 (1초마다 호출)
[수정]
- init_thread(): thread의 nice & recent_cpu 초기화
- thread_set_priority(): advanced scheduler를 사용할 때 우선순위 설정 disable
<이미 선언되어 있는 전역변수 중 mlfqs_thread의 bool 값으로 판단>- timer_interrupt(): 모든 thread의 priority, load_avg, recent_cpu 값을 1초(100tick)마다 재계산 & 모든 thread의 priority 4tick마다 재계산
- lock_acquire() & lock_release(): advanced scheduler를 사용할 때 우선순위 donation disable
- thread_set_nice() & thread_get_nice(): 현재 thread의 nice값 설정/반환
- thread_get_load_avg(): load_avg * 100 반환
- thread_get_recent_cpu(): recent_cpu * 100 반환
+) 생각해볼 문제🤔
: 모든 thread를 어떻게 관리할 건지?
ready_list 목록과 running_thread, sleep_list 목록만 보면 되는지? X
all_list와 all_elem을 생성해 init_thread 할 때 삽입 / exit 내부 do_schedule()에서 삭제
fail 코드
-> 나중에 pull 받아서 다시 재시도 해보자🥺
