최근 multi gpus을 가지고 놀수 있는 기회가 생겨 여러가지 시도하고 있으며, 그중 간단하게 분산학습을 사용 할 수 있는accelerate을 사용하여 분산 학습을 진행하였습니다.
일단 확실히 accelerate을 사용하면 torch.distributed 보다 single gpu 코드에서 쉽게 multi gpus 환경으로 확장을 할 수 있는 것 같다.
분산학습에서 추가적으로 많이 사용되는 라이브러리 deepspeed도 있지만 일단 transformers와 가장 연동성이 높고 간편하게 사용 할 수 있는 accelerate을 먼저 공부하였다.
그리고 accelerate는 deepspeed의 핵심 아이디어인 ZeRO 또한 DeepSpeedPlugin으로 쉽게 설정할 수 있다.
단 공식 문서 설명이 파편화 및 단순하여 체계적인 학습이 약간 어렵다.
본 글은 조금 더 깊게 들어가 accelerate 작동방식을 docstring과 함께 파악해보자(가장 좋은 방법은 코드를 확인하는 방법이지만...).
그리고 라이브러리 사용중 주의해야할 사항에 대하여 설명하겠다.
추가적인 설명 사항
- 본 글은 이미지 처리 예제로 설명 진행, 여기서 자연어 예제 확인 가능
- 본 글에서 사용한
accelerate의 version은 1.0.0이다. 보이듯이 최근에 정식으로 출시하였다. - Data parallelism에 한해서만 설명(DeepSpeed는 생략, 단 config로 쉽게 확장가능)
- 2개의 GPUs 환경에서 실험 진행(P4000x2)(paperspace에서 렌탈)
- 공식 문서의 예제로 진행하였으며 추가 설명 첨부
accelerate 간단 소개
accelerate는 단 몇 줄의 코드만 추가하면 모든 분산 구성에서 동일한 PyTorch 코드를 실행할 수 있다라고 주장하며 실제로 그러한 느낌을 받는다.
확실히 핵심 부분은 다음과 같이 간단하다.
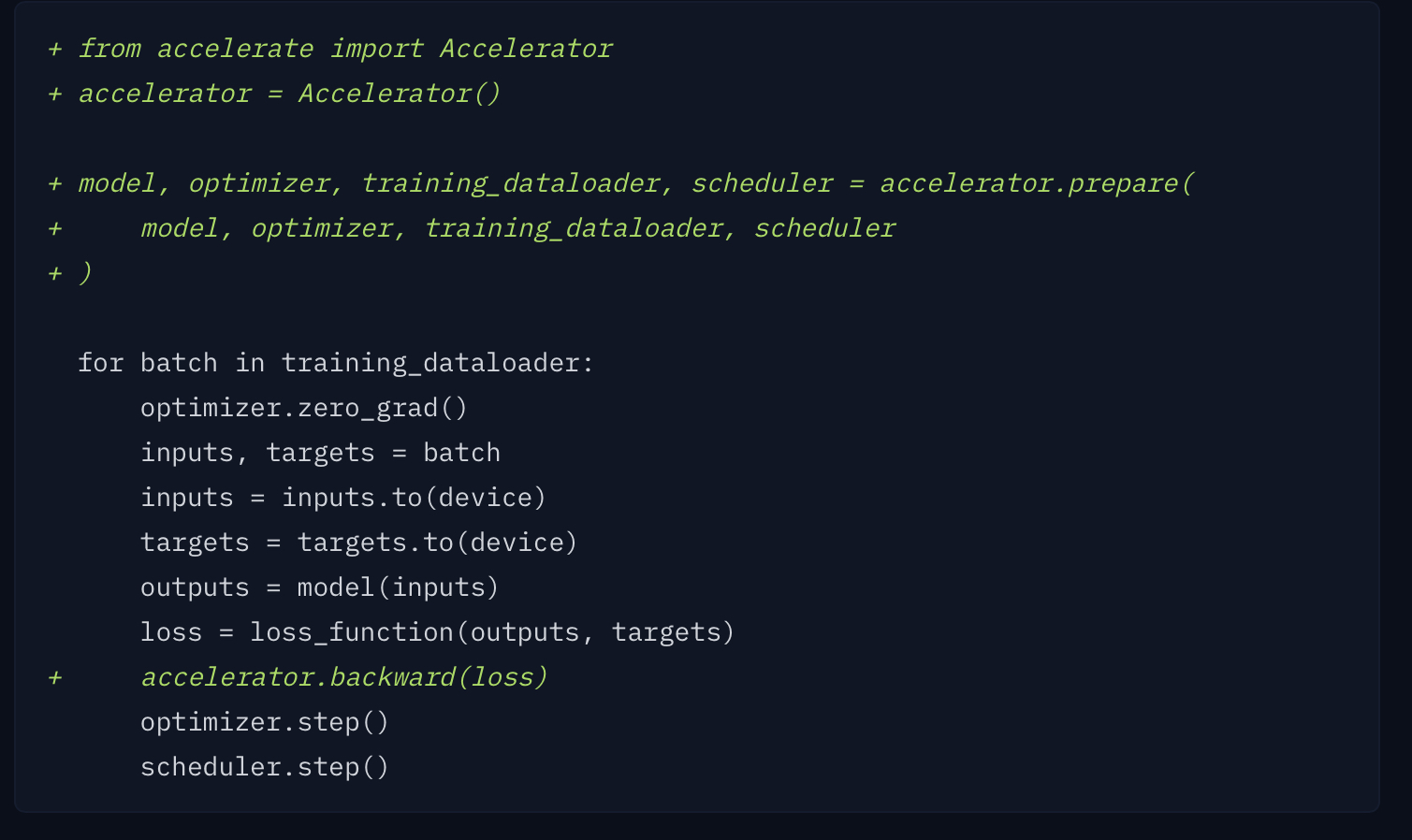
추가부분은 +로 삭제 부분은 -로 표기하였다. 이 표기법은 이후 코드에서도 사용된다.
+ from accelerate import Accelerator
from transformers import AdamW, get_scheduler
from timm import create_model
+ accelerator = Accelerator()
optimizer = AdamW(model.parameters(), lr=3e-5)
model = create_model("resnet50d", pretrained=True, num_classes=35)
- device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
- model.to(device)
+ train_dataloader, eval_dataloader, model, optimizer = accelerator.prepare(
+ train_dataloader, eval_dataloader, model, optimizer
+ )
num_epochs = 3
num_training_steps = num_epochs * len(train_dataloader)
lr_scheduler = get_scheduler(
"linear",
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=num_training_steps
)
progress_bar = tqdm(range(num_training_steps))
model.train()
for epoch in range(num_epochs):
for batch in train_dataloader:
- batch = {k: v.to(device) for k, v in batch.items()}
outputs = model(**batch)
loss = outputs.loss
- loss.backward()
+ accelerator.backward(loss)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
progress_bar.update(1)그리고 다음 명령을 실행하여 구성 파일을 생성하고 저장하고 확인할 수 있다
accelerate config다음과 같이 gif과 같이 설정 할 수 있다.
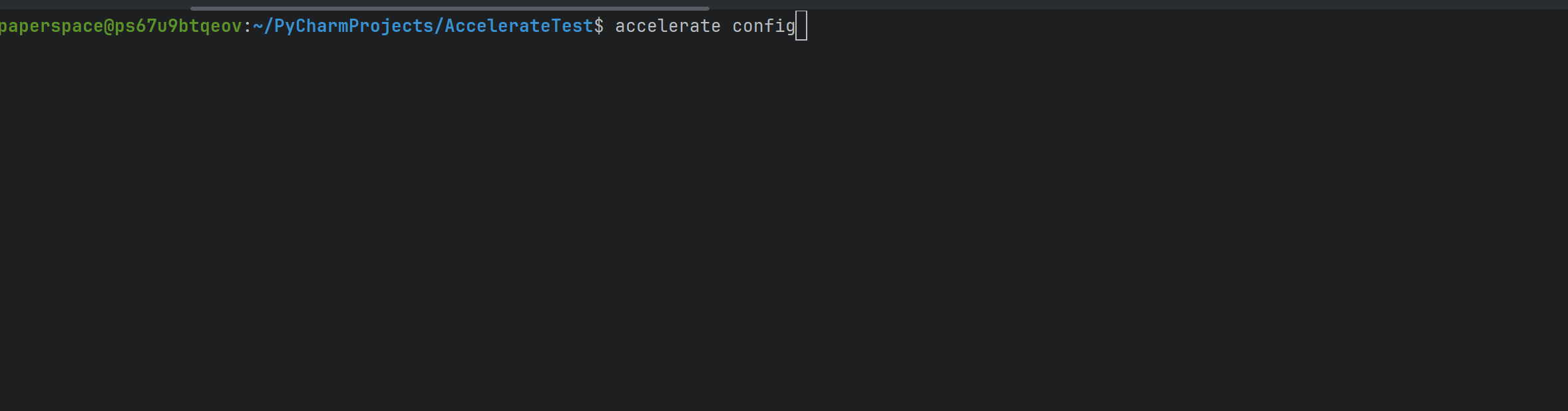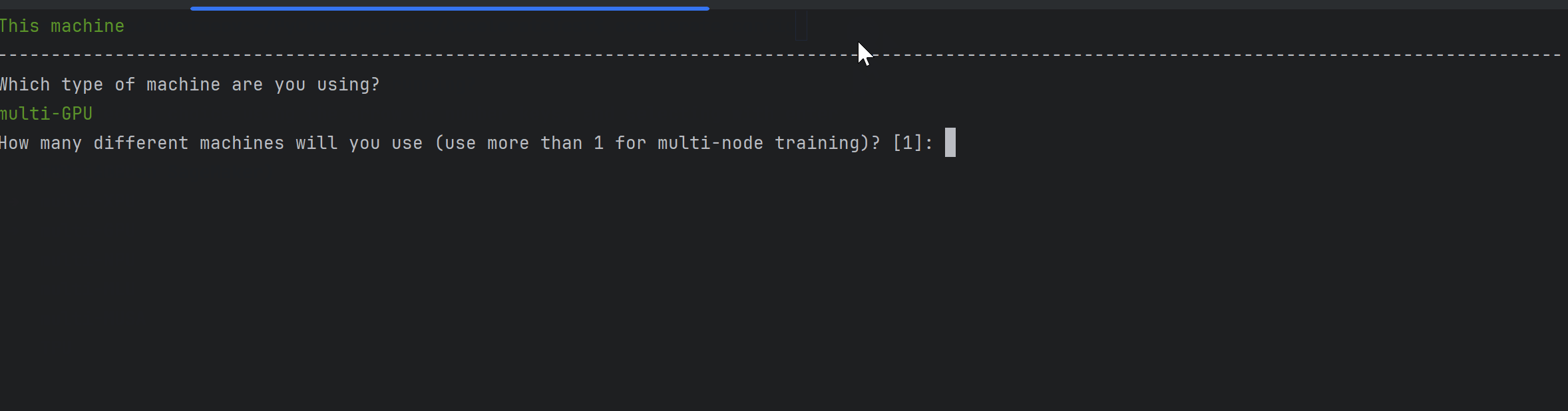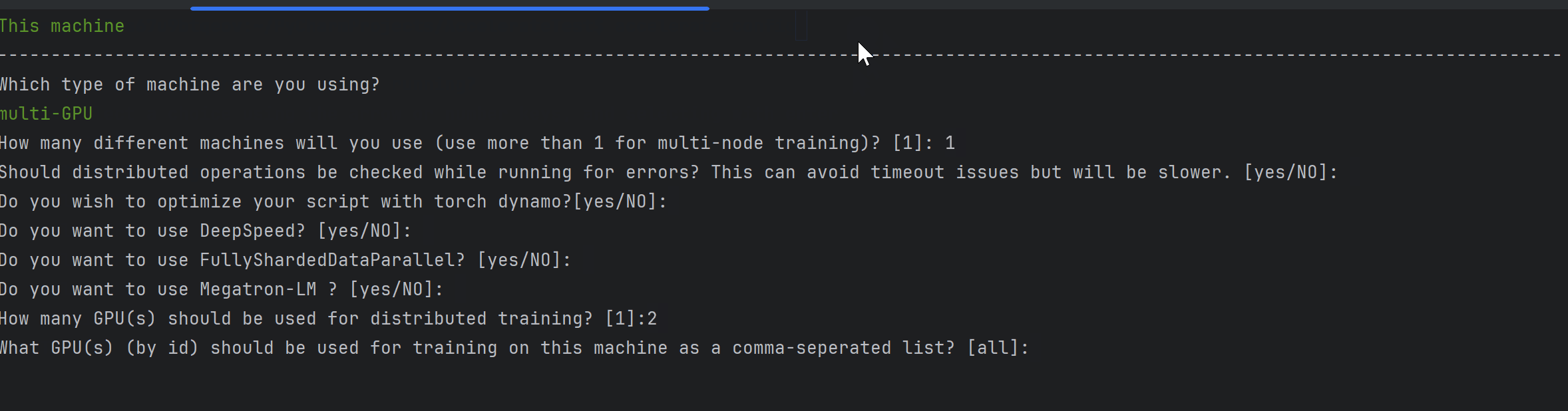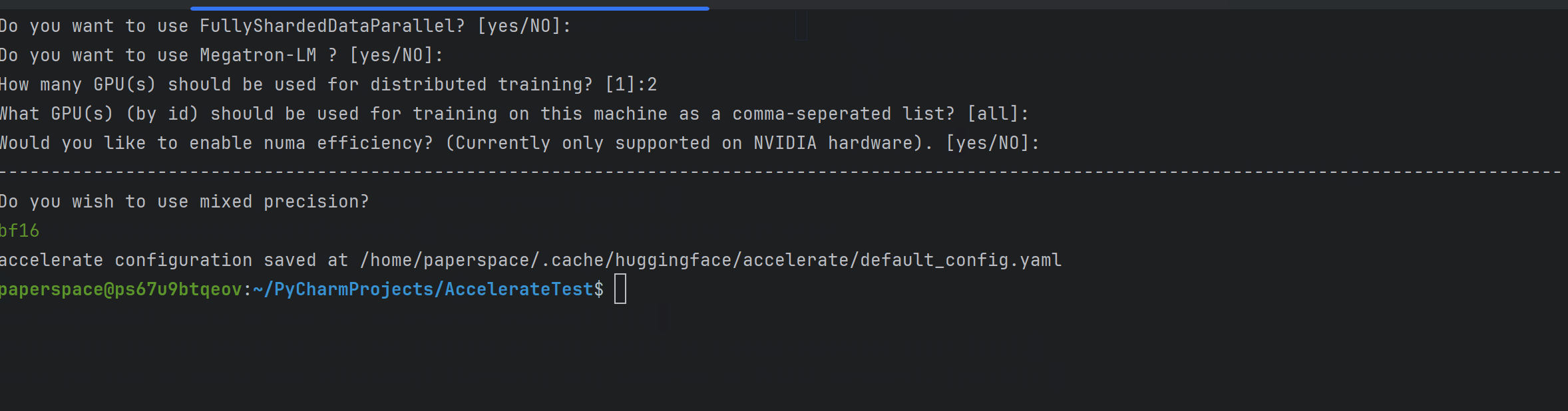
일단 여기서는 단일 노드(머신), 2 way gpus, 그리고 bf16 정밀도를 선택하였다.
