컴퓨터는 0과 1만을 이해한다
- 모든
양수를 0과 1로 표현하는 방법 ->2진수 - 모든
음수를 0과 1로 표현하는 방법 ->2의 보수 - 모든
소수를 0과 1로 표현하는 방법 ->부동 소수점 - 모든
문자를 0과 1로 표현하는 방법 ->문자집합 & 인코딩
2진수와 2의 보수법
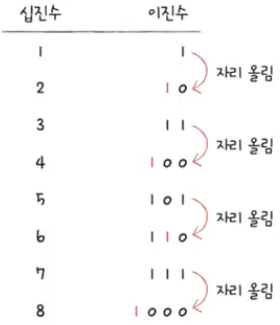
2진법(2진수)
- 2진법: 0과 1로 모든 수를 표기하는 방법
- 2진수: 0과 1만으로 표현된 수(2진법으로 표현된 수)
- 어떻게 0과 1로 모든 수를 표현할 수 있는가? ->
1을 넘어가는 시점에 자리 올림
2진법(2진수)의 단점
- 숫자가 너무 길어진다

1000을 2진수로 변환하려면 10개의 숫자가 필요하다. 많은 숫자가 소비된다는 단점이 있어서 2진수를 사용할 때에는 16진수로 표현하는 경우가 많다.
16진법(16진수)
- 16진법: 1~9와 A~F로 모든 수를 표기하는 방법
- 16진수: 1~9와 A~F로 표현된 수
| A | B | C | D | E | F |
|---|---|---|---|---|---|
| 10 | 11 | 12 | 13 | 14 | 15 |
- 15(F)를 넘어가는 시점에 자리 올림

Q) 그럼 왜 10진법이 아닌 16진법을 쓰는가?
A) 2진수와 16진수간의 변환이 간편하기 때문.
- 16진수는 2의 4제곱으로 나타낼 수 있음. 그래서 2진수와의 상호 변환이 간편하다.
따라서 컴퓨터 내부의 정보를 표현하는데 있어서 10진수 대신 16진수를 더 많이 사용한다.
2의 보수법
- 0과 1만으로 음수를 표현하는 방법 중 하나
- 어떤 수 n을 그보다 큰 2^n에서 뺀 값
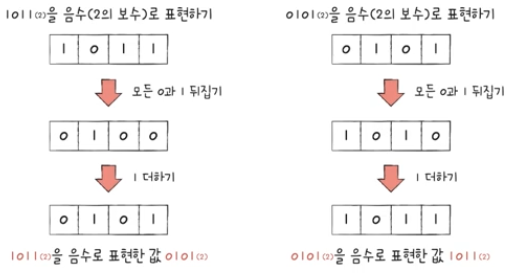
ex) 2진수 11의 2의 보수는 2진수 100에서 뺀 01 - 위 방식보다 조금 더 간편한 방법:
2진수에서 모든 0과 1을 뒤집은 뒤, 1을 더한 값
Q)
2의 보수는 왜 사용하는가?
A) 컴퓨터 내부에서는 말 그대로 0과 1만을 이용하기 때문에 음수 기호(-)를 사용할 수 없다. 따라서 0과 1로 음수를 표현하기 위해 2의 보수를 사용한다.
Q) 그럼2의 보수가 음수 역할을 제대로 수행하는가?
A) 위 사진에서 보듯이 2진수 1011을 음수로 표현하면 0101이 된다. 여기서 0101을 다시 음수로 만들어 보면 원래 자기 자신이었던 1011이 된다.
따라서2의 보수는 음수 역할을 할 수 있다고 볼 수 있다.
그럼 0과 1만으로 음수를 표현하면, 2진수만 봤을 때 그것이 양수인지, 음수인지 어떻게 구분하는가?
CPU 내부에 레지스터 중에서 플래스 레지스터라는 것이 있다.
플래그 레지스터는 flag라는 특별한 정보를 저장하기 때문에 특별한 레지스터이다.
flag라고 하는 특별한 정보란?
-> CPU가 명령어를 실행하는 과정에서 참고할 정보의 모음이다.
