시뮬레이션 정의
애플리케이션 구현이 거의 끝났으니 부하 테스트를 진행해보려고 한다.
목표로 하는 성능은 실제 학교에서 발생할 수 있는 트래픽을 기준으로 할 것이다.
우리 학교에서는 한 학기 수강신청을 네 차례 나눠서 하며, 학과나 학년에 따라 일정이 달라진다.
이는 강의 여석을 공평하게 조정하기 위함이기도 하겠지만 트래픽의 분산 효과도 얻을 수 있다.
학교에서 제공하는 입시 결과 자료를 기준으로 계산해보면, 한 학년 당 2천명 가까이의 학생이 존재하고, 재학생만 따져보면 8천명에서 1만명 정도 될 것이다.
이를 4로 나누면 수강신청 한 번에 2000명 이상의 학생이 참여한다고 볼 수 있다.
이때 신청하는 학점은 15~21점이므로, 한 학생당 6개의 강의를 신청한다고 생각하면, 한 순간에 12,000개의 요청이 발생한다고 정리된다.
문제는 강의를 연달아 신청한다는 점이다. 따라서 응답 시간이 최대한 빨라야 사용자 경험을 증대시킬 수 있고, 아무리 느려도 1초를 넘기면 안 될 것이다.
시뮬레이션은 다음과 같이 정의한다:
- 2000명의 사용자가 6번 연달아 강의 수강을 신청한다.
- 사용자는 4학년 1학기 수강생으로, 3년간(총 6학기)의 수강 이력을 갖고 있다.
- 강의는 1200개 존재하고, 여석은 각각 10석이다. (결국 모든 학생을 수용할 수 있다)
- 강의 중 인기 강의가 10개 존재한다. 50%의 사용자는 인기 강의 중 하나를 무조건 골라 신청할 것이다.
- 수강 조건을 어겼거나 여석이 없으면 신청에 실패하며
400 Bad Request를 응답받는다.
시뮬레이션 구현
초기화 스크립트:
def main():
# 모든 데이터 삭제
request('POST', '/admin/clear')
# 임의의 학생 생성
studentIds = []
for i in range(NUM_STUDENTS):
student = request('POST', '/students', body={ 'studentNumber': random_student_number()})
studentIds.append(student['id'])
# 임의의 강의 생성
lectureIds = []
for i in range(NUM_LECTURES):
level = i
lecture = request('POST', '/lectures', body={
'lectureNumber': random_lecture_number(level=level),
'term': '2021-1',
'name': f"test-{str(i)}",
'subject': f"test-{str(i)}",
'level': level,
'credit': 3,
'capacity': 10,
'schedules': []})
lectureIds.append(lecture['id'])
# 인기 강의 선택
popLectureIds = lectureIds[:NUM_POPULAR_LECTURES]
# CSV 파일 생성 (학생이 어떤 강의를 수강할 것인지 결정)
with open('registrations.csv', 'w', newline='') as csvfile:
spamwriter = csv.writer(csvfile, delimiter=',', quotechar='|', quoting=csv.QUOTE_MINIMAL)
spamwriter.writerow(["studentId", "lectureIds"]) # Header
for studentId in studentIds:
registLectureIds = []
# 50% 확률로 인기 강의 중 하나를 골라 수강
if random.random() < 0.5:
registLectureIds.append(random.choice(popLectureIds))
# 정해진 수만큼 강의 수강
while len(registLectureIds) < NUM_LECTURES_PER_STUDENT:
registLectureIds.append(random.choice(lectureIds))
spamwriter.writerow([str(studentId), ' '.join(str(id) for id in registLectureIds)])gatling 시뮬레이션 스크립트:
class RegisterSimulation extends Simulation {
// 설정 파일 로드
val simConfig: Config = ConfigFactory.load("simulation.conf")
val httpProtocol = http
.baseUrl(simConfig.getString("baseUrl"))
// 수강신청 시나리오 정의
val scn = scenario("RegisterSimulation")
.feed(csv("registrations.csv").queue)
.foreach(session => session("lectureIds").as[String].split(" ").toSeq, "lectureId") {
exec(http("register lectures")
.post("/students/${studentId}/register")
.body(StringBody("""{"lectureId":${lectureId}}""")).asJson
.check(status.is(200)))
}
// 시나리오 실행
setUp(
scn.inject(atOnceUsers(simConfig.getInt("register.numUsers")))
).protocols(httpProtocol)
}첫 실행 결과

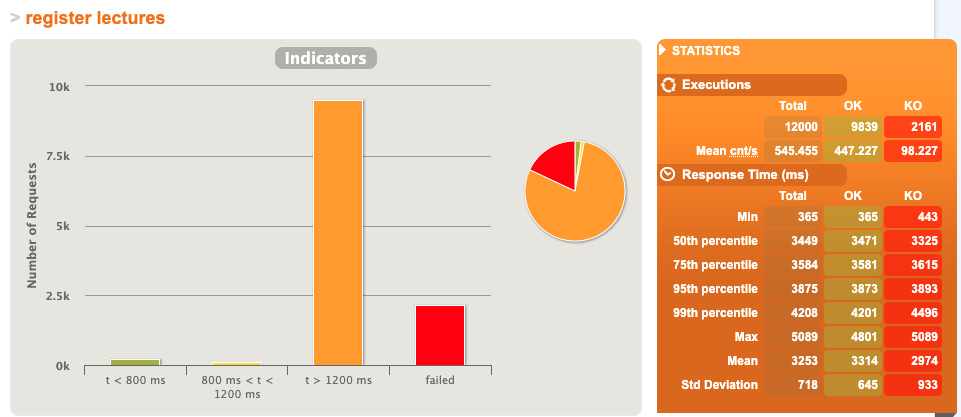
평균 응답 시간이 4초라니! 사용자가 기다리기엔 너무 길다.