config 결과 및 기기 정보는 다음 명령어로 확인 가능하다.
accelerate env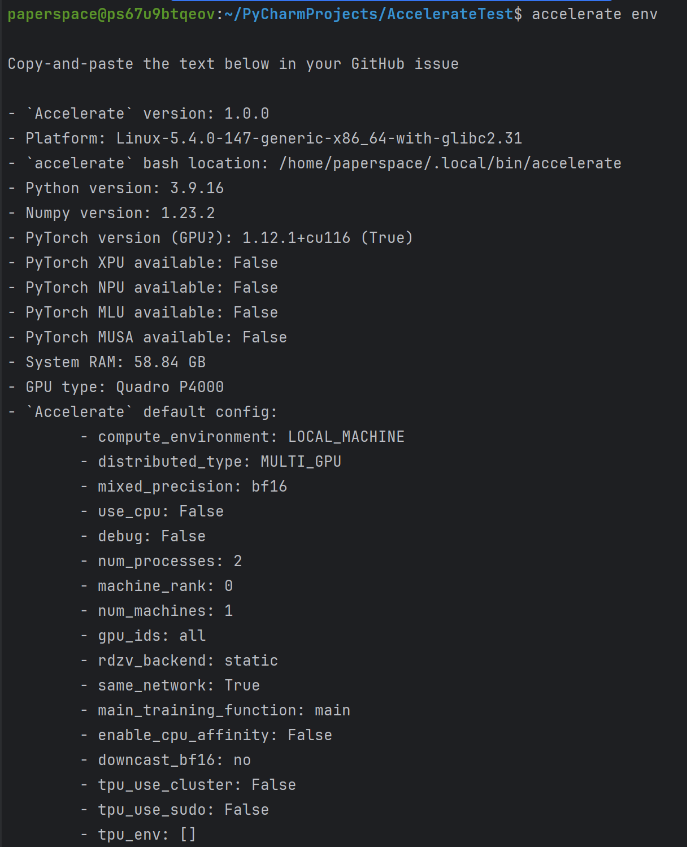
이후 다음 명령어로 분산 학습을 실행 할 수 있다.
accelerate launch train.py반대로 일반적인 python training.py는 분산 학습을 제대로 실행 할 수 없다.
accelerate launch train.py는 네이티브 torch에서 torchrun의 번거로운 인자 선택을 줄여줄 수 있다.
당연히 accelerate는 torchrun으로도 실행이 가능하다.
이후 모든 코드는 accelerate launch script.py로 실행 할 것이다.
학습데이터 소개
여기서 사용될 데이터는 accelerate 공식 예제에서 사용했던 The Oxford-IIIT Pet Dataset 이다.
총 35개 클래스(애완동물 종류)를 예측하는 아주 간단한 이미지 분류이다. 받은 데이터를 8:2로 train/valid로 나누어 실험 진행.
나누어진 데이터는 해당 링크로 다운로드 가능합니다.
코드
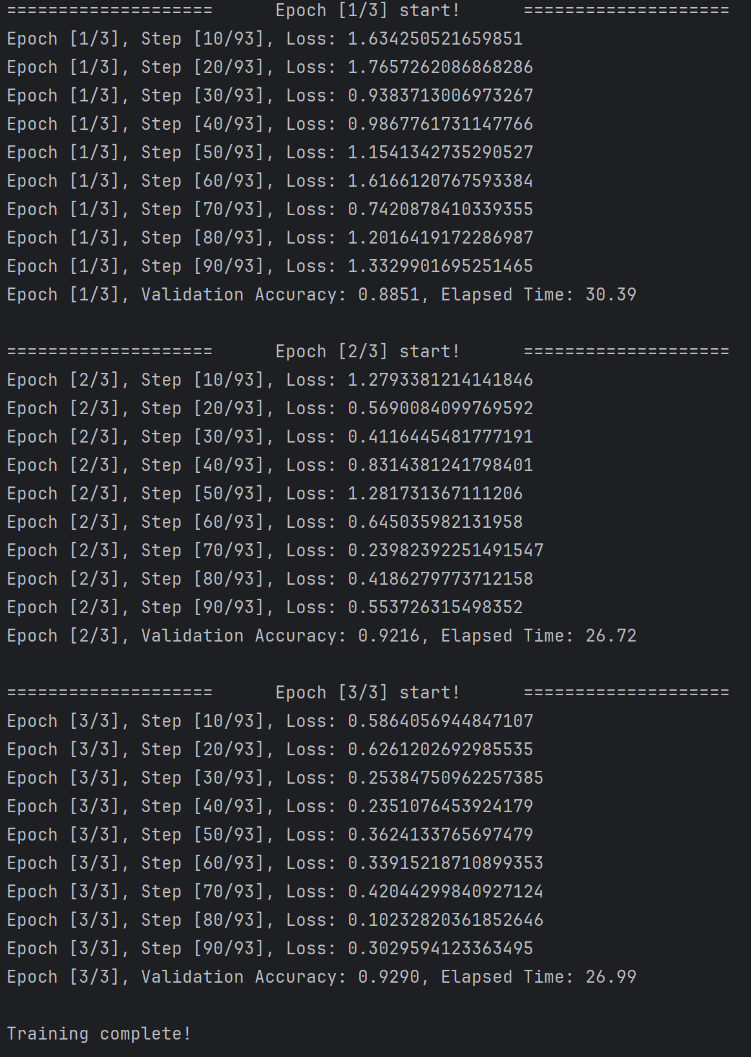
이후 분산 학습 코드와 비교하기 위해 먼저 normal 코드를 작성하였다. 심플한 코드이다.
import argparse
from pathlib import Path
from time import perf_counter
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision.datasets import ImageFolder
from torchvision.transforms import v2
from timm import create_model
from transformers import get_cosine_schedule_with_warmup
def get_args_parser() -> argparse.Namespace:
parser = argparse.ArgumentParser(description='Simple image classification with normal setting')
parser.add_argument('--lr', type=float, default=3e-2)
parser.add_argument('--batch_size', type=int, default=64)
parser.add_argument('--weight_decay', type=float, default=1e-3)
parser.add_argument('--epochs', type=int, default=3)
parser.add_argument('--log_step', type=int, default=10)
parser.add_argument('--dataset_path', type=str, default='~/MyData/OxfordIIITPetDataset/')
return parser.parse_args()
train_transforms = v2.Compose([
v2.Resize((224, 224)),
v2.RandAugment(5, 7),
v2.ToImage(),
v2.ToDtype(torch.float32, scale=True)
])
valid_transforms = v2.Compose([
v2.Resize((224, 224)),
v2.ToImage(),
v2.ToDtype(torch.float32, scale=True)
])
def main(args: argparse.Namespace):
dataset_path: str | Path = args.dataset_path
if dataset_path.startswith('~'):
dataset_path = Path(dataset_path).expanduser()
else:
dataset_path = Path(dataset_path)
train_ds = ImageFolder(root=str(dataset_path / 'train'), transform=train_transforms)
valid_ds = ImageFolder(root=str(dataset_path / 'valid'), transform=valid_transforms)
train_dataloader = DataLoader(train_ds, batch_size=args.batch_size, num_workers=8, shuffle=True)
valid_dataloader = DataLoader(valid_ds, batch_size=args.batch_size, num_workers=8, shuffle=False)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = create_model('resnet50d', pretrained=True, num_classes=len(train_ds.classes))
model = model.to(device)
for param in model.parameters():
param.requires_grad = False
for param in model.get_classifier().parameters():
param.requires_grad = True
optimizer = optim.AdamW(model.parameters(), lr=args.lr, weight_decay=args.weight_decay)
lr_scheduler = get_cosine_schedule_with_warmup(optimizer,
num_warmup_steps=5,
num_training_steps=len(train_dataloader) * args.epochs)
steps = len(train_dataloader)
loss_fn = nn.CrossEntropyLoss()
for epoch in range(args.epochs):
message = f"Epoch [{epoch + 1}/{args.epochs}] start!"
formatted_message = f'{message:^30}'
print(f"{'=' * 20}{formatted_message}{'=' * 20}")
start_time = perf_counter()
model.train()
for step, (x, targets) in enumerate(train_dataloader):
x, targets = x.to(device), targets.to(device)
optimizer.zero_grad()
logits = model(x)
loss = loss_fn(logits, targets)
loss.backward()
optimizer.step()
lr_scheduler.step()
if (step + 1) % args.log_step == 0:
print(f'Epoch [{epoch + 1}/{args.epochs}], Step [{step + 1}/{steps}], '
f'Loss: {loss.item()}')
model.eval()
accurate = 0
num_elems = 0
for step, (x, targets) in enumerate(valid_dataloader):
with torch.no_grad():
x, targets = x.to(device), targets.to(device)
logits = model(x)
predictions = torch.argmax(logits, dim=1)
accurate_preds = (predictions == targets)
num_elems += accurate_preds.shape[0]
accurate += accurate_preds.sum().item()
eval_metric = accurate / num_elems
end_time = perf_counter()
print(f'Epoch [{epoch + 1}/{args.epochs}], Validation Accuracy: {eval_metric:.4f}, '
f'Elapsed Time: {end_time - start_time:.2f}\n')
print('Training complete!')
if __name__ == '__main__':
args = get_args_parser()
main(args)
이제 accelerate을 이용하여 코어 부분(초기화/학습)부분만 수정하자. 앞선 설명처럼 accelerate, accelerator.prepare, accelertor.backward(loss) 가 가장 중요하다.
import argparse
from pathlib import Path
from time import perf_counter
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision.datasets import ImageFolder
from torchvision.transforms import v2
from timm import create_model
from transformers import get_cosine_schedule_with_warmup
+ from accelerate import Accelerator
# 생략
...
def main(args: argparse.Namespace):
accelerator = Accelerator()
dataset_path: str | Path = args.dataset_path
if dataset_path.startswith('~'):
dataset_path = Path(dataset_path).expanduser()
else:
dataset_path = Path(dataset_path)
train_ds = ImageFolder(root=str(dataset_path / 'train'), transform=train_transforms)
valid_ds = ImageFolder(root=str(dataset_path / 'valid'), transform=valid_transforms)
train_dataloader = DataLoader(train_ds, batch_size=args.batch_size, num_workers=8, shuffle=True)
valid_dataloader = DataLoader(valid_ds, batch_size=args.batch_size, num_workers=8, shuffle=False)
model = create_model('resnet50d', pretrained=True, num_classes=len(train_ds.classes))
- # model = model.to(device)
for param in model.parameters():
param.requires_grad = False
for param in model.get_classifier().parameters():
param.requires_grad = True
optimizer = optim.AdamW(model.parameters(), lr=args.lr, weight_decay=args.weight_decay)
lr_scheduler = get_cosine_schedule_with_warmup(optimizer,
num_warmup_steps=5,
num_training_steps=len(train_dataloader) * args.epochs)
+ model, optimizer, train_dataloader, valid_dataloader, lr_scheduler = accelerator.prepare(
model, optimizer, train_dataloader, valid_dataloader, lr_scheduler)
steps = len(train_dataloader)
loss_fn = nn.CrossEntropyLoss()
for epoch in range(args.epochs):
message = f"Epoch [{epoch + 1}/{args.epochs}] start!"
