정글 6주차부터는 C언어 주차에서 레드 블랙 트리, malloc(동적 메모리 할당)에 대해 꽤(?) 깊이 있게 배우고 구현해볼 수 있는 경험을 가질 수 있었습니다.
뭐 여러 가지 생각으로 velog 글을 쓰지 않고 notion에다가만 정리하다
오랜만에, 8주차 발표로 준비했던 proxy 서버 동시성에 대해 적어볼까 합니다.

매 주 준비된 mission을 수행한 후, 발표전 날(수요일) 발표를 뭐하지?
생각하다 보면 mission 수행과 발표를 함께 준비해야 하는 딜레마에 빠지게 되었습니다.
그리고 그 이전에 겪었던 트러블 슈팅을 모두 기억해내는게 꽤나 어렵더라고요.
그래서 문제가 발생했을 때마다 notion에 정리를 하여 발표 시간을 줄이고자 했습니다.
proxy 서버 동시성
#include <stdio.h>
#include "csapp.h"
void doit(int fd);
void *thread(void *vargp);
int main(int argc, char **argv)
{
while (1)
{
clientlen = sizeof(clientaddr); /* sizeof(sockaddr_storage) */
int *connfdp = malloc(sizeof(int)); /* 스레드 간 공유 방지 */
*connfdp = Accept(listenfd, (SA *)&clientaddr, &clientlen); // line:netp:tiny:accept
/* 소켓 주소 구조체 -> 스트링 */
Getnameinfo((SA *)&clientaddr, clientlen, hostname,
MAXLINE, port, MAXLINE, 0);
printf("Accepted connection from (%s, %s)\n", hostname, port);
Pthread_create(&tid, NULL, thread, connfdp);
}
}
void *thread(void *vargp) {
int connfd = *((int *) vargp);
Pthread_detach(pthread_self()); /* 현재 스레드 작업이 종료되면 메모리 자원이 시스템에 의해 자동으로 반환 */
free(vargp);
doit(connfd);
Close(connfd);
}이번에 발표한 proxy 서버 동시성 코드입니다.
proxy 서버에 대해 이론적인 부분은 이해를 하였지만,
[출처: 위키피디아]
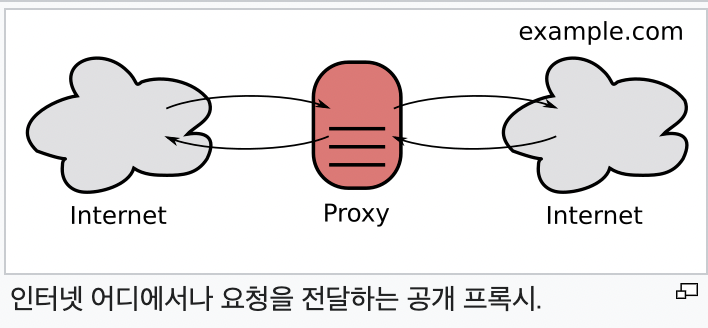
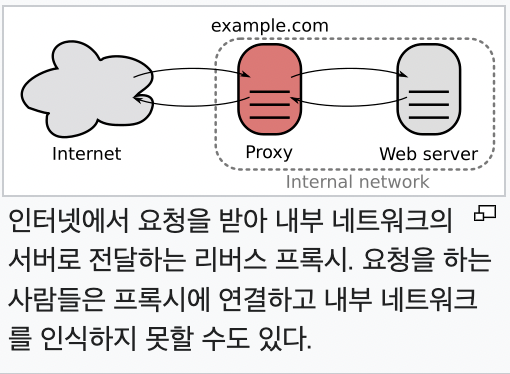
proxy는 클라이언트와 서버 사이에 중개기 역할을 하여,
익명성 유지, 보안 강화 성능 향상 등을 수행한다.
- Client -> Proxy (Request)
- Proxy -> Server (Request)
- Server -> Proxy (Response)
- Proxy -> Client (Reponse)
이렇게 proxy flow를 볼 수 있다.
그래서 이걸 어떻게 코드로 구현할 수 있는가?
참 막막했고, 그래서 구글링을 먼저 했고 구글링을 참조하여,
코드를 구현했고, AI의 도움도 받아 완성한 코드가 위 코드이다.
궁금했던 점
-
int *connfdp = malloc(sizeof(int)) /* 스레드 간 공유 방지 때문에 사용한다. */공유한다라고 하는데
포인터대신에int connfd를 사용해도 괜찮지 않은가?왜냐하면 Accept()를 호출하면 매 번 다른
connfd가 return 된다.(매 번 다른 connfd가 생성된다는 것은 매 번 다르기 때문에 공유되지 않을 것이다라고 생각)
그렇기 떄문에 int connfd로 사용해도 괜찮지 않은가?
❌ 아니다
- 모든 스레드가 같은 스택 변수
connfd의 주소를 참조하면서race condition 발생할 수 있음 - 결과적으로 여러 스레드가 같은 연결을 처리하게 됨
✅ malloc()을 사용하므로써, 매 번
힙 영역 주소를 전달하는게 맞다.그럼 malloc() 중간에 경합이 생기면 어떻게?
똑같은 영역을 공유하게 되는 건 아닌가?
❌ 그럴 일은 없음.
malloc()은 내부적으로 스레드 안전하게 구현되어 있고,- 매번 다른 주소를 리턴함.
- 심지어 스레드가 시작되기도 전에 주소가 달라지기 때문에, 이건 안전함
✅ 즉, malloc()은 그 시점에서 "주소를 다르게 분리"해주기 때문에 스레드 간 충돌이 없음
- 모든 스레드가 같은 스택 변수


[출처: stackoverflow]
-
세마포어를 적용하면 모든 스레드가 doit을 한 번씩 실행하기에,
포인터 대신 일반 변수를 사용할 수 있지 않을까?
void *thread(void *vargp) {
int connfd = *((int *) vargp);
Pthread_detach(pthread_self()); // 스레드 분리 시키기 due to 다른 스레드에 의해 종료될 수 없게
free(vargp);
doit(connfd);
Close(connfd);
}
void *thread(void *vargp) {
int connfd = *((int *) vargp);
Pthread_detach(pthread_self()); // 스레드 분리 시키기 due to 다른 스레드에 의해 종료될 수 없게
free(vargp);
P(s); // locking
doit(connfd);
Close(connfd);
V(s); // unlocking
}thread 실행 함수가 호출 되었을 때
doit()을 세마포어로 locking 해주고, close가 끝났을 때 unlocking 해준다면 위에
int *connfdp 가 아닌 int connfd로 하나씩 순차적으로 처리할 수 있지 않은가?라는 생각을 했는데
그렇게 되는 경우
- 결국 모든 스레드가
doit()을 순서대로 실행하게 만듦 - 그러면 스레드를 쓰는 의미가 사라짐
- 멀티스레딩이 아니라 그냥 직렬 처리(serial execution)
세마포어는 공유 자원 접근을 제어하는 동기화 도구인데,
여기서 세마포어로 공유 자원을 보호하는 것은 아니다라는 판단.
동시성 유지: 웹 서버의 목적은 여러 클라이언트를 동시에 처리하는 것이므로, 불필요한 동기화는 성능을 해치는 역효과가 있습니다.
오랜만에 velog 정리를 하면서 발표한 내용에 대해 회고도 해보았습니다.
감사합니다 :)