그러나 부하 테스트 시 한 가지 고려해야 하는 점이 있는데, JVM의 클래스 지연 로딩과 인터프리팅 과정이다.
JVM의 Interpreter는 바이트 코드를 JIT 방식으로 그때그때 컴파일한다. 그리고 자주 실행되는 코드가 있다면 그 부분을 컴파일해두고 다음에 재활용함으로써 속도를 개선한다.
JVM의 Class Loader는 필요한 클래스를 그때그때 로드하여 메모리에 적재한다.
따라서 이 두 가지 작업을 미리 수행해두면 애플리케이션의 실행 속도를 높일 수 있다. 이를 JVM Warm-up이라고 한다.
JVM Warm-up
가장 단순한 Warm-up 방법은 미리 시뮬레이션을 한 번 실행해두는 것이다. 필요한 클래스가 로드되고, 사용하는 코드가 컴파일되기 때문이다.
그러나 기본 설정이 적용된 JVM에서는 한 번의 시뮬레이션 만으로는 코드가 제대로 달궈지지 않았다. 그 이유는 특정 한계점 이상 코드가 실행되어야 컴파일되기 때문이다.
-XX:CompileThreshold=invocations
Sets the number of interpreted method invocations before compilation. By default, in the server JVM, the JIT compiler performs 10,000 interpreted method invocations to gather information for efficient compilation.
...
This option is ignored when tiered compilation is enabled.
-XX:CompileThreshold=invocations 인자로 그 한계점을 설정할 수 있다.
기본값이 무려 10,000인데, 12000개의 요청 중 실패하는 요청이 약 2000개이므로, 실패와 관련된 코드가 달궈지려면 시뮬레이션을 5번이나 미리 실행해야 한다. 따라서 이를 1,000 정도로 설정해주면 적절할 것 같다.
그러나 이 인자를 사용하기 위해서는 -XX:-TieredCompilation 인자를 적용해야 한다고 적혀있다.
Tiered Compilation은 Java 8부터 기본값으로 활성화된 기능인데, 자주 실행될 수록 컴파일 수준을 높이는 방식으로, 컴파일 시간과 최적화 정도 간 트레이드오프의 절충안을 제공한다.
JVM에는 클라이언트(-client)와 서버(-server) 방식의 JIT 컴파일러가 있다. 클라이언트 컴파일러는 컴파일이 빠르지만 실행 성능이 떨어지고, 서버 컴파일러는 컴파일이 느리지만 실행 성능이 좋다. Tiered Compilation은 컴파일러의 계층화를 통해 두 마리 토끼를 다 잡는 셈이다.
이 기능은 JVM Warm-up에 방해가 되고, 컴파일 한계점을 설정할 수 없도록 하므로 꺼주어야 한다.
결론적으로, 다음 인자로 서버 애플리케이션을 실행한다:
-XX:-TieredCompilation -XX:CompileThreshold=1000
그 다음 실제 측정 전에 미리 시뮬레이션을 한 번 돌려두면, 필요한 클래스가 모두 로드되고 사용할 코드가 충분히 달궈진 상황에서 실험을 진행할 수 있게 된다.
JVM Warmup 후 실행 결과

평균 응답 시간 4239ms → 3253ms
1000ms 정도 개선되었지만, 여전히 만족하기는 어려운 결과다.
학생 입장에서 6개의 강의를 수강해야 하는데, 버튼 한 번 눌렀을 때마다 3초씩이나 기다려야 한다면 정말 답답할 것 같다.
문제가 정의되었으니 앞으로 이걸 해결해보고자 한다.