따라서 음수 flag가 세팅되어 있을 경우(음수 flag가 1인 경우) -> 음수
음수 flag가 세팅되어 있지 않은 경우(음수 flag가 1이 아닌 경우) -> 양수
부동 소수점
Python
a = 0.1
b = 0.2
c = 0.3
if a + b == c:
print("Equal")
else:
print("Not Equal")C
#include<stdio.h>
int main() {
double a = 0.1;
double b = 0.2;
double c = 0.3;
if (a + b == c) {
printf("Equal\n")
} else {
printf("Not Equal\n")
}
return 0;
}Java
public class FloatingPointComparison {
public static void main(String[] args) {
double a = 0.1;
double b = 0.2;
double c = 0.3;
if (a + b == c) {
System.out.println("Equal");
} else {
System.out.println("Not Equal");
}
}
}위 코드들의 실행결과는 모두 Not Equal이다.
왜냐하면 컴퓨터 내의 소수점 표현 방식의 한계가 있기 때문이다. (부동 소수점의 한계 때문)
컴퓨터는 우리가 표현하는 소수점과 같은 방식으로 정확하게 소수점을 표현할 수가 없다.
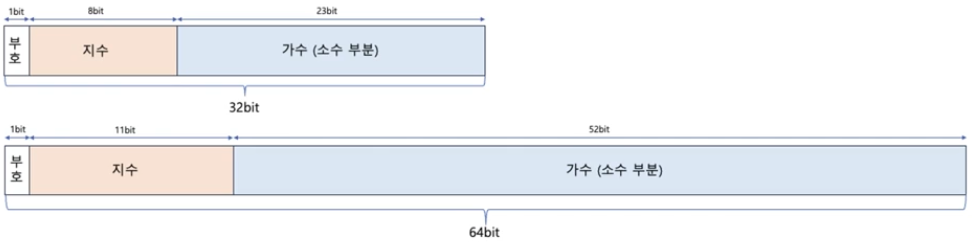
컴퓨터 내부의 소수 표현 방식(부동 소수점 표현 방식)


컴퓨터 내부에서는 2진수를 m * 2^n꼴로 나타내고 가수 부분은 1.XXX 꼴을 띄고 있다. (1.XX 꼴로 고정되어 있음.)
2진수
1101011.1010101를m * 2^n꼴로 나타낸다고 가정했을 때,
1.1010111010101 * 2^6으로 표현한다.
참고로 가수 부분은 모두 1.XX꼴로 고정되어 있기에 1은 굳이 저장할 필요 없다. XXX 부분(소수 부분)만 저장하면 된다.
그리고 지수 부분 n을 저장할 때에는 bias 값이 더해져서 저장된다.(예를 들어 음수가 나오면 계산하기 번거롭기 때문에 bias라는 특정 값이 더해진 채로 저장이 된다.)
bias 값은 2^(k - 1) - 1 (k는 지수의 비트 수)
만약 지수 비트에 8비트가 사용이 된다면 bias 값은 2^7-1
위와 같은 표현의 문제
10진수 소수를 2진수로 표현할 때 10진수 소수와 2진수 소수 표현이 딱 맞아 떨어지지 않을 수 있다.
ex) 분수 1/3을 m * 3^n 꼴로 표현하면 딱 떨어진다.
ex) 분수 1/3을 m * 10^n 꼴로 표현하면 무한히 많은 가수가 필요하다.
마찬가지로,
ex) 분수 1/10을 m * 10^n 꼴로 표현하면 딱 떨어진다.
ex) 분수 1/10을 m * 2^n 꼴로 표현하면 무한히 많은 가수가 필요하다.
일부 10진수 소수를 표현하는데 있어서 무한히 많은 가수가 필요한 2진수 소수꼴이 있을 수 있다.
그럼 컴퓨터 내부에서는 소수를 저장할 때 위 사진과 같은 형태로 저장을 하는데, 가수를 저장할 수 있는 공간이 정해져 있다.
그래서 무한히 많은 가수가 필요한 경우에는 일부 가수를 버릴 수 밖에 없다.
따라서 오차가 발생할 수 있다.
그런 오차 때문에 0.1 + 0.2 결과가 완전히 0.3과 동일하지 않을 수가 있다.
문자 인코딩과 디코딩
0과 1로 문자 표현하기
문자 집합(Character Set): 표현 가능한 문자들의 집합문자 인코딩: 문자를 0과 1로 이루어진 문자 코드로 변환문자 디코딩: 0과 1로 이루어진 문자 코드를 문자로 변환
아스키 코드(ASCII Code)
아스키 문자 집합: 초창기 문자 집합. 알파벳 + 아라비아 숫자 + 일부 특수 문자 + 제어 문자
아주 기본적인 문자 집합 및 인코딩 방식.
따라서 오늘날 대부분의 문자 집합, 인코딩, 디코딩 방식은 아스키 코드와 호환되는 경우가 많다.
