
Scraping & Crowling
Scraping: 특정 웹 사이트의 HTML을 긁어온다.
Crowling: 스크래핑을 정기적, 주기적으로 여러번 한다.
Scraping 이란?
Scraping은 특정 웹 사이트나 페이지에서 필요한 데이터를 추출해 내는 것을 말합니다.
특정 웹 사이트에 GET 요청을 보내고 사이트가 이에 응답하면 HTML문서를 분석하여 특정 패턴을 지닌 데이터를 뽑아냅니다.
그 이후에 추출된 데이터를 원하는 대로 사용할 수 있도록 데이터베이스에 저장합니다.
Scraping의 장점
Scraping은 특정 사이트나 페이지에 대한 정보를 찾는데 탁월하며, 원하는 데이터를 정확히 잡고 확실한 정보만을 수집할 수 있다는 점에서 유용합니다.
또한, 장기적으로 서비스의 대역폭이나 비용을 절감할 수 있는 장점도 있습니다.
Crowling 이란?
Crowling은 규칙에 따라 자동으로 웹 사이트를 탐색하는 기능입니다. 여러 웹 사이트에 접속하여 페이지의 내용들과 링크의 복사본을 생성합니다.
Crowling의 장점
Crowling은 방대한 양의 정보를 수집하기 때문에, 특정 키워드에 대한 분석이 필요할 때 유용합니다. 또한, Crowling은 실시간 정보를 수집하기 위해 계속해서 작동하므로, 데이터의 변화를 파악하기가 좋습니다.
Scraping & Crowling 차이점
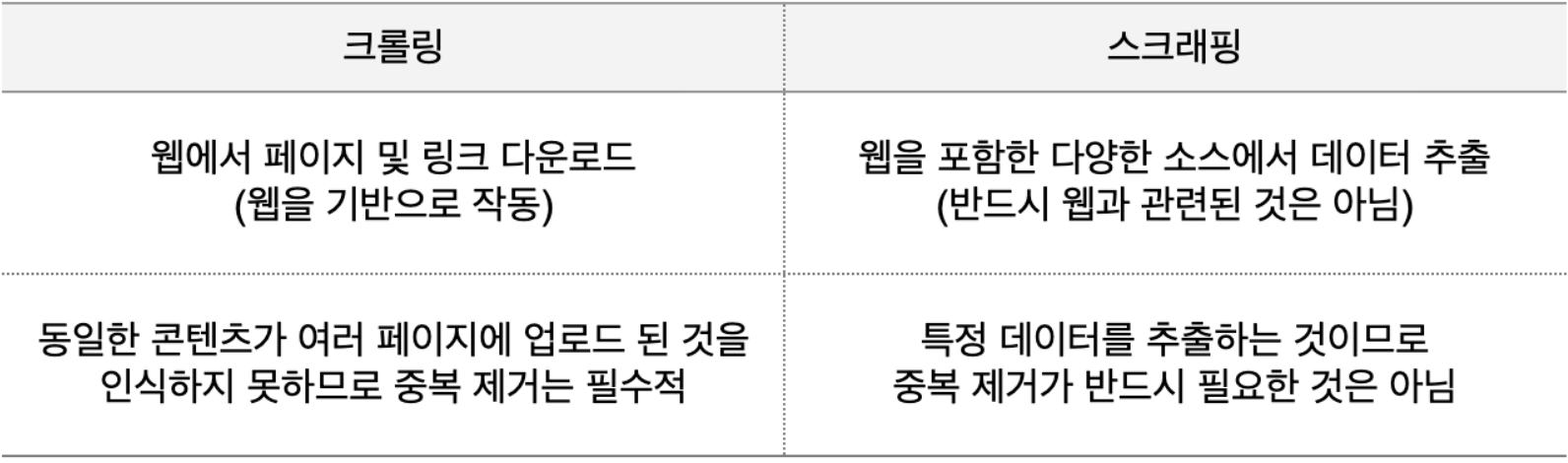
출처 : codef blog

백엔드 성장 기록