NEPA review
- paper: https://arxiv.org/pdf/2512.16922
- blog from author: https://sihanxu.me/nepa/
- github from author: https://github.com/SihanXU/nepa/tree/main
Review 이유
- Stella 랩에서 오랜만에 나온 general SSL method + saining xie가 참여
- 트위터에서 상당히 많이 언급되어 사람들이 관심이 많음을 확인
- 최근 본인이 SSL에 관심이 많음 + 특히 next token prediction에도 관심이 있음
Intro / Summarize
- LLM 처럼 next token prediction으로 vision SSL이 가능한지 보여주는 논문
- Why special?
- 트위터에도 '이게 왜 특별하냐?' '이미 있는거 아니냐', '성능 더 좋은거 많다' 라는 질문이 많음
- simple but effective 의의가 있는듯: no pixel decoder, no specific head, no contrastive pair
- vision에서도 next token prediction이 되는게 신기하긴 함 ㅇㅇ; ntp의 generaliabity를 보여줌
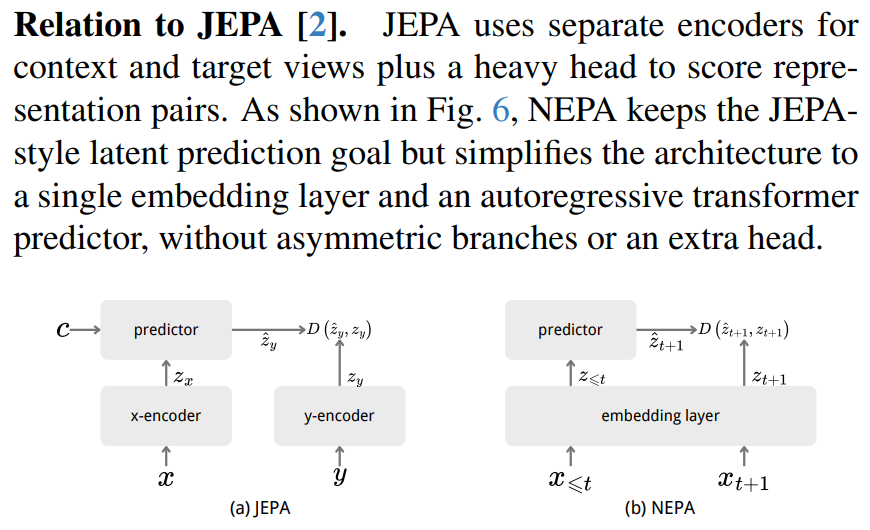
Architecture
- casual masking을 해야함으로 이를 반영한 ViT
- 이외의 modern techniques를 반영: QK-norm, swiglu(gatedMLP), layerscale, RoPE
- fair한가? 기존 SSL도 이런 테크닉을 적용한 다음에 비교해야하지 않은가? 실제로 modern technique가 성능에 영향 꽤 줌
- appendix에 MAE에 이 테크닉을 적용했을때 영향력이 없었던걸 보았을때, 뭔가 진짜 이 technique들이 NEPA랑 잘 align되나봄
- QK-Norm 등을 적용하지 않았을때 가끔 fail도 일어난 것을 보면 ntp가 조금 위험할(gradient explosion)수 있는 SSL일지도
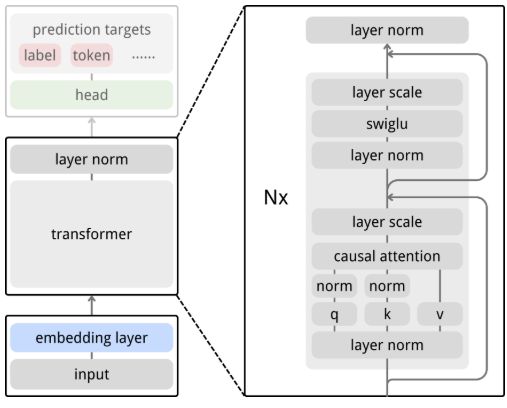

Algorithm
- 그냥 pseudo code가 전부임. 매우 simple. l2로 ntp를 regression (LLM은 voca classification)

- 중요한 포인트는 target에 stop gradient를 해줬다는 것임. LLM에서는 voca embedding에서 이런걸 할 필요가 없었으나 NEPA에서는 sg하지 않을 경우 collapse가 일어남
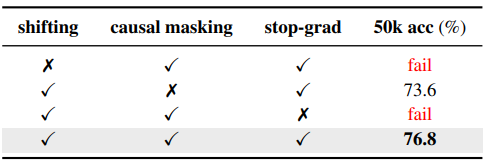
Performance
- imagenet-1k인데 DINOv2, PE 등과 비교 안한게 짜치긴 함 ㅇㅇ;; 그리고 base냐 large냐에 따라서 비교 모델이 다른걸로 봐서는 순위 변동 된 것으로 보임 ㅇㅇ;;
- 흥미로운점은 * 친 부분이 casual masking을 finetuning시에 유지한건데 역시 bidirectional로 fine-tuning한게 최종 성능이 좋았음
Questions
- LLM처럼 discretized voca로 할당하고 classification을 하도록 하면 어떨까? BEiT가 Bert버전이고 이게 GPT 버전인거 같은데??
- 질문해 봐야겠당
- 우려점: 결국 예측 대상인 embed가 raw pixels로 부터 16x16 conv 하나 거친거라서 raw rgb값과 shared information이 굉장히 높은 low-level feature 임. ViT encoder를 최종적으로 거치고 난 예측값이 low-level feature라면 뭔가 high-level abstraction을 배우기에는 불리할 것 같은 느낌이 듬
- embedding layer를 강화해보는건 어떨까? Early Conv see better 논문의 ConvStem이라던가 DINO-S/8을 embedding layer로 쓴다던가.
- 애초에 image는 text와 다르게 sequential order에 대한 correlation이 적합하지는 않은(성공은 했지만) 것 같음. Mamba 처럼 다른 방향의 scan도 고려해야할 지도?
Future work
- 저자는 'modality-agnostic'한 ntp의 potential을 언급하며, vision language의 unifying view를 언급했다. 요즘 image와 text를 한 번에 LLM에 넣는 연구도 많던데 정말 VLLM의 pretraining으로 사용될 수도 있을 것 같음
Etc
- 어우 이런 그림 너무 마음에 듬. Sihan Xu 홈페이지에도 이런 그림 있던데 뭔가 내가 좋아하는 포인트와 좀 비슷한 포인트가 있는듯 ㅎㅎ!