formatted_message = f'{message:^30}'
print(f"{'=' * 20}{formatted_message}{'=' * 20}")
start_time = perf_counter()
model.train()
for step, (x, targets) in enumerate(train_dataloader):
- # x, targets = x.to(device), targets.to(device)
optimizer.zero_grad()
logits = model(x)
loss = loss_fn(logits, targets)
+ accelerator.backward(loss)
optimizer.step()
lr_scheduler.step()
if (step + 1) % args.log_step == 0:
print(f'Epoch [{epoch + 1}/{args.epochs}], Step [{step + 1}/{steps}], '
f'Loss: {loss.item()}')
model.eval()
accurate = 0
num_elems = 0
for step, (x, targets) in enumerate(valid_dataloader):
with torch.no_grad():
- # x, targets = x.to(device), targets.to(device)
logits = model(x)
predictions = torch.argmax(logits, dim=1)
accurate_preds = (predictions == targets)
num_elems += accurate_preds.shape[0]
accurate += accurate_preds.sum().item()
eval_metric = accurate / num_elems
end_time = perf_counter()
print(f'Epoch [{epoch + 1}/{args.epochs}], Validation Accuracy: {eval_metric:.4f}, '
f'Elapsed Time: {end_time - start_time:.2f}\n')
print('Training complete!')
if __name__ == '__main__':
args = get_args_parser()
main(args)
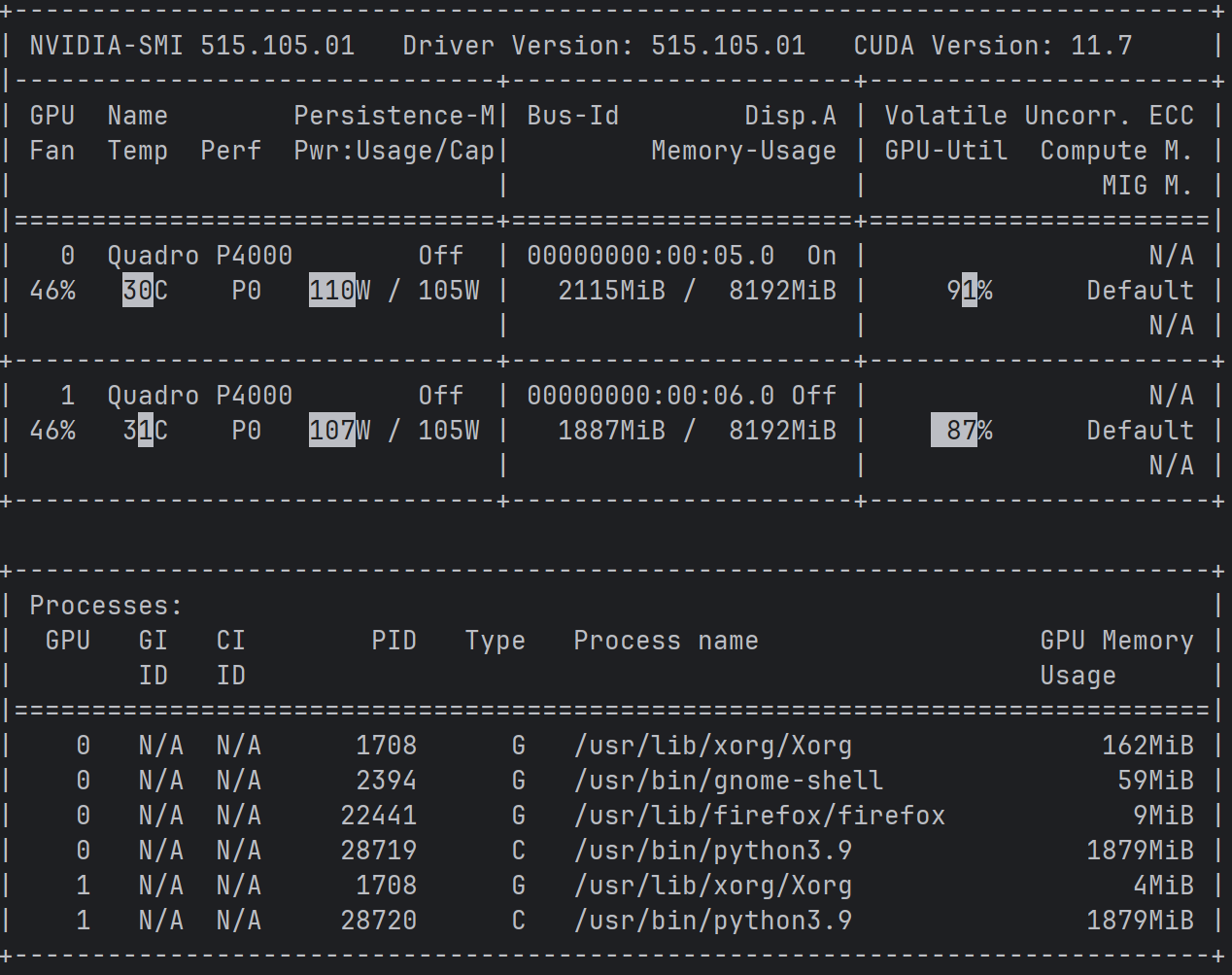
그리고 앞선 언급처럼 accelerate launch script.py로 분산학습을 실행하자.
보이듯이 두개의 GPU가 다 작동하는 것을 확인 할 수 있다.
결과는 다음과 같이 출력이 된다.
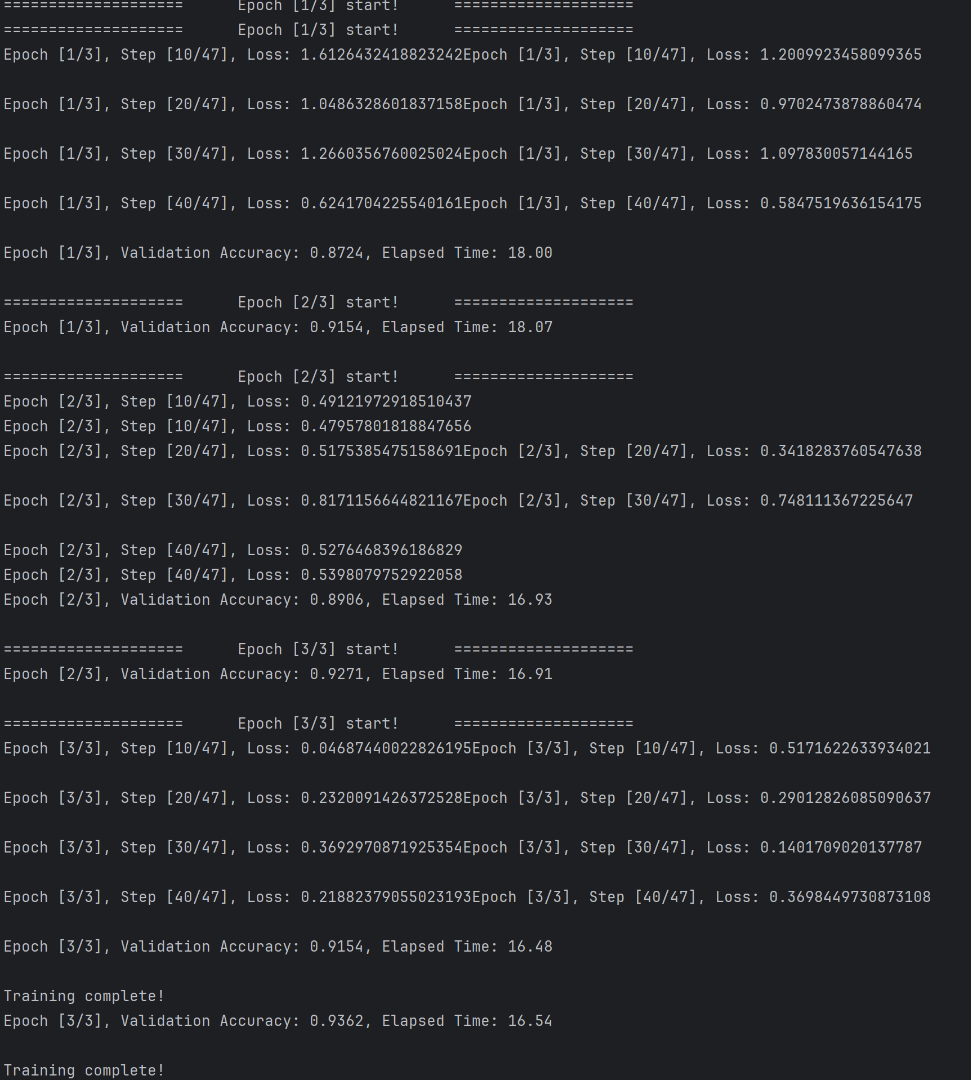
출력된 특징은 다음과 같다.
- 같은 유형이 두번씩 출력
- train_loader 의 길이는 절반으로 감소, 한 에폭당 학습 속도도 약 잘반으로 감소
각 특징에 대해서 하나씩 알아보자.
출력(같은 유형이 두번씩 출력)
DDP와 같은 분산 학습은 일반적으로 GPU 개수만큼의 프로세스를 만들어 동시성을 구현한다.
이로써 이전 DP의 단일 프로세스 다중 쓰레드의 GIL 문제를 해결한다.
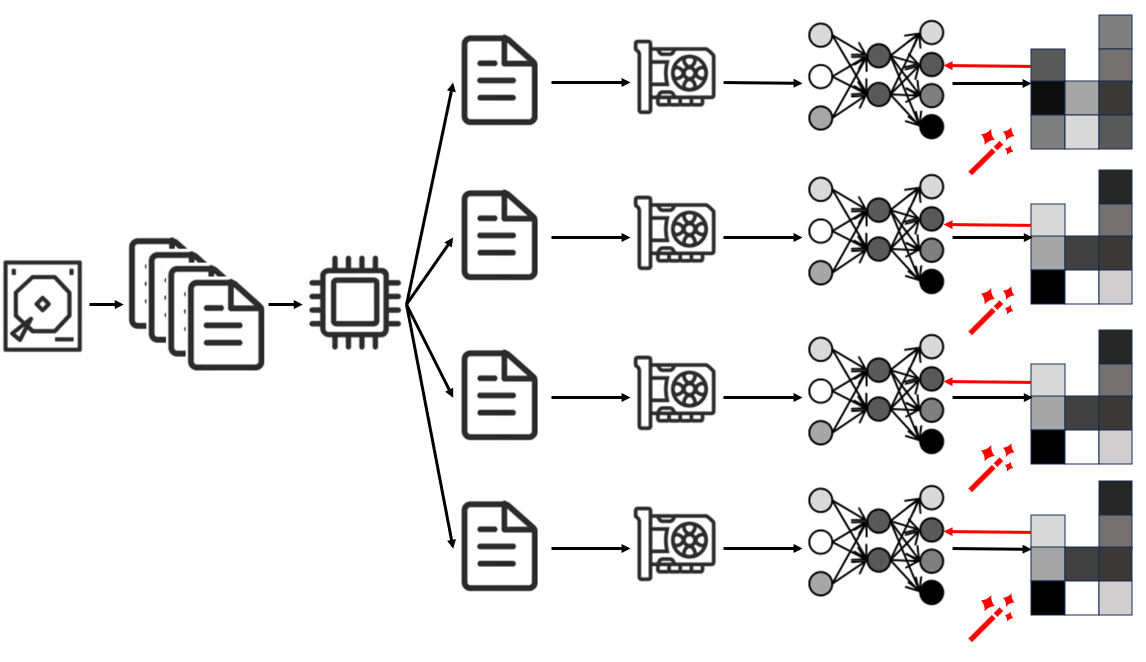
하지만 이로써 여러 프로세스가 동시에 실행이 되어 프로세스 수 만큼의 중복된 print가 출력된다.
값을 자세히 보면 각 로스의 다르다, 그 이유는 프로세스마다 각각 다른 데이터를 분산받아 처리하기에 모델 웨이트가 같더라도 데이터가 다르기 때문이다.
이러한 gradient 불일치는 Ring-AllReduce 방법으로 GPU의 tensor들을 동기화 후 모델을 업데이트한다.
일반적으로 우리는 하나의 출력하면 충분하다, 그리고 보통 메인 프로세스에서 로깅/출력 작업을 진행한다.
이를 위해서는 accelerate는 다음과 같이 명시적인 method 호출하는 방식으로 이를 실현 할 수 있다.
if accelerator.is_main_procss:
print(...)
# or
accelerator.print(...)첫번째는 보이듯이 메인프로세스일때만 if문 내용을 실행하며 여기서 print을 출력하면 된다.
더 나아가 accelerator.print로 각 서버마다 하나의 문구만 출력하게한다.
