힙 개념
데이터에서 최대값과 최소값을 빠르게 찾기 위해 고안된 완전 이진 트리(Complete Binary Tree)
완전 이진트리란 부모 노드를 기준으로 자식 노드가 최대 2개인 노드이고 데이터가 들어올 때 왼쪽부
터 차례로 채운다.
힙을 사용하는 이유
배열에 데이터를 넣고 최대값과 최소값을 찾으려면 O(n)이 걸림
이에 반해, 힙에 데이터를 넣고, 최대값과 최소값을 찾으면, O(log n)이 걸림
우선순위 큐와 같이 최대값 또는 최소값을 빠르게 찾아야 하는 자료구조 및 알고리즘 구현 등에 활용됨
힙의 종류와 구조
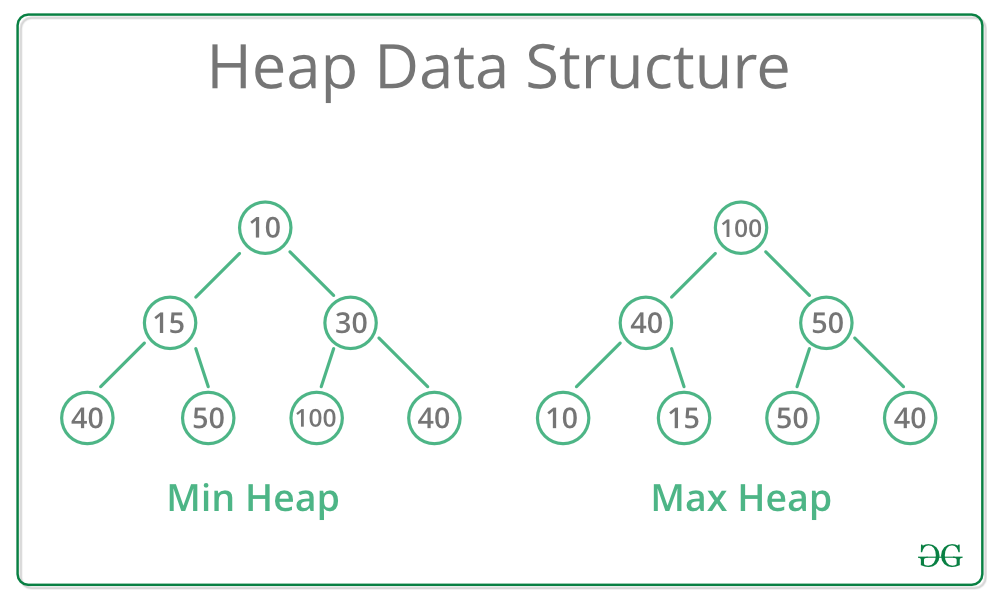
최소힙과 최대힙이 있다.
최대힙의 경우 특정 노드에서 부모노드는 자식노드보다 크거나 같다. 루트 노드가 가장 크다.
최소힙의 경우 특정 노드에서 부모노드는 자식노드보다 작거나 같다. 루트 노드가 가장 작다.
이진 탐색트리와 힙 간의 공통점과 차이점
공통점
이진 탐색트리와 힙은 모두 이진트리이다.
차이점
힙
힙(최대 힙)의 경우 부모 노드가 자식 노드보다 크거나 같다. 자식 노드 간 순서가 중요하지 않다.
이진 탐색 트리
특정 노드에서의 왼쪽 자식 < 부모 노드 < 특정 노드의 오른쪽 자식 노드
이진 탐색 트리와 힙의 쓰임새
이진 탐색 트리는 탐색을 위한 자료 구조
힙은 최대값 또는 최소값을 찾기 위한 자료 구조
힙 동작
데이터 삽입
1. 완전 이진 트리 형태에서 데이터를 가장 왼쪽 위치부터 차례대로 채운다.
2. 그 후 부모노드와 값을 비교하면서 최대힙의 경우 들어온 데이터가 부모노드보다 작을 때 까지
계속 자리를 변경해준다.
데이터 삭제
1. 힙 자료구조에서 데이터 삭제 시 부모노드에 있는 데이터를 삭제한다.
2. 데이터를 삭제한 후 가장 마지막에 넣은 데이터를 루트 노드에 넣는다.
3. 최대 힙의 경우 루트노드와 자식노드를 비교하면서 자식노드 중 큰 값으로 데이터를 서로 바꾼다.
해당 작업은 자식 노드가 없을 때 또는 자식 노드 모두 부모 노드보다 작을 때까지 반복한다.
