[작성중] DenseCLIP : Language-Guided Dense Prediction with Context-Aware Prompting | paper review
Intro
최근에 Domain Generalization Semantic Segmentation(DGSS)을 고민하면서 어떤 객체의 semantic한 attribute까지 이해하는데에는 Language 정보가 결합되어야 할 것 같다는 생각이 계속 들었고, segmentation task를 language가 보조해주는 모델들을 찾고 있었다.
그 중 CVPR 2022에 나온 DenseCLIP의 아키텍처가 직관적으로 내가 찾고자 하는 모델과 가장 가깝고, 또 한국어 블로그 리뷰가 존재하지 않아서 직접 리뷰해보기로 하였다.
본 리뷰는 내 이해를 바탕으로 재구성 되어 논문의 논리 전개 순서와 다를 수 있으며 사견이 포함되었다. 또한 DGSS를 위한 고려할만한 파트도 함께 기술되었다.
Leveraging knowledge from CLIP
" CLIP의 뛰어난 능력을 더 복잡한 dense prediction에도 transfer 할 수 있을까 ? "
CLIP은 image와 text 사이의 semantic relationship을 학습하게 하여, 이미지 분류에서(특히 제로샷에서) 매우 뛰어난 결과를 보여주었다. 이후 많은 연구들이 CLIP을 활용하였으나, 주로 image-level의 downstream task에만 활용하였다.
본 논문은 CLIP의 knowledge를 잘 활용해서 dense prediction task 에서도 잘 수행하기를 바란다. 하지만 이것이 어려운 이유는 아래의 갭 때문이다.
Upstream pre-training task: image와 text사이의instance-levelrepresentation을 학습하였음.Downstream dense prediction: image의pixel-levelrepresentation을 학습해야 함.
본 논문은 이 문제를 CLIP의 image-text matching을 pixel-text matching로 전환하는 관점에서 접근하며, "Language-guided dense prediction framework" 인 DenseCLIP를 제안한다.
Model Overview
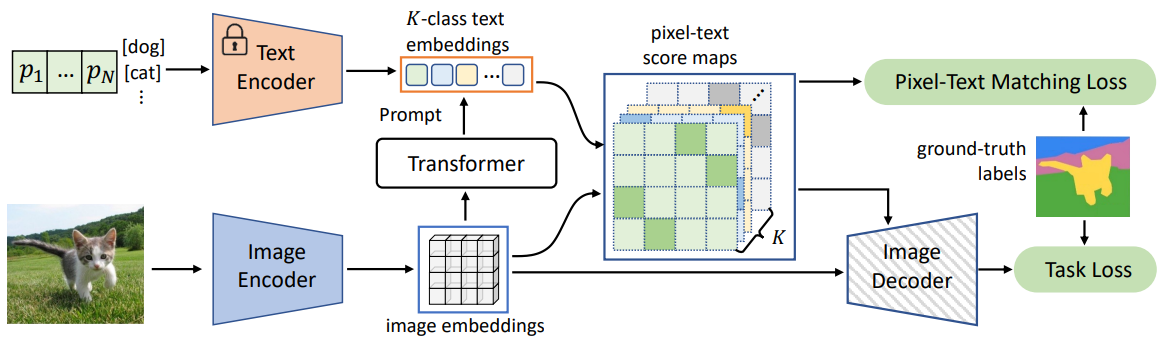
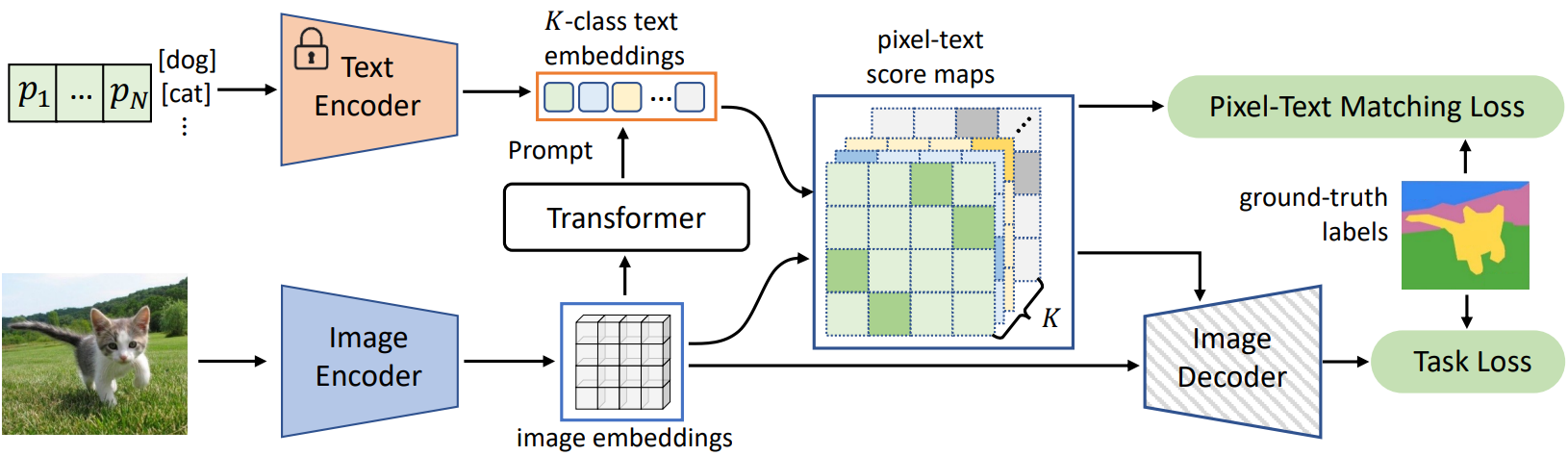 Semantic Segmentation을 위한 DenseCLIP의 아키텍처는 위와 같다.