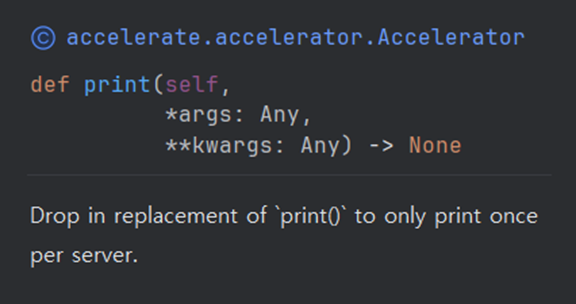
이제 앞선 예제의 모든 출력을 accelerator.print로 치환해보자.
import argparse
from pathlib import Path
from time import perf_counter
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision.datasets import ImageFolder
import torchvision.transforms as T
from timm import create_model
from transformers import get_cosine_schedule_with_warmup
from accelerate import Accelerator
def get_args_parser() -> argparse.Namespace:
parser = argparse.ArgumentParser(description='Simple image classification using accelerate')
parser.add_argument('--lr', type=float, default=3e-2)
parser.add_argument('--batch_size', type=int, default=64)
parser.add_argument('--weight_decay', type=float, default=1e-3)
parser.add_argument('--epochs', type=int, default=3)
parser.add_argument('--log_step', type=int, default=10)
parser.add_argument('--dataset_path', type=str, default='~/MyData/OxfordIIITPetDataset/')
return parser.parse_args()
train_transforms = T.Compose([
T.Resize((224, 224)),
T.RandAugment(5, 7),
T.ToTensor()
])
valid_transforms = T.Compose([
T.Resize((224, 224)),
T.ToTensor()
])
def main(args: argparse.Namespace):
accelerator = Accelerator()
dataset_path: str | Path = args.dataset_path
if dataset_path.startswith('~'):
dataset_path = Path(dataset_path).expanduser()
else:
dataset_path = Path(dataset_path)
train_ds = ImageFolder(root=str(dataset_path / 'train'), transform=train_transforms)
valid_ds = ImageFolder(root=str(dataset_path / 'valid'), transform=valid_transforms)
train_dataloader = DataLoader(train_ds, batch_size=args.batch_size, num_workers=8, shuffle=True)
valid_dataloader = DataLoader(valid_ds, batch_size=args.batch_size, num_workers=8, shuffle=False)
model = create_model('resnet50d', pretrained=True, num_classes=len(train_ds.classes))
for param in model.parameters():
param.requires_grad = False
for param in model.get_classifier().parameters():
param.requires_grad = True
optimizer = optim.AdamW(model.parameters(), lr=args.lr, weight_decay=args.weight_decay)
lr_scheduler = get_cosine_schedule_with_warmup(optimizer,
num_warmup_steps=5,
num_training_steps=len(train_dataloader) * args.epochs)
model, optimizer, train_dataloader, valid_dataloader, lr_scheduler = accelerator.prepare(
model, optimizer, train_dataloader, valid_dataloader, lr_scheduler)
steps = len(train_dataloader)
loss_fn = nn.CrossEntropyLoss()
for epoch in range(args.epochs):
message = f"Epoch [{epoch + 1}/{args.epochs}] start!"
formatted_message = f'{message:^30}'
+ accelerator.print(f"{'=' * 20}{formatted_message}{'=' * 20}")
start_time = perf_counter()
model.train()
for step, (x, targets) in enumerate(train_dataloader):
# x, targets = x.to(device), targets.to(device)
optimizer.zero_grad()
logits = model(x)
loss = loss_fn(logits, targets)
accelerator.backward(loss)
optimizer.step()
lr_scheduler.step()
if (step + 1) % args.log_step == 0:
+ accelerator.print(f'Epoch [{epoch + 1}/{args.epochs}], Step [{step + 1}/{steps}], '
f'Loss: {loss.item()}')
model.eval()
accurate = 0
num_elems = 0
for step, (x, targets) in enumerate(valid_dataloader):
with torch.no_grad():
# x, targets = x.to(device), targets.to(device)
logits = model(x)
predictions = torch.argmax(logits, dim=1)
accurate_preds = (predictions == targets)
num_elems += accurate_preds.shape[0]
accurate += accurate_preds.sum().item()
eval_metric = accurate / num_elems
end_time = perf_counter()
+ accelerator.print(f'Epoch [{epoch + 1}/{args.epochs}], Validation Accuracy: {eval_metric:.4f}, '
f'Elapsed Time: {end_time - start_time:.2f}\n')
+ accelerator.print('Training complete!')
if __name__ == '__main__':
args = get_args_parser()
main(args)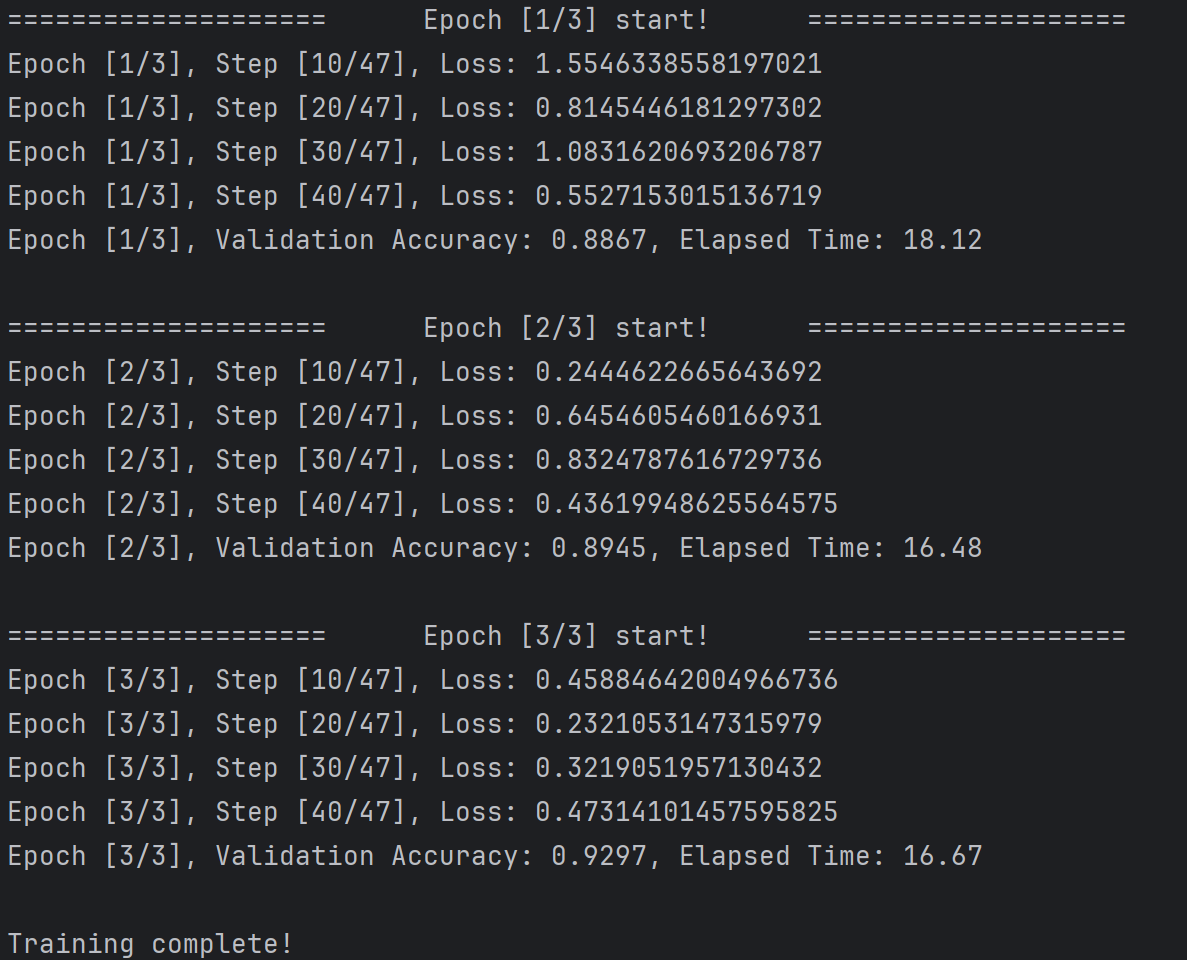
보이듯이 원래 예제와 같은 형식으로 출력된다.
따라서 프로세스마다의 상태를 확인 할 필요가 없다면 print대신 accelerator.print로 치환을 추천한다.
데이터 분산(train_loader 길이 감소)
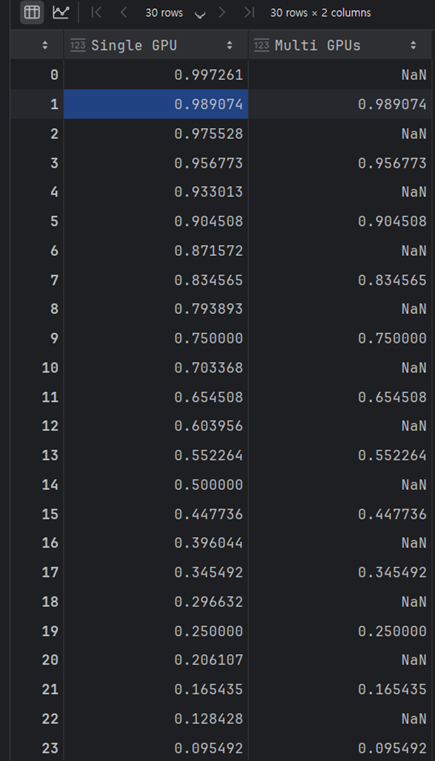
또한 single gpu 에서의 len(train_loader) 는 93이였으나, accelerate에서는 절반으로 감소 되었다.
그 이유는 앞서 DDP의 데이터 처리 원리 그림에서 쉽게 알 수 있다.
원래 데이터 로더의 값을을 중복되지 않게(실제로는 약간의 중복이 있다, 아래에서 설명) 균등하게 각 GPU에 분배하여 처리한다.
따라서 각 프로세스 로더의 길이는 97 --> 43이 된다.
이러한 데이터 분배, 모델 복제 부분이 accelerator.prepare에서 처리가 된다.
상위 코드에서 prepare 앞뒤는 print을 추가하여 이를 쉽게 확인이 가능하다.
...
train_dataloader = DataLoader(train_ds, batch_size=args.batch_size, num_workers=8, shuffle=True)
valid_dataloader = DataLoader(valid_ds, batch_size=args.batch_size, num_workers=8, shuffle=False)
+ print(f'Before prepare train_dataloader length: {len(train_dataloader)}')
model = create_model('resnet50d', pretrained=True, num_classes=len(train_ds.classes))
for param in model.parameters():
param.requires_grad = False
for param in model.get_classifier().parameters():
param.requires_grad = True
optimizer = optim.AdamW(model.parameters(), lr=args.lr, weight_decay=args.weight_decay)
lr_scheduler = get_cosine_schedule_with_warmup(optimizer,
num_warmup_steps=5,
num_training_steps=len(train_dataloader) * args.epochs)
model, optimizer, train_dataloader, valid_dataloader, lr_scheduler = accelerator.prepare(
model, optimizer, train_dataloader, valid_dataloader, lr_scheduler)
+ print(f'After prepare train_dataloader length: {len(train_dataloader)}')
...
그리고 해당 prepare에서 얻어진 train_dataloader에서 yield된 x, target의 속성을 다음 코드로 확인해보자.
...
for step, (x, targets) in enumerate(train_dataloader):
print(f'Epoch: [{epoch + 1}/{args.epochs}], Step: [{step + 1}/{len(train_dataloader)}]\n'
f'GPU ID: {accelerator.process_index}, x.shape: {x.shape}, targets.shape: {targets.shape}, \n'
f'x.device: {x.device}, targets.device: {targets.device}\n'
f'x.dtype: {x.dtype}, targets.dtype: {targets.dtype}')
optimizer.zero_grad()
logits = model(x)
...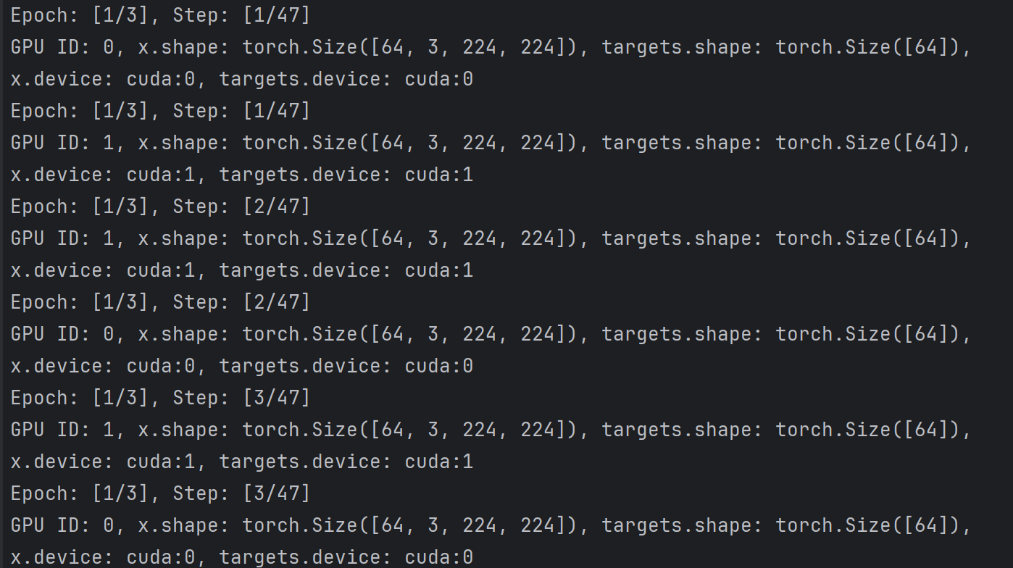
보이듯이 프로세스마다 각각 하나의 GPU을 사용하며 dataloader의 batch을 각 GPU에 할당되고 각 GPU마다있는 모델과 통화하여 loss을 계산한다.
위에서 우리는 accelerate가 간략하게 어떠한 원리로 학습되고 출력되는 알아봤다.
이제 학습외 다른 부가적인 부분에 대해서 소개를 진행하겠다.