힙 (데이터 삽입)
None 이라는 데이터를 초기화 메서드에서 append 하는 이유
우선적으로 힙이라는 클래스에서 인스턴스를 생성했을 때 완전 이진 트리형태에서 루트 노드를 만들어야 한다.
첫번째 데이터는 index가 1인 형태로 관리되면 좋기 때문에 만든 리스트에다가 None이라는 데이터를 넣을 것
이다. 이 의미가 무슨 의미이냐면 특정 노드에서 부모노드의 index에 접근 할 때 또는 자식 노드의 index에 접
근할 때 유용하다는 의미이다.
예를 들어 루트노드의 index가 1이면 자식 노드가 2개일 경우 각각 2, 3의 index를 갖는다. 이 때 부모노드
입장에서 자식 노드는 곱하기 2(왼쪽 노드) 또는 곱하기 2 + 1(오른쪽 노드)에 접근할 수 있다.
반대로 자식노드 입장에서 현재 노드의 index 에서 2로 나눈 몫이 부모 노드의 index가 된다. 정리하면 특정
노드에서 위 아래로 손쉽게 idx에 접근하기 위해서 None이라는 데이터를 처음에 넣고 idx를 1인 부분부터 데이터
를 넣는 것이다.
이와 같은 사항을 반영한 것이 아리 초기화 메서드에서 리스트 선언 후 None라는 데이터를 append하는 이유이다.
class Heap:
def __init__(self, data):
self.heap = list()
self.heap.append(None)
self.heap.append(data)
데이터 삽입 시 인덱스를 활용해서 (완전 이진 트리 형태 및 힙구조)를 지키면서 데이터를 삽입하는 코드
위에서 None 이라는 데이터를 넣는 이유에 대해서 알아보았다. 이제는 데이터를 삽입할 때 왜 삽입하려는 데이터의
index가 중요한지 알아본 후 삽입한 후 힙 자료구조에 맞는 자리를 찾아가기 위한 코드 작성을 해볼 것이다.
python에는 append라는 함수가 있기 때문에 리스트 맨 마지막 인덱스에 특정 데이터를 삽입한다. 그래서 최대힙
이든 최소힙이든 데이터를 넣었을 때 서로의 위치를 변경할 일이 없는 값을 차례대로 배열에 삽입했을 때에는 배열의
인덱스와 완전이진트리에서 인덱스가 서로 동일하다.
데이터를 삽입했을 때 그냥 배열의 index와 힙의 자료구조를 따르는 완전 이진트리 형태의 index가 달라지는 것은
넣는 데이터 간의 위치 이동이 일어났을 때 두 자료구조는 다른 형태를 취한다는 것이다. 그랬을 떄 사용자가 만든
heap에 데이터를
class Heap:
def __init__(self, data):
self.heap = list()
self.heap.append(None)
self.heap.append(data)
def can_move_up(self, cur_idx):
if cur_idx == 1:
return False
parent_idx = cur_idx // 2
if self.heap[parent_idx] < self.heap[cur_idx]:
return True
return False
def insert(self, data):
if len(self.heap) == 0:
self.heap = list()
self.heap.append(None)
self.heap.append(data)
self.heap.append(data)
cur_idx = len(self.heap) - 1
while self.can_move_up(cur_idx):
parent_idx = cur_idx // 2
self.heap[parent_idx], self.heap[cur_idx] = self.heap[cur_idx], self.heap[parent_idx]
cur_idx = parent_idx
데이터 삭제 시 코드
데이터를 삭제 하는 함수는 pop() 함수이다. 자료구조 힙에서 데이터를 삭제 할 때에는 루트노드에 들어있는 값을
리턴하고 해당 공간에 우측 최 하단 노드를 위로 올리고 힙 자료구조에 맞게 다시 재구성한다. 이 부분이 데이터를
삭제하는 주요 로직이다.
can_move_down() 이라는 함수는 루트 노드에 최 하단에 있는 노드에 들어있는 값을 넣었을 떄 해당 값이
자식 노드와 바꿀 수 있는 경우 True를 반환하고 그렇지 않을 경우 False를 반환한다. 해당 함수에서 눈여겨서
보아야 할 포인트는 현재 노드에 자식노드의 유무를 파악하는 로직이다. 자식 유무를 파악하는 로직과 자식이
있을 때 왼쪽 자식이 있을때와 자식이 모두 있을 때의 로직을 작성하는 부분이 해당 로직의 핵심이라고 할 수 있다.