Semantic Segmentation을 위한 DenseCLIP의 아키텍처는 위와 같다.
DenseCLIP은 먼저 두 Encoder로 image embedding과 K-class text embedding을 뽑는다. 그 후, 앞서 설명한 pixel-text matching에 해당하는 pixel-text score maps를 계산하여 dense prediction에 활용한다. score map은 Decoder로 fed되며 동시에 그 자체를 GT와 matching loss도 건다.
구현 디테일은 다음과 같이 구성되어 있다.
Image Encoder: CLIP-ImageEncoder ( or ImageNet pretrained ImageEncoder )Text Encoder: CLIP-TextEncoderContext Decoder: TransformerNeck: FPN neckImage Decoder: FPN head
정보) 구현 코드에서 Image Encoder -> backbone, Image Decoder -> decode_head
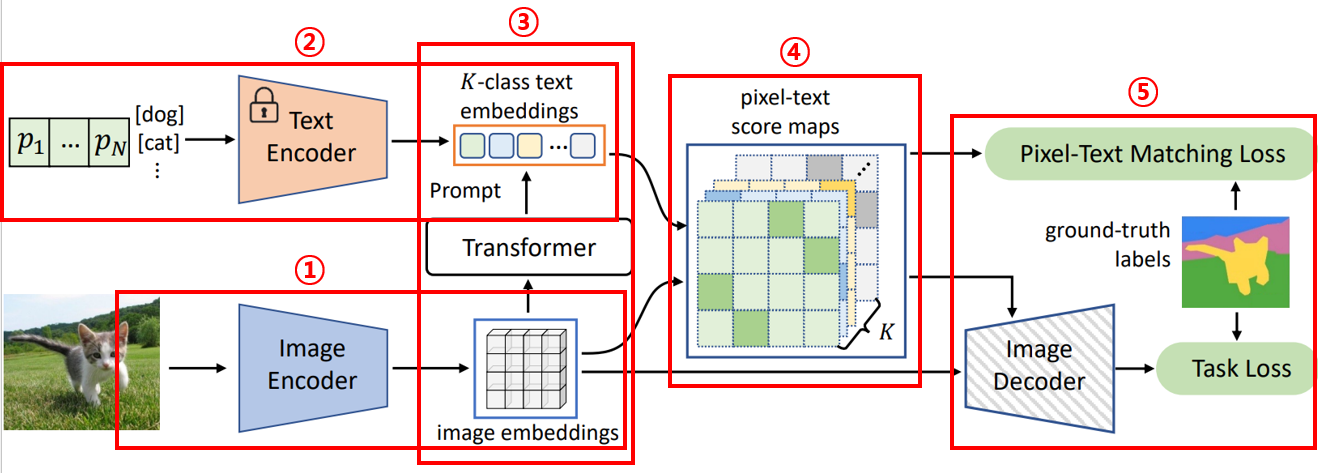
더 구체적인 기술은 위 그림과 같이 다섯 파트로 나누어서 기술하고자 한다
- Image embedding
- Language-domain prompting
- Vision-to-language prompting
- Pixel-text score maps
- Train Losses
1. Image embedding
: visual embedding
: global embedding
is language-compatiable feature map, which has spatial information
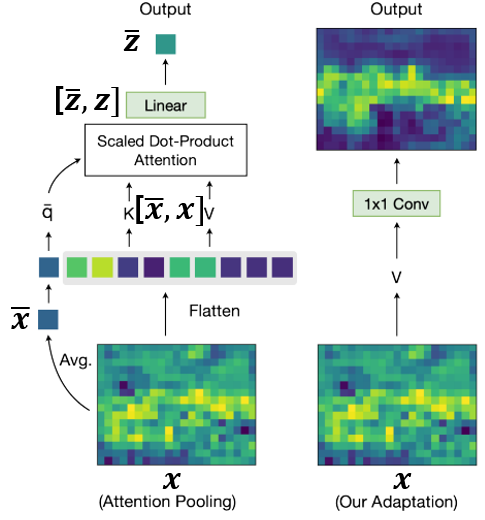
CLIP Image Encoder는 일반적인 Image Encoder의 마지막 단에 attention pooling layer 라는 것을 단다. 원래의 마지막 layer output이 라고 하면, 우선 global average pooling을 통해 global feature 인 를 얻고, 둘을 concat한 를 multi-head self-attention layer에 fed 시켜 최종 output인 를 얻는 것이다.