Experiement Trackers
실제 학습에서는 우리는 이러한 나이브한 출력만으로 학습 정도를 쉽게 확인 할 수 없다.
따라서 일반적으로 이러한 loss, 평가 지표를 실험/step마다 시각화가 필요하다.
여기서 우리는 보통 tensorboard같은 라이브러리를 사용한다. accelerate는 아래와 같은 trackers을 지원한다.

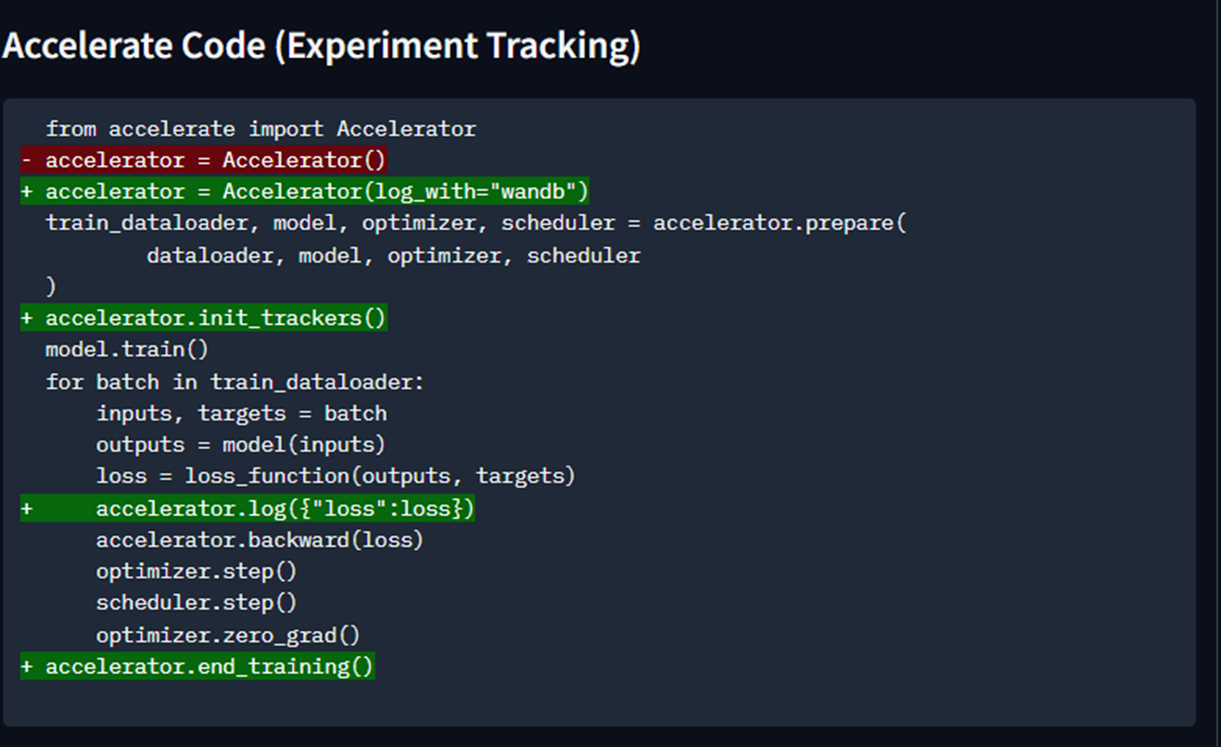
사용 방법도 쉽게 몇가지로 코드만 추가하면 쉽게 사용할 수 있다.
def main(args: argparse.Namespace):
+ accelerator = Accelerator(log_with=LoggerType.TENSORBOARD, project_dir='experiments')
+ # accelerator = Accelerator(log_with='tensorboard', project_dir='experiments') # you can use this instead
+ accelerator.init_trackers(project_name="test_01", ) # you also can use config= your_config to pass a custom config
...
model.train()
for step, (x, targets) in enumerate(train_dataloader):
optimizer.zero_grad()
logits = model(x)
loss = loss_fn(logits, targets)
accelerator.backward(loss)
optimizer.step()
lr_scheduler.step()
if (step + 1) % args.log_step == 0:
# print each GPU, each step loss for making sure which gpu's results are actually tracked
print(f'Epoch [{epoch + 1}/{args.epochs}], Step [{step + 1}/{steps}], '
f'GPU ID: {accelerator.process_index}, '
f'Loss: {loss.item()}')
+ accelerator.log({'Loss/train': loss.item()}, step= ((epoch + 1) * steps) + step)
...
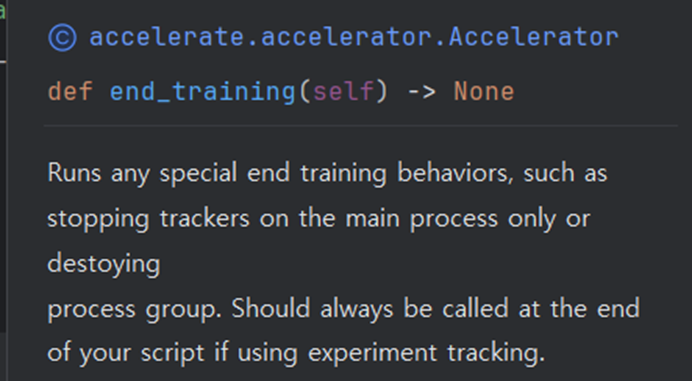
+ accelerator.end_training()
accelerator.print('Training complete!')
if __name__ == '__main__':
args = get_args_parser()
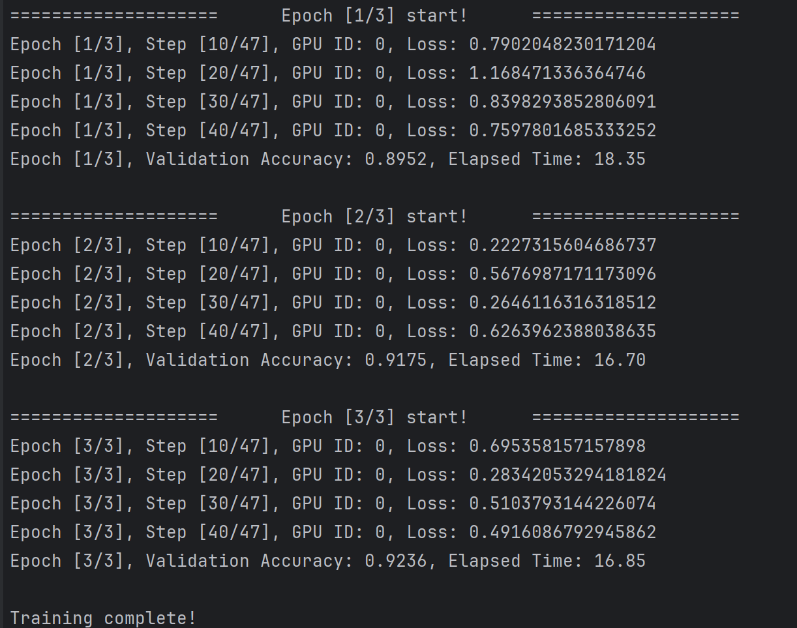
main(args)해당 코드의 결과도 같이 첨부하였다.
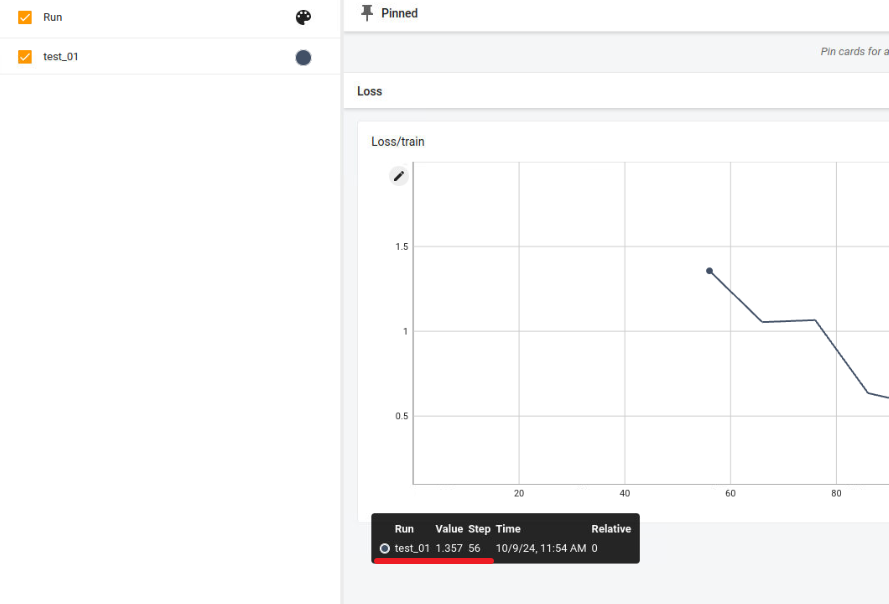

상위 첫번째 그림에서 보이듯이 tensorboard 에서 정확하게 추적이 되고 있다.
단 앞서 설명했듯이, 분산학습은 병렬적인 프로세스가 실행되고 있어 두개의 print가 출력되고 있다.
만약 torch의 SummaryWriter 및 writer.add_scalar("Loss/train", loss, step) 을 사용한다면 아마도(직접 실험은 해보지는 않았다...)
같은 step마다 프로세스별 각기 다른 값(loss)가 추적될 것이다.
따라서 이 방법을 사용하고 하나의 프로세스 결과만 추척하고 싶다면 if accelerator.is_main_process: 구문을 사용하여 해야할 것이다.
다시 acceleratr 방법으로 돌아가서 첫번째, 두번째 그림의 빨간 라인 부분에서 보이듯이 정확하게 메인프로세스의 값만 tensorboard에서 추적되고 있다.
이는 accelerator.log가 메인 프로세스의 결과만 추척을 하고 있는 것을 의미한다.
이는 accelerator.log의 docstring에서 확인 할 수 있다.
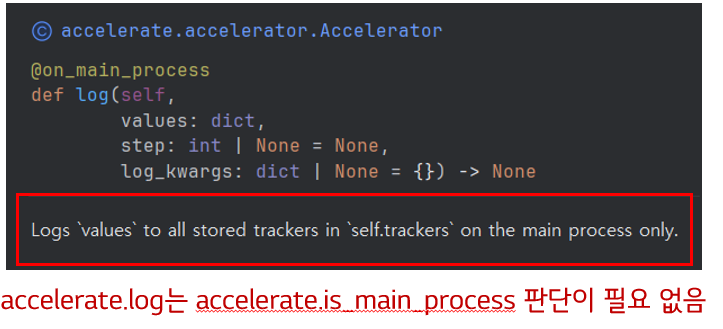
추적이 끝난다면 마지막에 명시적으로 accelerator.enc_training을 호출해야한다고 한다.
평가
우리는 학습중 주기적으로 모델을 평가하여 최적의 성능 지점을 찾을 필요가 있다.
평가를 하기위해 우리는 추가적인 작업이 필요하다.
수정이 필요한 단 두 줄로 매우 간단하다.
...
if (step + 1) % args.log_step == 0:
# change print to accelerator.print to prevent duplicate printings
accelerator.print(f'Epoch [{epoch + 1}/{args.epochs}], Step [{step + 1}/{steps}], '
f'GPU ID: {accelerator.process_index}, '
f'Loss: {loss.item()}')
accelerator.log({'Loss/train': loss.item()}, step= ((epoch + 1) * steps) + step)
model.eval()
accurate = 0
num_elems = 0
for step, (x, targets) in enumerate(valid_dataloader):
with torch.no_grad():
logits = model(x)
predictions = torch.argmax(logits, dim=1)
# Something fishy is going on…
+ predictions_gather, references = accelerator.gather_for_metrics((predictions, targets))
+ accurate_preds = predictions_gather == references
num_elems += accurate_preds.shape[0]
accurate += accurate_preds.sum().item()
eval_metric = accurate / num_elems
end_time = perf_counter()
accelerator.print(f'Epoch [{epoch + 1}/{args.epochs}], Validation Accuracy: {eval_metric:.4f}, '
f'Elapsed Time: {end_time - start_time:.2f}\n')
...출력된 결과은 다음과 같이 변화가 없다.
일단 코드에서 볼 수 있듯이 valid_dataloader도 prepare로 넘겨, 다중 GPUs에서 평가 또한 모든 자원을 효율적으로 사용할 수 있다.
반복해서 언급하지만, 분산처리 각 프로세스마다 상이한 데이터를 처리한다.
만약 predictions_gather, references = accelerator.gather_for_metrics((predictions, targets)) 가 없다면, 이전 코드는 각 프로세스에 전달된 상이한 데이터의 결과를 따로 집계한다.
따라서 단순히 print 혹은 accelerator.print을 사용할 경우 가각 계산된 프로세스 혹은 메인 프로세스의 결과를 출력한다.
이는 우리가 원하는 정확한 평가가 아니다.
그렇기에 평가 데이터셋 전체의 정확한 성능을 확인하기 위해서는 이러한 평가 결과를 모아야(gather)한다.
이를 하기 위해서는 프로세스간의 데이터를 교류(통신) 할 수 있는 기능을 코드에 반영해야하며,
이것이 바로 accelerator.gather_for_metrics 의 역활이다.