왼쪽 자식이 없는 경우 -> 특정 노드에서 왼쪽 자식 노드가 없는 경우를 판별하는 식은 완전 이진 트리의 형태 중
완전 이진트리 중 최하단 마지막 노드의 자식이 없는 경우를 생각했을 때 그 떄 특정 노드의 인덱스 * 2한 값이
전체 노드 개수보다 큰 경우를 생각하면 된다.
왼쪽 자식 노드만 있는 경우 -> 특정 노드의 인덱스 * 2 + 1 한 값은 최대 노드의 개수를 벗어남과 동시에 특정
노드의 값이 왼쪽 자식의 노드보다 작을 때 True를 리턴하는 쪽으로 로직을 작성해 주면 된다.
마지막으로 자식 노드가 모두 있을 때 자식 노드 중 큰 값이 특정 노드보다 클 경우에 한해서 자식 노드 간 비교 해
준 뒤 그중 큰 자식 노드를 특정 노드와 값을 변경해준다.
def can_move_down(self, cur_idx):
l_child_idx = cur_idx * 2
r_child_idx = cur_idx * 2 + 1
if l_child_idx > len(self.heap):
return False
elif r_child_idx > len(self.heap):
if self.heap[cur_idx] < self.heap[l_child_idx]:
return True
return False
else:
max_value = max(self.heap[l_child_idx], self.heap[r_child_idx])
if max_value < self.heap[cur_idx]:
return False
else:
return True
def pop(self):
if len(self.heap) <= 1:
return None
return_data = self.heap[1]
self.heap[1] = self.heap[-1]
del self.heap[-1]
cur_idx = 1
while self.can_move_down(cur_idx):
l_child_idx = cur_idx * 2
r_child_idx = cur_idx * 2 + 1
if r_child_idx > len(self.heap):
if self.heap[cur_idx] < self.heap[l_child_idx]:
self.heap[cur_idx], self.heap[l_child_idx] = self.heap[l_child_idx] = self.heap[cur_idx]
cur_idx = l_child_idx
else:
max_value = max(self.heap[l_child_idx], self.heap[r_child_idx])
if max_value > self.heap[cur_idx] and self.heap[l_child_idx] >= self.heap[r_child_idx]:
self.heap[cur_idx], self.heap[l_child_idx] = self.heap[l_child_idx] = self.heap[cur_idx]
elif max_value > self.heap[cur_idx] and self.heap[r_child_idx] >= self.heap[l_child_idx]:
self.heap[cur_idx], self.heap[r_child_idx] = self.heap[r_child_idx] = self.heap[cur_idx]
return return_data
힙 전체 코드
class Heap:
def __init__(self, data):
self.heap = list()
self.heap.append(None)
self.heap.append(data)
def can_move_up(self, cur_idx):
if cur_idx == 1:
return False
parent_idx = cur_idx // 2
if self.heap[parent_idx] < self.heap[cur_idx]:
return True
return False
def insert(self, data):
if len(self.heap) == 0:
self.heap = list()
self.heap.append(None)
self.heap.append(data)
self.heap.append(data)
cur_idx = len(self.heap) - 1
while self.can_move_up(cur_idx):
parent_idx = cur_idx // 2
self.heap[parent_idx], self.heap[cur_idx] = self.heap[cur_idx], self.heap[parent_idx]
cur_idx = parent_idx
def can_move_down(self, cur_idx):
if len(self.heap) == 1:
return False
l_c_idx = cur_idx * 2
r_c_idx = cur_idx * 2 + 1
if l_c_idx > len(self.heap):
return False
elif r_c_idx > len(self.heap):
if self.heap[l_c_idx] <= self.heap[cur_idx]:
return False
else:
return True
else:
max_value = max(self.heap[l_c_idx], self.heap[r_c_idx])
if max_value <= self.heap[cur_idx]:
return False
else:
return True
def pop(self):
if len(self.heap) == 1:
return False
return_data = self.heap[1]
self.heap[1] = self.heap[-1]
del self.heap[-1]
cur_idx = 1
while self.can_move_down(cur_idx):
l_c_idx = cur_idx * 2
r_c_idx = cur_idx * 2 + 1
if self.heap[l_c_idx] <= self.heap[cur_idx]:
self.heap[l_c_idx], self.heap[cur_idx] = self.heap[cur_idx], self.heap[l_c_idx]
else:
if self.heap[l_c_idx] >= self.heap[r_c_idx]:
self.heap[l_c_idx], self.heap[cur_idx] = self.heap[cur_idx], self.heap[l_c_idx]
else:
self.heap[r_c_idx], self.heap[cur_idx] = self.heap[cur_idx], self.heap[r_c_idx]
return return_data
def print_heap(self):
for data in self.heap:
print(data, end=' ')