CLIP의 학습에서는 원래 를 무시한 채 만 사용하지만, 저자들은 의 다음과 같은 특성을 발견한다.
- 는
spatial information을 여전히 잘 유지해서feature map으로 쓰일 수 있다. - 는 또한
language와 잘align된다. ( 처럼)
이러한 관점에서, 저자들은 를 language-compatible feature map으로써 exploit 하고자 한다. 그래서 일반적인 CLIP Image Encoder와 다르게, 또한 output으로 사용한다.
참고로, MaskCLIP 이라는 논문에서도 CLIP으로 dense prediction을 하기 위해서 language와 align이 되면서도 spatial한 정보를 갖는 feature map을 얻고자 한다. DenseCLIP과는 다르게, MaskCLIP에서는 아래 그림과 같이 에서 바로 1x1 Conv를 이용해 바로 사용한다. 퀄리티를 비교해봐야겠지만, 직관적으로는 DenseCLIP의 방식이 좀 더 language-aware 할 것 같다는 생각이 든다. 를 대신할 다른 language-compatible feature map을 얻는 방법을 고민 할 수는 있지만, 굳이 건들이고 싶지는 않다.
2. Language-domain prompting
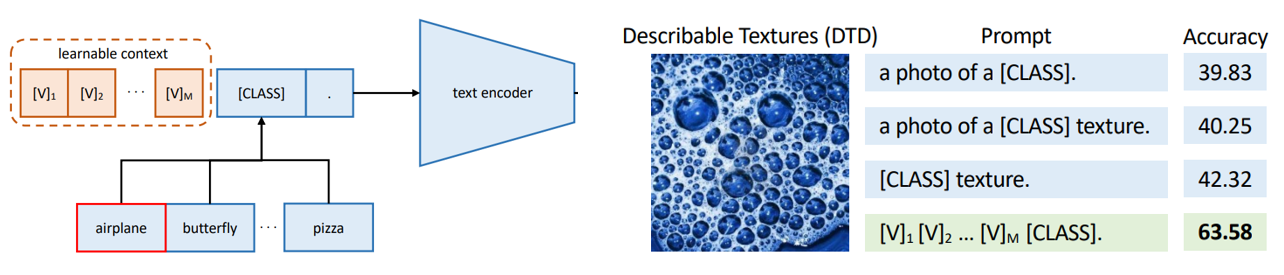
CLIP에서 " a photo of a [CLS] " 와 같은 템플릿의 text prompt를 이용했던것과 달리, CoOp이라는 논문에서는 textual context (a photo of a 부분) 을 learnable하게 학습시켜 downstream task에서 더 높은 성능을 보여주었다.
 본 논문에서도
본 논문에서도 CoOp을 사용하여 각 class(dog, cat, ...)의 text embedding을 얻는다. 총 개의 class에 대해서, 가 각 -th class의 word-embedding이고 가 learnable textual context의 리스트라고 하면, -th class의 text embedding을 얻기 위한 text prompt는 가 되는 것이다. 가 학습이 완료 된다면 각 class에 대한 text embedding이 고정 되기 때문에 inference time에는 text encoder을 사용하지 않아도 된다!!
한편,DenseCLIP의 framework를 베이스로 연구한 논문인 ICPC(2023.08)에서는 DenseCLIP의 CoOp 방식이 image embedding과 text embedding을 잘 align하지 못한다고 주장한다(T-SNE). 그러면서 instance-conditioned context 라는 것을 추가적인 textual context로 도입하여 를 text prompt로 한다. 이때 는 각 image content에 conditioned한 dynamic한 vector로, 로 정의된다. 이미지 정보를 프롬프팅에 활용해서 더 좋은 align을 이끌겠다는 것인데, 이 경우 inference time에도 text encoder을 사용해야만 한다는 단점이 있다. 그 단점에 비해 DenseCLIP과 큰 성능차이(1% 미만)를 낸 것도 아니라서, 그렇게 좋은 방식은 아닌 것 같았다.