여기서 우리는 번외로 GPU 간 어떠한 통신이 있는지 간단하게 알아보자
NCCL
엔비디아 GPU는 NVLink 및 PCIE 를 사용해서 엔비디아 GPU간의 집합 연산(collective operation)을 수행할 수 있다.
이를 NCCL(NVIDIA Collective Communications Library)라고 한다.
즉 병렬 프로그래밍 간의 GPU 데이터를 통신/교류을 지원한다.
해당 라이브러리는 몇가지 연산을 제공해주며 중요 연산은 다음과 같다.
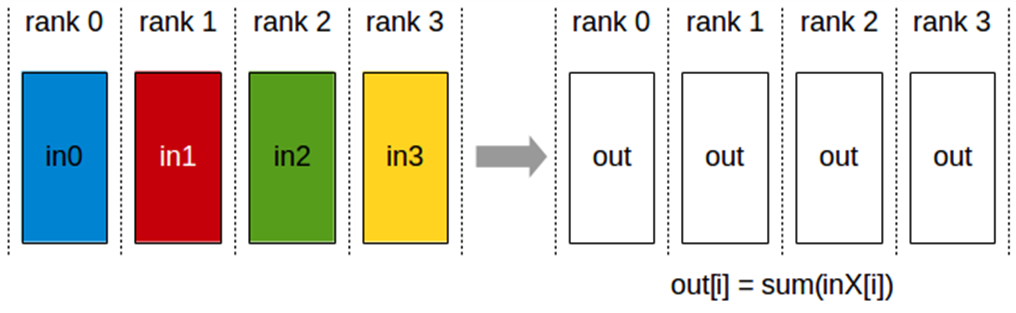
AllReduce
All-Reduce 연산은 각 랭크는 다른 모든 랭크의 입력값에 대한 축소(reduction)(sum, mean, ...) 결과를 받음.
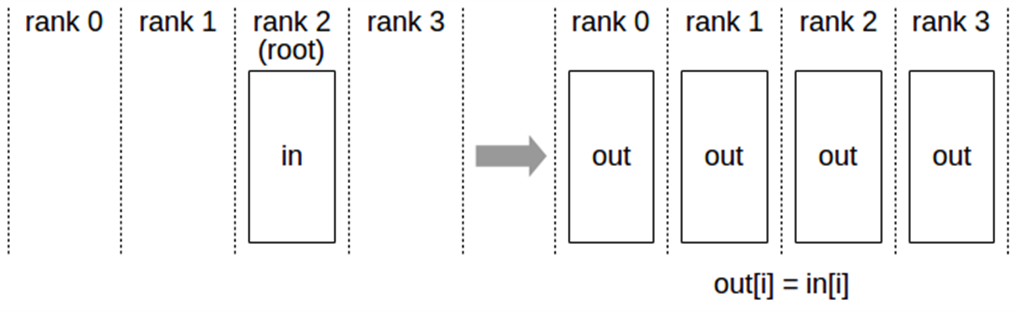
Broadcast
Broadcast 연산은 루트 랭크(root rank)에서 모든 랭크로 N개의 요소를 가진 버퍼를 복사하는 작업.
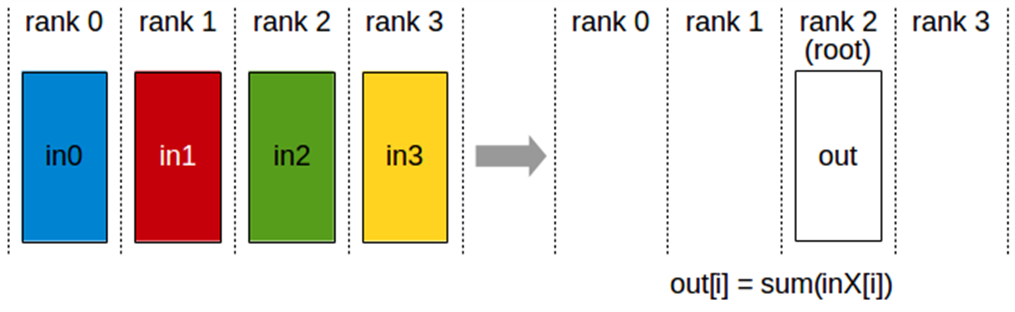
Reduce
Reduce 연산은 AllReduce와 동일한 연산을 수행하지만, 결과는 지정된 루트 랭크의 수신 버퍼에만 저장.
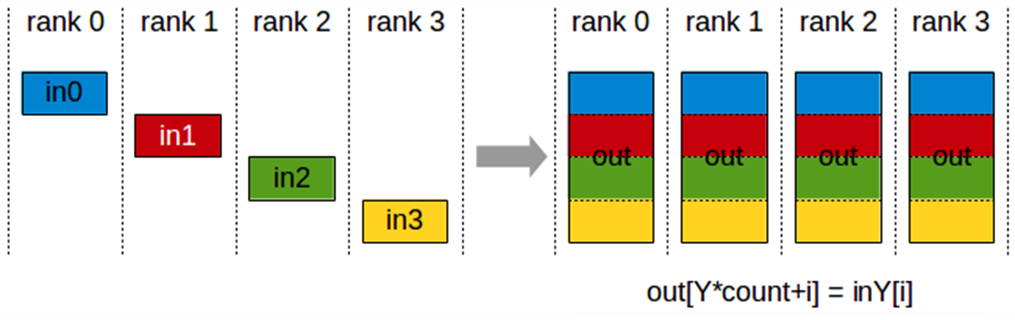
AllGather
AllGather 연산은 각 랭크에서 N개의 값을 수집하여 k*N 크기의 출력 버퍼로 모은 후, 그 결과를 모든 랭크에 분배하는 작업.
ReduceScatter
ReduceScatter 연산은 Reduce 연산과 동일한 작업을 수행하지만, 그 결과는 랭크 간에 균등한 크기의 블록으로 분산되며 각 랭크는 자신의 랭크 인덱스에 따라 데이터의 일부분을 받음
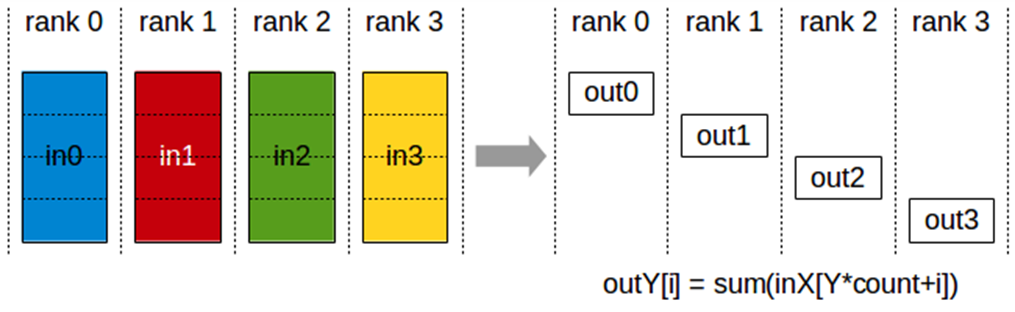
단 accelerate에서 이러한 연산을 직접적으로 사용은 흔지 않다.
아마도 평가에서만 AllGather 연산이 사용자가 직접적으로 사용할 것이다(물론 AllReduce도 간혹 호출하지만...).
그리고 실제로 accelerate에서는 두 타입의 AllGather 연산을 지원하는데, 각각 accelerator.gather 와 accelerator.gather_for_metric이다.
언듯 생각하기에는 gather만 사용하면 충분할꺼라 생각되지만 평가에서는 후자가 더 정확하고 간편하다.
그 이유는 accelerator.gather 와 accelerator.gather_for_metric 각각의 docstring을 read하면 알 수 있다.
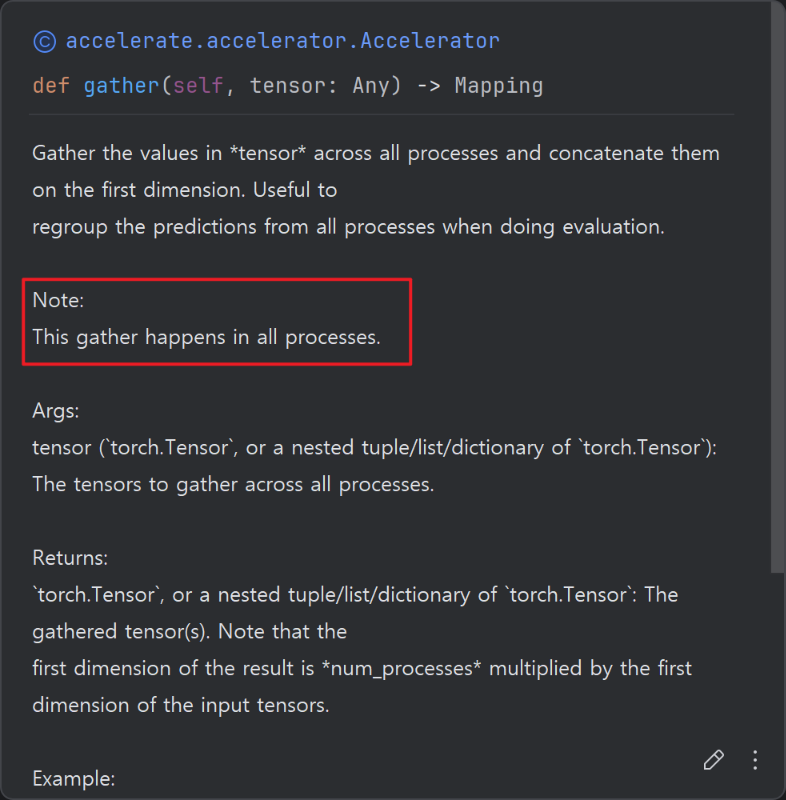
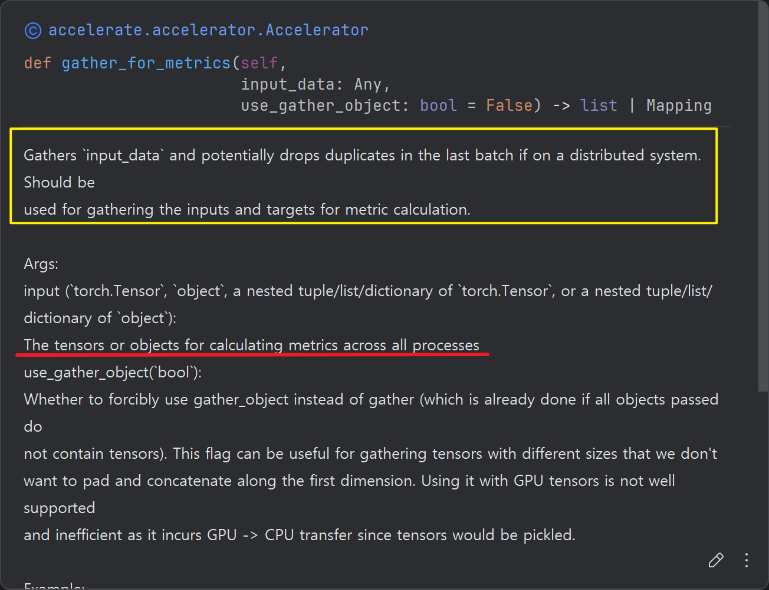
일단 이 둘 다 AllGather 연산이다. 이는 빨간 박스의 모든 프로세스(GPU)에서 계산된다고 명시되어있다.
그렇다면 이 둘의 차이점을 무엇일까? accelerator.gather_for_metric 그림 노란박스의 'potentially drops duplicates in the last batch' 이라는 문구에서 확인 할 수 있다.
즉 마지막 batch에서 중복된 값을 제거한다는 것이다. 하지만 이 또한 무엇을 의미할까?
이를 위해서는 네이티브 torch 와 accelerate의 dotaloader의 특징을 비교할 필요가 있다.
먼저 일반 torch dataloader는 batch 사이즈는 다음 그림에서 확인 할 수 있다.
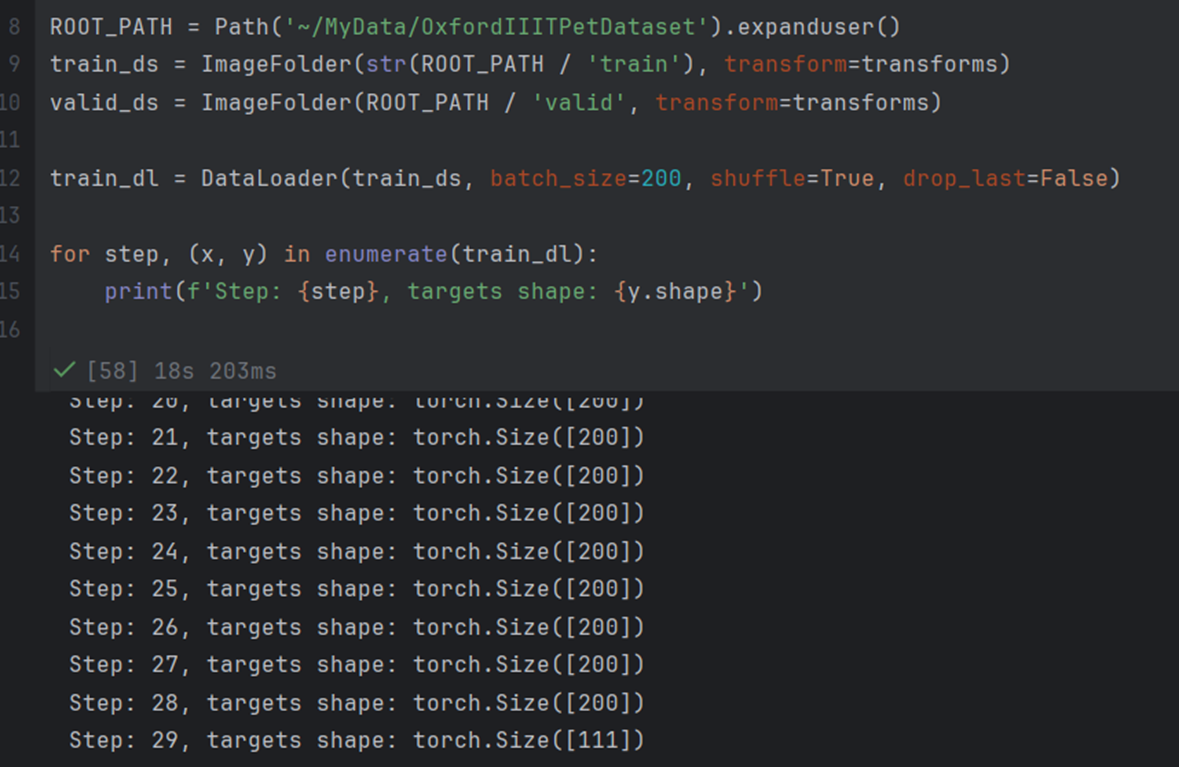
만약 drop_last=False이라면 마지막 batch에서 지정 size 보다 더미 데이터를 한데 뭉쳐 yield한다.