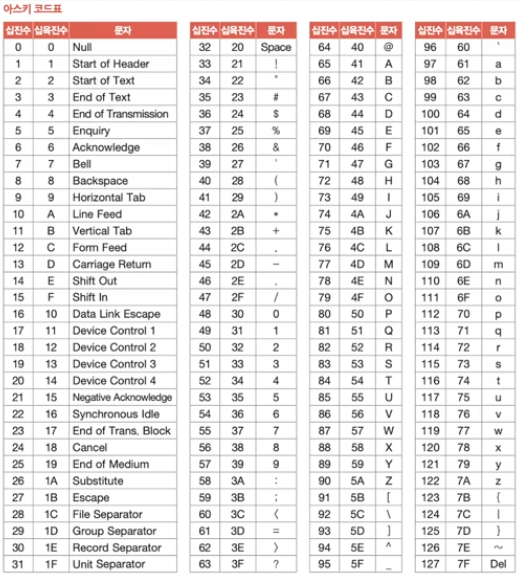
아스키 코드는 기본적으로 8비트를 이용해서 표현한다. 그중 한 비트는 오류 검출을 위한 공간이기에 실질적으로는 7비트가 사용된다.
따라서 2^7인 128개의 문자집합이 있는 것이다.
각각의 번호에 대응되는 문자가 있으며, 대응된다는 것이 인코딩을 의미한다.
예를 들어 아스키 코드에서 a는 97로 인코딩 된다.
컴퓨터가 97이라고 하는 10진수를 문자로 읽으면 a로 인식하고
10진수로 읽으면 97로 인식한다는 것을 의미한다.
이렇듯, 아스키 문자 집합에 포함되어있는 대응값을 출력해주는 것을 아스키 인코딩이라고 부른다.
아스키 문자집합의 문제점 -> 한글을 비롯한 다양한 언어들을 표현할 수가 없다.
나라마다, 언어마다 문자집합을 만들수도 있지만 그렇게 하면 다국어를 지원하는 웹사이트가 있다고 가정했을 때,
그 모든 인코딩 방식을 일일히 지정해서 대응을 해줘야 하는 번거로움이 있다.
따라서 '나라마다, 언어마다 각기 다른 언어 인코딩 방식을 지원하지 말고, 통일된 문자 집합과 인코딩 방식을 사용하자' 해서 나온 방식이 유니코드 문자 집합, 인코딩 방식인 UTF-8, UTF-16 등이다.
유니코드 문자 집합
대부분의 언어 + 특수문자 + 이모티콘 + 화살표 + 기타 등등
아스키 코드의 문자 인코딩 방식이 단순하게 대응하는 것이라면,
유니코드는 같은 문자집합이라고 할지라도, 인코딩하는 방식이 다양하다.
유니코드 홈페이지에서 보듯이 유니코드는 문자마다 4자리 16진수가 부여되어 있다.(U + 4자리 16진수)
그 4자리 16진수 값을 유니코드 코드 포인트 라고 부른다.
유니코드 코드 포인트: 유니코드 문자에 부여된 고유한 수
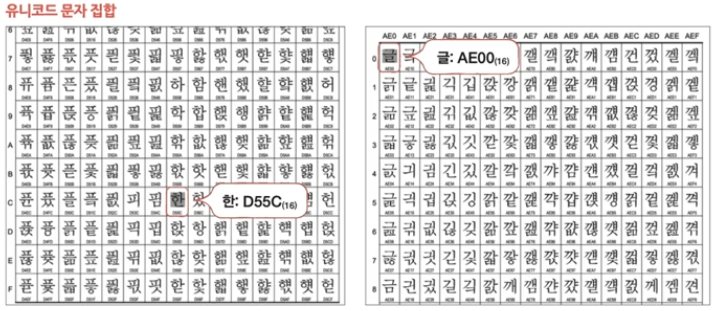
위와 같은 방식으로 유니코드 문자 집합에서는 지원되는 문자집합마다 코드 포인트를 부여한다.
Q) 유니코드 문자 집합은 아스키 문자 집합을 인코딩하는 방식처럼 문자 집합에 속해있는, 문자에 부여되어있는 코드 포인트를 그냥 인코딩 된 값으로 사용하는가?
A) No
유니코드 코드 포인트를 어떻게 인코딩하는지에 따라 유니코드 인코딩 방식이 UTF-8, UTF-16, UTF-32 등으로 달라진다.
즉, 유니코드 문자 집합을 인코딩하는 다양한 방법들이 있다.
참고 사이트) 코드 포인트
