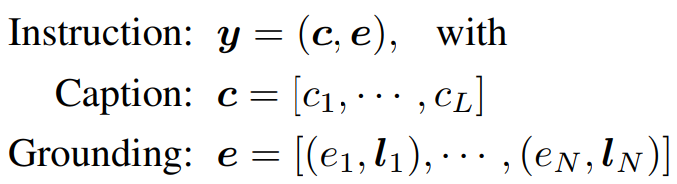
0. Review Objective
- 8월 WG세미나에서 GLIGEN과 ReGround를 엮어서 발표할 예정
- 특히 현재 중요하게 사용되고 있으므로
- 이미 한 번 발표 됬으니 가볍게만 리뷰
1. Introduction
- LDM은 text-to-image에서 대단한 성과를 거두었지만, text만 이용해서는 우리가 원하는 정도로 생성할 이미지를 컨트롤 할 수 없다.
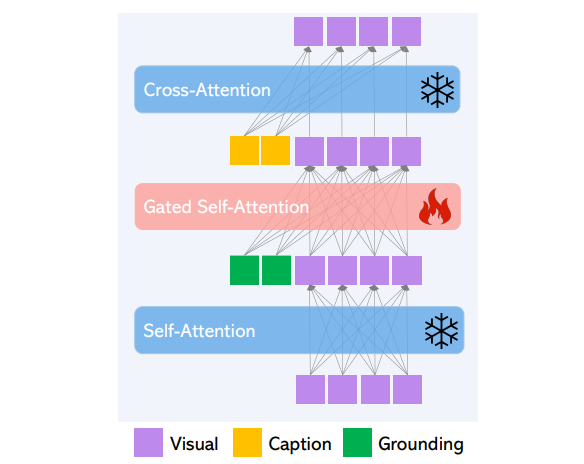
- 사전학습된 LDM을
groundinginput으로 컨디셔닝 할 수 있도록 기능을 확장한 모델 GLIGEN(Grounded-Language-to-Image-Generation)을 제안 - 사전학습 정보를 보존하기 위해서, LDM 기존 layer는 모두
freeze시키고, grounding information을 삽입 할 수 있는 새 학습가능한 layer를 삽입해서 grounding dataset에 continual learning을 하였다. - layer은 또한 constant 를 on/off가 가능해서,
scheduled sampling로 trade-off 조절이 가능하다.
2. Grounding Instruction Input
-
GLIGEN의 목표는, 기존의 text-to-image model인 pre-trained LDM의 기능을 확장해서 grounding input으로 추가적인 conditioning을 하게 하는 것이다.
-
grounding input은 다음과 같이 정의 할 수 있다.
Instruction:Caption:Grounding:
-
Instruction 는 Caption 와 Grounding 로 이루어져있음
-
Grounding은
spatial configuration와grounding entity의 쌍들로 이루어져 있음 -
spatial configuration은 그라운딩 할 spatial 정보이며, 흔히
bounding box이다. bbox일 경우, 의 top-left와 bottom-right의 좌표로 정의 된다. -
grounding entity는 그라운딩할 semantic 정보로, text entity (of class name)을 사용하였다.
-
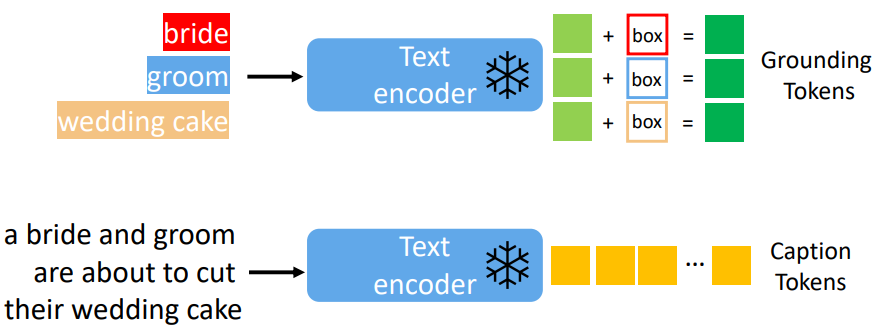
Caption Token: LDM 전처리와 동일; Caption을text encoder에 통과 시켜서 얻음. 단순히, -
Grounding Token: grounding token은 text entity feature과 bbox feature를 함께 MLP를 통과시켜서 얻는다. text entity는 LDM과 동일한 text encoder를 통과하고, bbox는Fourier embedding을 통과한다. -
저자들의 주장은, 새로운 layer를 closed-set인 COCO로 학습시켜도, 임의의 open voca에 대한 성능이 있다고 주장한다. 그 이유로 같은 text encoder 를 사용했기 때문이라고 한다.
3. Continual Learning for Grounded Generation
ㅇㅇ