따라서 상위 그림에서 마지막 batch 사이즈(111)는 설정된 사이즈(200)보다 작다.
training 단계에서는 어차피 데이터를 여러번 반복적으로 학습 때문에, 보통 drop_last=True 하여 성가시고 사소한 부분 제거하고 학습을 한다.
반대로 평가에서는 평가 데이터 drop하지 않고 평가를 진행해야한다. 그렇기에 drop_last=False로 설정한다.
하지만 분산 학습에서는 이러한 경우 프로세스간 처리하는 step수가 일치하는 않는 문제(특정 프로세스의 step수는 나머지 대비 +1) 과 마지막 batch 사이즈가 기존과 상이한 문제들이 발생된다.
그래서 accelerate에소는 마지막 batch에서 프르세스 step수와 마지막 batch를 통일 시키기 위해, 기존 데이터 중복된 값을 가져와 마지막 batch을 보충함으로써 모든 프로세스가 같은 step과 batch size를 같게한다(drop_last=False 일지라도).
이를 다음 toy example에서 분산학습의 dataloader가 어떻게 작동하는지 확실하게 탐색해보자.(참조)
from accelerate import Accelerator
from torch.utils.data import DataLoader
accelerator = Accelerator()
dataloader = DataLoader(list(range(5)), shuffle=False, batch_size=2)
dataloader = accelerator.prepare(dataloader)
for batch in dataloader:
print(batch)
batch_true = accelerator.gather_for_metrics(batch)
print(f'gather_for_metric: {batch_true}')
print(f'simple gather: {accelerator.gather(batch)}')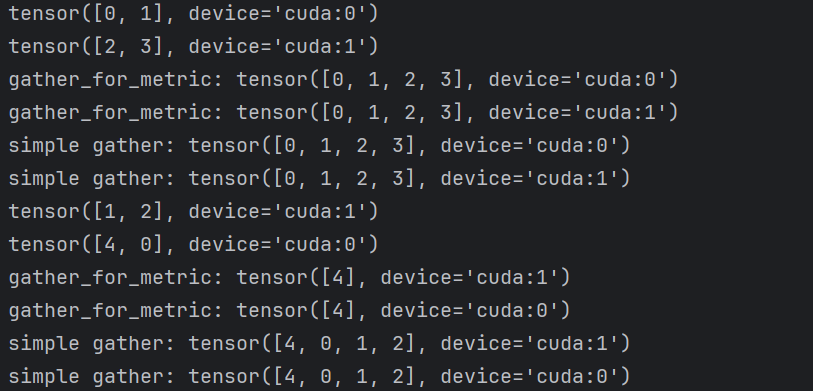
보이듯이 batch_size=2 이기에 batch 마다 맞는 데이터는 각 0-3 까지는 우리의 예상되 일치되게 분산된다.
따라서 accelerator.gather 와 accelerator.gather_for_metric 모두 각 프로세스마다 tensor([0, 1, 4, 3]을 gather한다.
문제는 4인데, accelerate의 기본 설정은 앞선 설명과 같이 이미 사용한 데이터를 가져와 batch size 및 step수 강제로 맞추어 준다.
따라서 실제로 yield된 값은 tensor([1, 4], device='cuda:1') 와 tensor([2, 0], device='cuda:0')이다.
accelerator.gather 를 중복 제거를 고려하지 않기에 마지막 batches에서 tensor([4, 0, 1, 2]) gather하기에 정확한 평가가 불가능하다.
반대로 accelerator.gather_for_metric 는 docstring에 설명처럼 중복을 고려하여 중복되지 않는 값 tensor([2]) 만 정확하게 gather하는 것이다.
이로 인해 우리는 아주 편리하게 평가 데이터 셋 결과를 정확하게 계산 할 수 있는 것이다.
아래 실제 예제에서 평가 부분에서 데이터의 형식을 출력하여 한번 확인해보자.
...
model.eval()
accurate = 0
num_elems = 0
for step, (x, targets) in enumerate(valid_dataloader):
with torch.no_grad():
logits = model(x)
predictions = torch.argmax(logits, dim=1)
predictions_gather, references = accelerator.gather_for_metrics((predictions, targets))
accurate_preds = predictions_gather == references
num_elems += accurate_preds.shape[0]
accurate += accurate_preds.sum().item()
+ print(f'Epoch [{epoch + 1}/{args.epochs}],Validation step [{step + 1}/{len(valid_dataloader)}], '
+ f'GPU ID: {accelerator.process_index}, \n'
+ f'prediction shape: {predictions.shape[0]}, references shape: {references.shape[0]}\n'
+ f'predictions_gather shape: {predictions_gather.shape[0]}, \n'
+ f'current accurate: {accurate}, current num_elems: {num_elems}\n'
+ f'==============================================================')
eval_metric = accurate / num_elems
end_time = perf_counter()
accelerator.print(f'Epoch [{epoch + 1}/{args.epochs}], Validation Accuracy: {eval_metric:.4f}, '
f'Elapsed Time: {end_time - start_time:.2f}\n')
...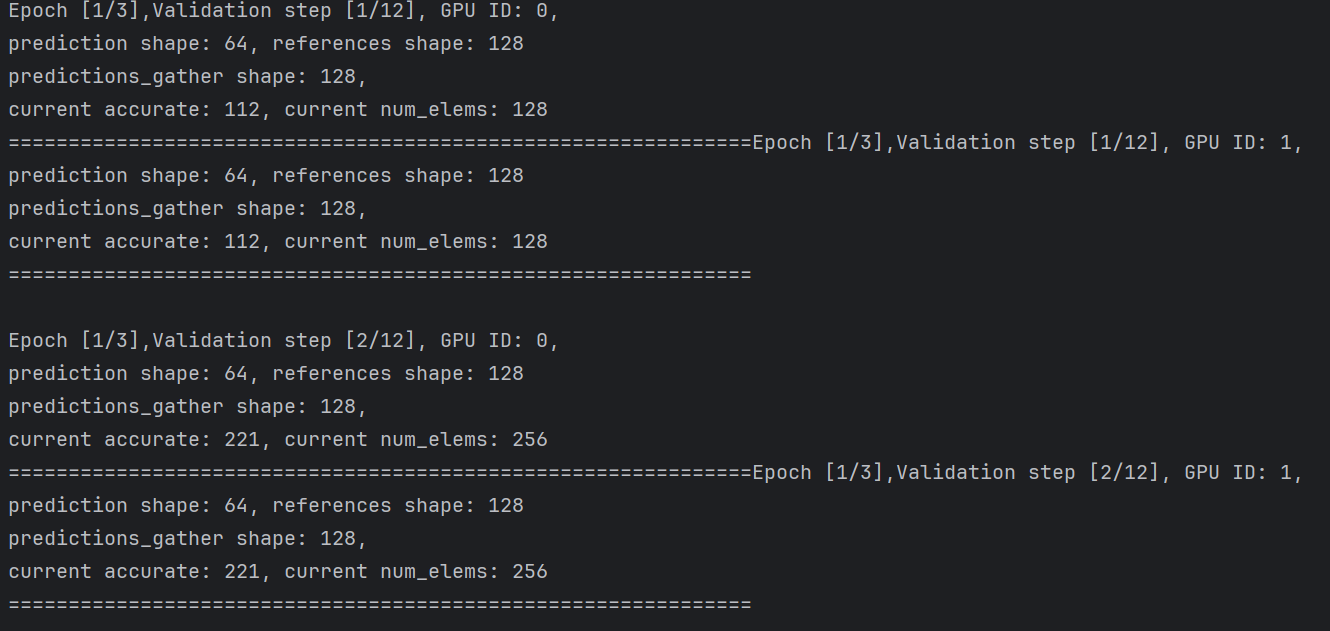
각 GPU마다 64의 사이즈의 데이터를 받고 gather_for_metric 후 gather된 결과 크기는 예상같은 64 * 2 = 128 이다.
그리고 이러한 결과는 모든 프로세스마다 별개의 accurate 와 num_elems 수집한다. 하지만 이 둘 프르세스의 객체들은 실제로 같은 value을 갖고 있다.
따라서 메인 프로세스의 accurate 와 num_elems 만으로 평가를 진행해도 된다.
이제 문제가 되는 마지막 batch로 넘어가보자.
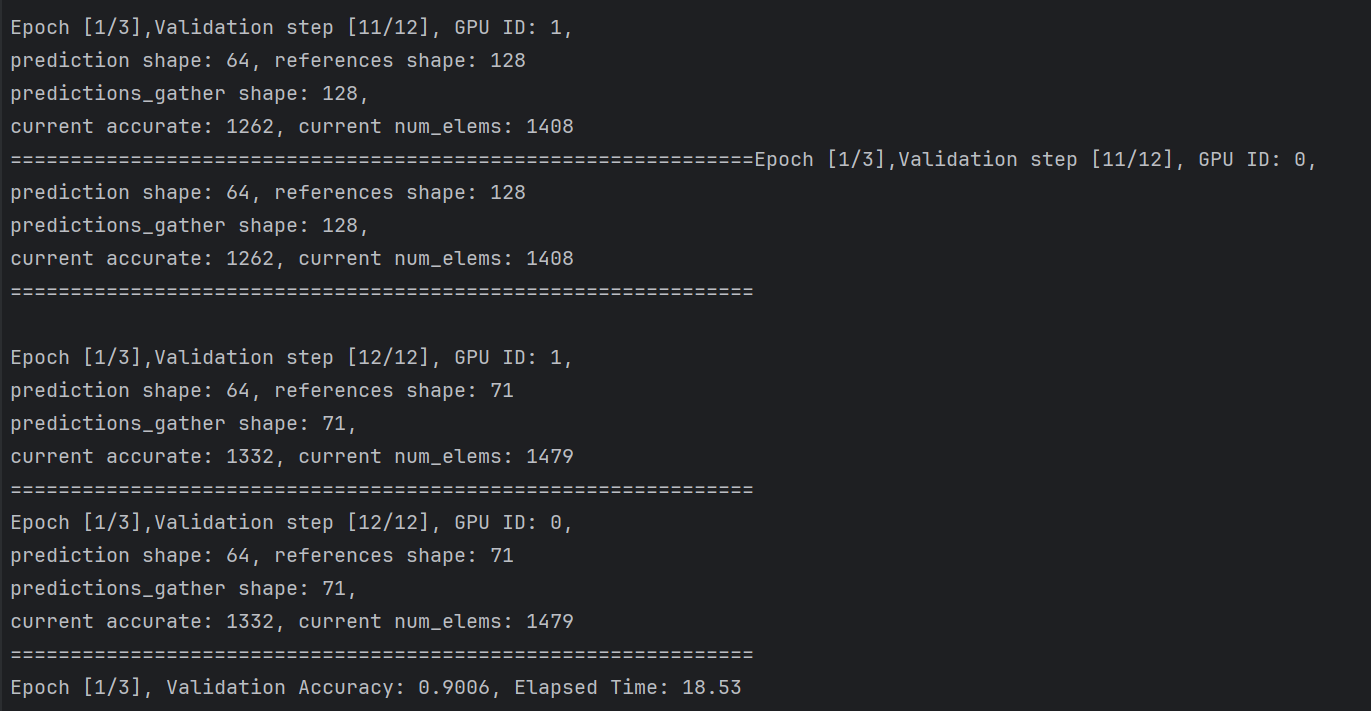
이제 마지막 batch에서 프로세스는 모드 중복을 포함한 64개의 사이즈 yield한다.
하지만 gather_for_metric 그중 실제 기존 데이터에 없는 element만 gather하여 references의 사이즈는 71이다.
이로써 정확한 평가가 가능해진다.
이제 마지막은 모델 저장/로드 부분을 살펴보자.