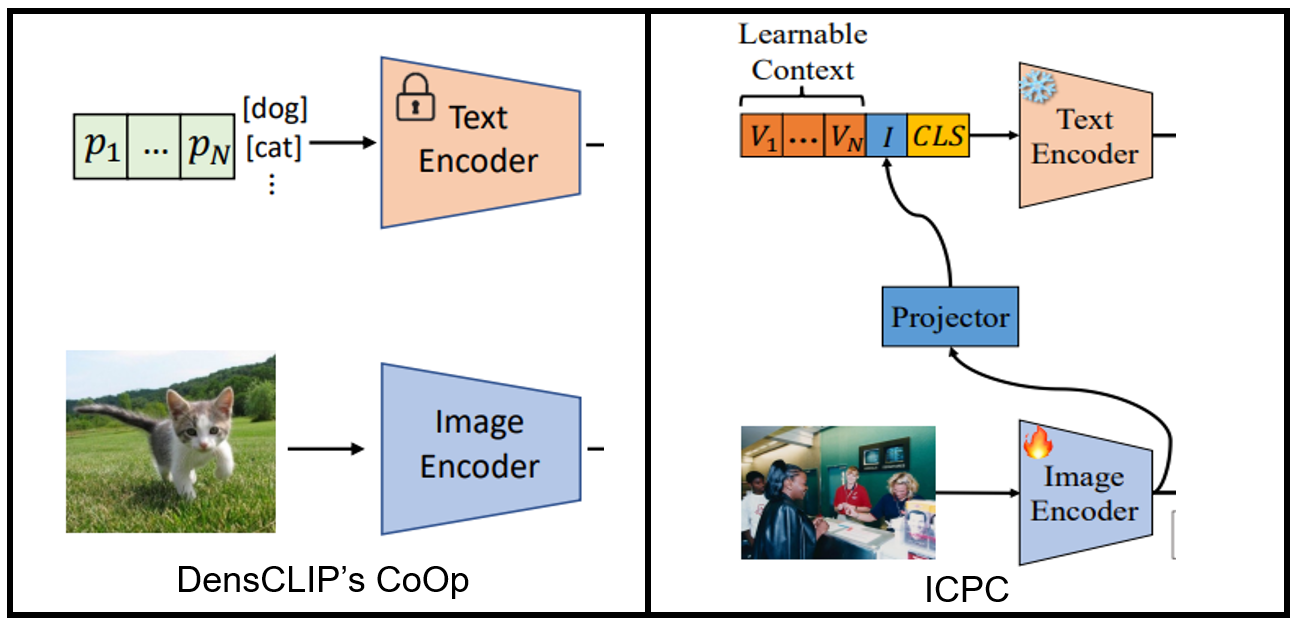
어찌되었든 DenseCLIP을 업그레이드 하기 위한 시도로써 prompt 디자인도 하나의 요소라는 것을 알게 되었다. 가령 DGSS 세팅에서 GTA에서 학습된 가 domain에 overfitting 된다면 Cityscapes에서 성능저하를 일으킬 수 있기 때문이다. ADE20K -> Cityscapes에서 어느정도 잘 하는 것으로 보여 그럴 가능성은 적어 보이지만, DGSS를 위한 적절한 prompt 방식이 있을지 고민해볼 필요는 있다. (CoCoOp 또한 ICPC처럼 image embedding을 text prompt에 활용하여 class에 overfitting을 방지하는 효과를 거두었다.)
3. Vision-to-language prompting
Vision-to-language prompting은, Vision 정보를 결합해 text embedding을 강화하는 과정이다. 저자들은 이미지의 visual context(appearance, shape, etc..)를 활용해 더 정확한 text feature로 refine할 수 있다고 주장하며 두 임베딩에 cross-attention을 적용한다.