Save/Load
딥러닝은 알다시피 장기간 훈련이 필요로한다. 그래서 주기적으로 현재 상태(모델 weight, optimizer, RNG generator, GradScaler 및 lr_scheduler) 저장/로드가 필요하다.
accelerate에서도 이러한 점을 고려하여 accelerator.save_state 및 accelerator.load_state로 현재 분산 학습 상태로 쉽게 저장/로드 할 수 있다.
save_state
먼저 상태를 저장save_state을 확인해보자.
import argparse
from pathlib import Path
from time import perf_counter
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision.datasets import ImageFolder
import torchvision.transforms as T
from timm import create_model
from transformers import get_cosine_schedule_with_warmup
from accelerate import Accelerator
from accelerate.utils import LoggerType
def get_args_parser() -> argparse.Namespace:
parser = argparse.ArgumentParser(description='Simple image classification using accelerate')
parser.add_argument('--lr', type=float, default=3e-2)
parser.add_argument('--batch_size', type=int, default=64)
parser.add_argument('--weight_decay', type=float, default=1e-3)
parser.add_argument('--epochs', type=int, default=3)
parser.add_argument('--log_step', type=int, default=5) # step 5마다 체크
parser.add_argument('--dataset_path', type=str, default='~/MyData/OxfordIIITPetDataset/')
return parser.parse_args()
train_transforms = T.Compose([
T.Resize((224, 224)),
T.RandAugment(5, 7),
T.ToTensor()
])
valid_transforms = T.Compose([
T.Resize((224, 224)),
T.ToTensor()
])
def main(args: argparse.Namespace):
accelerator = Accelerator(log_with=LoggerType.TENSORBOARD, project_dir='experiments')
accelerator.init_trackers(project_name="test_02", )
dataset_path: str | Path = args.dataset_path
if dataset_path.startswith('~'):
dataset_path = Path(dataset_path).expanduser()
else:
dataset_path = Path(dataset_path)
train_ds = ImageFolder(root=str(dataset_path / 'train'), transform=train_transforms)
valid_ds = ImageFolder(root=str(dataset_path / 'valid'), transform=valid_transforms)
train_dataloader = DataLoader(train_ds, batch_size=args.batch_size, num_workers=8, shuffle=True)
valid_dataloader = DataLoader(valid_ds, batch_size=args.batch_size, num_workers=8, shuffle=False)
model = create_model('resnet50d', pretrained=True, num_classes=len(train_ds.classes))
for param in model.parameters():
param.requires_grad = False
for param in model.get_classifier().parameters():
param.requires_grad = True
optimizer = optim.AdamW(model.parameters(), lr=args.lr, weight_decay=args.weight_decay)
lr_scheduler = get_cosine_schedule_with_warmup(optimizer,
num_warmup_steps=10,
num_training_steps=len(train_dataloader) * args.epochs)
model, optimizer, train_dataloader, valid_dataloader, lr_scheduler = accelerator.prepare(
model, optimizer, train_dataloader, valid_dataloader, lr_scheduler)
steps = len(train_dataloader)
loss_fn = nn.CrossEntropyLoss()
for epoch in range(args.epochs):
message = f"Epoch [{epoch + 1}/{args.epochs}] start!"
formatted_message = f'{message:^30}'
accelerator.print(f"{'=' * 20}{formatted_message}{'=' * 20}")
start_time = perf_counter()
model.train()
for step, (x, targets) in enumerate(train_dataloader):
optimizer.zero_grad()
logits = model(x)
loss = loss_fn(logits, targets)
accelerator.backward(loss)
optimizer.step()
lr_scheduler.step()
if (step + 1) % args.log_step == 0:
# change print to accelerator.print to prevent duplicate printings
accelerator.print(f'Epoch [{epoch + 1}/{args.epochs}], Step [{step + 1}/{steps}], '
f'GPU ID: {accelerator.process_index}, '
+ f'Loss: {loss.item()}, lr: {optimizer.param_groups[0]["lr"]}') # also print lr
accelerator.log({'Loss/train': loss.item()}, step= (epoch * steps) + step)
# get current learning rate for checking whether save_state works
accelerator.log({'lr': optimizer.param_groups[0]['lr']}, step= (epoch * steps) + step)
model.eval()
accurate = 0
num_elems = 0
for step, (x, targets) in enumerate(valid_dataloader):
with torch.no_grad():
logits = model(x)
predictions = torch.argmax(logits, dim=1)
predictions_gather, references = accelerator.gather_for_metrics((predictions, targets))
accurate_preds = predictions_gather == references
num_elems += accurate_preds.shape[0]
accurate += accurate_preds.sum().item()
eval_metric = accurate / num_elems
end_time = perf_counter()
accelerator.print(f'Epoch [{epoch + 1}/{args.epochs}], Validation Accuracy: {eval_metric:.4f}, '
f'Elapsed Time: {end_time - start_time:.2f}\n')
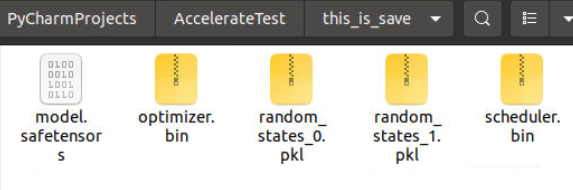
+ accelerator.save_state('this_is_save')
+ break # Stop training after 1 epoch for testing save_state
accelerator.end_training()
accelerator.print('Training complete!')
if __name__ == '__main__':
args = get_args_parser()
main(args)
해당 코드는 1 epoch만 학습하고 상태를 저장한다. 아래 그림에서 보이듯이 지정된 폴더(this_is_test)에 state가 저장된 것을 확인 할수 있다.
load_state
그리고 다음처럼 prepare 후, load_state을 호출하여 상태 로드후 학습을 재개한다.
...
optimizer = optim.AdamW(model.parameters(), lr=args.lr, weight_decay=args.weight_decay)
lr_scheduler = get_cosine_schedule_with_warmup(optimizer,
num_warmup_steps=10,
num_training_steps=len(train_dataloader) * args.epochs)
model, optimizer, train_dataloader, valid_dataloader, lr_scheduler = accelerator.prepare(
model, optimizer, train_dataloader, valid_dataloader, lr_scheduler)
# Load state from previous training
+ accelerator.load_state('this_is_save')
steps = len(train_dataloader)
loss_fn = nn.CrossEntropyLoss()
for epoch in range(1, args.epochs): # starting from 1
...
# delete below
# accelerator.save_state('this_is_save')
# break # Stop training after 1 epoch for testing save_state
accelerator.end_training()
accelerator.print('Training complete!')
...
출력 결과는 다음 같으며 재개된 부분의 손실 값 및 learning late가 이전 상태에서 재게된다는 것을 볼 수 있다.
그리고 전체 lr_scheduler 의 상태로 우리가 원하는 대로 resume 된것을 아래 그래프로 확인 할 수 있다.
lr_scheduler
번외로 분산 학습의 lr_scheduler.step()에 대해서 알아보자.
lr_scheduler는 학습 단계마다 학습률(learning rate)을 조정하는 함수로, 모델의 성능을 개선하기 위해 필수적인 요소이다.
일반적으로, 학습 과정에서 지정된 step마다 학습률이 변하며, 학습이 진행됨에 따라 점차 줄어드는 방식이 많이 사용된다.
분산 학습의 dataloader의 length은 일반 대비 만큼 줄어든다.
예를 들어, 2개의 GPU로 분산 학습을 한다면, 각 GPU는 원래 데이터 양의 절반만 처리한다.
따라서 lr_scheduler.step() 호출 횟수도 그만큼 줄어들어, lr_scheduler이 우리가 의도한대로 count하지 못한다고 생각 할 수 있다.
하지만 accelerate.prepare는 이러한 것도 고려하여 lr_scheduler을 프로세스 수 만큼 알아서 스케줄링한다.
accelerate는 분산 학습에서의 lr_scheduler.step() 호출 횟수를 GPU 수에 맞게 조정하여, 각 GPU에서 처리되는 데이터 양은 줄어들지만, 전체 학습에서는 원래 의도한 학습률 조정이 일어나도록 보장한다.
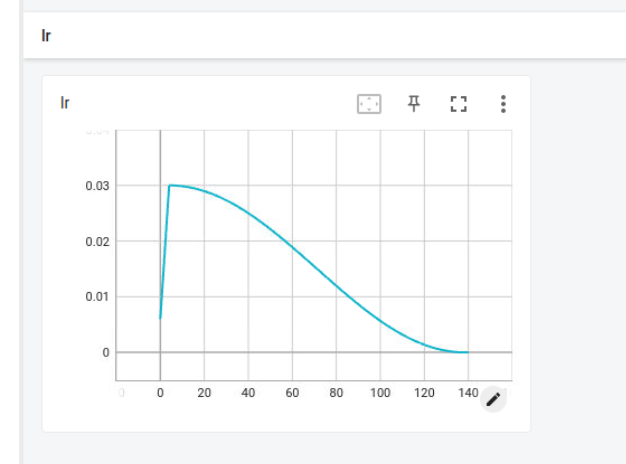
아래 그림은 일반 학습 및 분산 학습(gpus=2)일 때의 step별 lr의 변화율이다.
보이듯이 step 수가 절반이 된 것을 다시 확인 할 수 있다. 즉 step 호출 빈도가 기존 대비 1/2이 된것이다.
하지만, accelerate는 이를 고려하여 각 GPU에서 처리되는 batch마다 step 변화율이 더 큰 폭으로 조정한다.
즉, 2배 더 빠르게 학습률이 감소하게 하여 전체적으로 동일한 학습률 감소가 이루어지도록 함.
즉, lr_distributed = lr_normal[::2].
save_model
모델을 배포할 때는 학습에 사용된 분산 학습 관련 정보 없이 원래 모델의 weight만 저장하는 것이 필요하다.
accelerate에서는 이를 가능하기 위해 추가적으로 accelerator.save_model method를 제공한다.
이때 accelerator.unwrap_model을 호출하여 모델을 원래 형태로 복원해주어야 한다.
아래 코드와 그 결과를 보면 쉽게 이해가 될 것이다.
from timm import create_model
from accelerate import Accelerator
def main():
accelerator = Accelerator()
model = create_model('resnet50', pretrained=True)
model = accelerator.prepare(model)
# wait_for_everyone Will stop the execution of the current process until every other process has reached that point (so this does
# nothing when the script is only run in one process). Useful to do before saving a model.
accelerator.wait_for_everyone()
accelerator.print(f'Model type before unwrap: {type(model)}, model name: {model.__class__.__name__}')
unwrap_model = accelerator.unwrap_model(model)
accelerator.print(f'Model type after unwrap: {type(unwrap_model)}, model name: {unwrap_model.__class__.__name__}')
accelerator.save_model(unwrap_model, "model.pth")
if __name__ == '__main__':
main()

위 코드에서 unwrap_model을 호출하기 전의 모델은 DistributedDataParallel 객체로, 분산 학습에 사용되는 객체이다.
하지만 이렇게 분산 학습 관련 객체를 그대로 저장하면, 이후 로드할 때 원래 형태의 모델로 로드하는 것이 불가능하다.
따라서 unwrap_model 호출하여 모델을 원래 형태로 복원한 후 저장한다.
이 과정을 거치지 않고 모델을 저장하면, 예를 들어 transformers 라이브러리의 model.save_pretrained() 같은 메서드 사용이 불가능하다.
마무리
마지막으로 소개한 accelerate의 몇가지 중요 포인트로 정리하였다.
-
accelerate사용 장점- 코드의 최소한의 변경으로 single GPU 코드에서 Multi-GPUs 분산 학습 환경으로 확장이 가능하다.
torchrun대신accelerate launch명령을 사용하여 분산 학습을 간편하게 실행할 수 있다.
-
분산 학습 설정
- 분산 학습에서 여러 프로세스가 동시에 실행되므로,
accelerator.print를 사용하여 중복 출력 방지 가능. - 데이터는 각 프로세스에 균등하게 분배되어,
train_dataloader의 길이가 GPU 수에 맞게 감소한다.
- 분산 학습에서 여러 프로세스가 동시에 실행되므로,
-
추적 및 로깅
tensorboard등의 실험 추적기를Accelerate와 쉽게 통합할 수 있다.accelerator.log()를 사용하면 메인 프로세스에서만 로그 기록을 남길 수 있다.
-
모델 평가
- 분산 학습에서는
accelerator.gather_for_metrics()로 중복된 평가 데이터를 처리하여 전체 데이터셋에 대한 정확한 평가가 가능하다.
- 분산 학습에서는
-
NCCL 통신 연산
- 분산 학습에서 AllGather와 같은 NCCL 연산이 데이터 동기화와 통신을 담당한다.
-
모델 저장 및 불러오기
- 학습 상태는
accelerator.save_state()와accelerator.load_state()로 저장하고 복원 가능하다. - 학습 중 모델 저장 시
accelerator.unwrap_model()을 사용하여DistributedDataParallel객체를 원래 모델 형태로 변환해야 한다.
- 학습 상태는
-
분산 학습의 학습 스케줄러 처리
- 분산 학습에서는 GPU 수에 맞춰
lr_scheduler의 호출 빈도가 자동 조정되어 원래 학습 속도와 일관성을 유지한다.
- 분산 학습에서는 GPU 수에 맞춰
-
모델 저장 방식
- 학습이 완료된 모델은
accelerator.save_model()로 저장할 수 있으며, 분산 학습을 위해 wrapping된 모델은 저장하기 전에 반드시unwrap_model해야 한다.
- 학습이 완료된 모델은