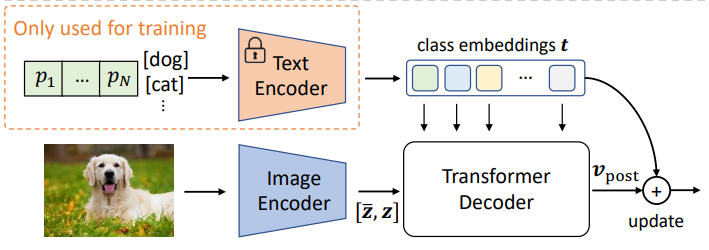
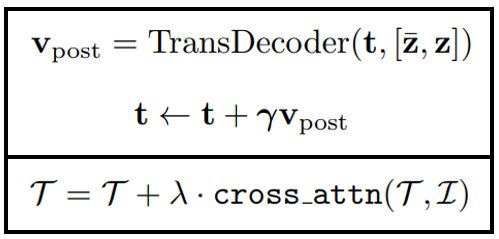 그림과는 윗 박스의 식과 비교하면 된다.
그림과는 윗 박스의 식과 비교하면 된다. cross-attention을 적용하기 위해 transformer decoder을 이용한다. 아랫 박스의 식은 ICPC논문에서 더 직관적으로 수식으로 표현한 것 같아 가져왔다. (가 text embedding, 가 image embedding)
이 파트는 text embedding과 image embedding으로 부터 바로 correlation을 구하기 전에 미리 잘 align하도록 도와주는 파트라는 생각이 들었다. 나중에 CLIP image encoder 대신에 ImageNet pre-trained image encoder을 사용하는데 그 친구에게는 이 과정이 유의미할 것 같다. 확실한건 ImageNet backbone에서 score map을 visualization 해봐야 한다.
4. Pixel-text score maps
최종적으로 text embedding 가 완성되면, 이제 framework의 핵심 재료인 pixel-text score maps 를 만든다. 아래 식에서 식에서 와 에 ^이 붙어 있는것은 normalize를 의미하며, 는 두 임베딩의 단순 행렬곱(similarity)으로 계산되어 진다.
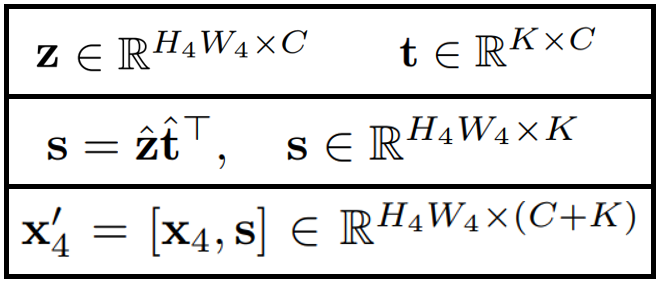
그 이후 score map은 image encoder의 와 concat되어 decoder로 들어간다. 주의할 점은 가 아니라는 점이다!(원래 가 image encoder의 original output이다.)
concat하는 방식이 간단하고 효율적으로 score map을 adapt하는 방식이지만, 뭔가가 아쉽다. score map만 사용해서 segmentation mask를 만들면 퀄리티가 얼마나 다를지, SAM의 임베딩이랑 concat해서 더 많은 spatial한 정보를 얻으면 어떨지, score map을 SAM decoder의 prompt로써 활용하면 어떨지,
5. Train Losses
image encoder이 학습되는데, image encoder가
Any backbone ?
Is DenseCLIP only suitable to CLIP image encoders?
Although there are no strong correlations between the feature maps of the new backbone and the text features output by the CLIP text encoder, we hypothesize that if we preserve the language priors by freezing the text encoder as before, the text encoder will guide the backbone to better adapt to downstream tasks.
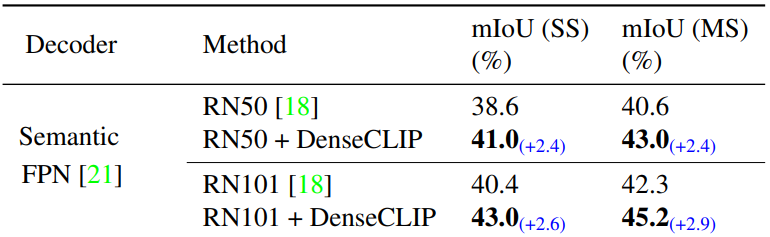


- ImageNet만 쓰는거보다 ImageNet에다가 denseCLIP의 language guide를 추가한게 더 잘 됬다.(왜?)
- 하지만 CLIP image encoder 쓰는것 만큼 잘 나오지는 않았다. 아무래도
pixel-text score map의 퀄리티 차이가 많이 날 것 같다. - ImageNet 대신에 SAM pretrained image encoder(ViT-b)만 사용하면 성능이 어떻게 될까? CLIP보다 좋아질 수 있을까? (마찬가지로
pixel-text score map퀄리티가 떨어져서 어려울 것 같다) - 그럼 image encoder을 두 개 쓰는 방법은 ?
