데이터베이스
여러 사람이 공유하여 사용할 목적으로 체계화한 데이터의 집합
- 파일 시스템에 비해 중복이 적음 (참조와 정규화)
- 일관성과 무결성을 유지함 (트랜잭션)
- 데이터를 빠르게 접근할 수 있도록 함 (인덱스)
- 사용자 접근 권한으로 시스템을 보호함 (권한 관리)
무결성(Integrity)
데이터의 정확성과 일관성을 유지하고 보증하는 것
- 개체 무결성(Entity integrity): 모든 테이블이 중복되지 않는 기본 키(PK)를 가져야 함
- 참조 무결성(Referential integrity): 외래 키 값은 NULL이거나 특정 테이블의 존재하는 기본 키를 참조해야 함
- 범위 무결성(Domain integrity): 모든 열(Column)이 값의 범위나 형식을 제한해야 함
키(Unique key)
튜플을 유일하게 식별하는 애트리뷰트
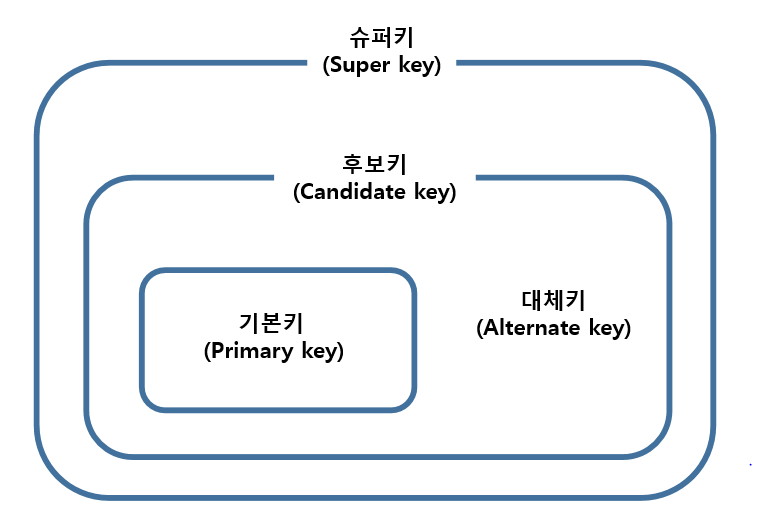
슈퍼 키에 속하는 종류:
- 슈퍼 키(Superkey): 유일성을 가지는 모든 컬럼 집합
- e.g. { 학번 }, { 전화번호 }, { 학번, 이름 }
- 후보 키(Candidate key): 슈퍼 키 중 최소성을 갖는 키 집합
- 키에서 속성을 하나라도 제거하면 유일하지 않음 (최소의 속성으로 구성돼야 함!)
- e.g. { 학번 }, { 전화번호 }
- 기본 키(Primary key): 후보 키 중 유일하고 NULL이 아닌 주요 키
- e.g. { 학번 }
- 대리 키(Alternate key): 후보 키 중 기본 키가 아닌 것들
- e.g. { 전화번호 }
그 외의 특별한 종류:
- 복합 키(Composite key): 두 개 이상의 컬럼으로 이루어진 키
- e.g. { 학번, 이름 }
- 외래 키(Foreign Key): 특정 테이블의 레코드를 참조하는 키
- e.g. { 학과 ID }
- 자연 키(Natural key): 비즈니스 도메인에 자연적으로 존재하는 키
- e.g. { 주민등록번호 }
- 대체 키(Surrogate key): 비즈니스 도메인에 존재하지 않고 인공적으로 만들어진 키
- e.g.
AUTO_INCREMENT, UUID
- e.g.
조인(Join)
한 컬럼 값을 기준으로 여러 테이블을 합치는 SQL문
크로스 조인(Cross join)
각 테이블의 행들을 카티션 곱(Cartesian Product)하여 조회
- 기준으로 하는 컬럼이 없음
- A 테이블에 행 N개, B 테이블에 행 M개가 있으면 N*M개의 행을 조회함 (엄청 많다!)
- e.g.
select * from A, B;
내부 조인(Inner Join)
컬럼 값을 기준으로 짝지어질 수 있는 행들만 조회
- Equi-Join: 동등 연산자를 기반으로 짝을 지음
- e.g.
select * from A inner join B on A.a = B.b; - e.g.
select * from A, B where A.a = B.b;
- e.g.
- Natural join: 테이블들의 같은 속성들을 대상으로 짝을 지음
- e.g.
select * from A natural join B;
- e.g.
외부 조인(Outer join)
특정 테이블을 기준으로 모든 행을 다른 테이블의 행과 짝지어 조회하되, 짝지어질 수 없다면 NULL을 채워 조회
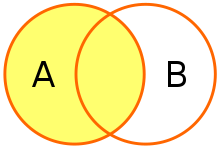
- Left outer join: 왼쪽 테이블을 기준으로 오른쪽 테이블을 매칭
- 왼쪽 테이블의 행은 모두 조회되며, 그 중 오른쪽 테이블과 매칭되지 않는 행에는 NULL이 짝지어짐
- e.g.
select * from A left outer join B on A.a = B.b;
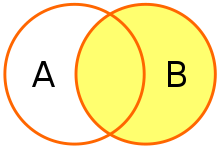
- Right Outer Join: 오른쪽 테이블을 기준으로 왼쪽 테이블을 매칭
- 오른쪽 테이블의 행은 모두 조회되며, 그 중 왼쪽 테이블과 매칭되지 않는 행에는 NULL이 짝지어짐
- e.g.
select * from A right outer join B on A.a = B.b;
- Full Outer Join: Left Outer Join과 Right Outer Join의 합집합
- e.g.
select * from A full outer join B on A.a = B.b;
- e.g.
셀프 조인(Self join)
테이블 자기 자신과의 조인
- e.g.
select * from A A1 inner join A A2 on A1.a = A2.a;
정규화(Normalization)
중복 최소화로 이상 현상 방지
이상 현상(Anomaly)
- 갱신 이상(Update anomaly): 새 데이터 삽입 시 불필요한 데이터(e.g.
NULL)도 함께 삽입해야 하는 문제 - 삽입 이상(Insertion anomaly): 중복에 의해 데이터 불일치가 발생할 수 있는 문제
- 삭제 이상(Deletion anomaly): 특정 컬럼을 삭제하느라 행 전체를 잃게되는 문제
함수 종속성(Functional dependency)
릴레이션 내 하나의 키가 다른 키의 값을 결정한다는 제약의 일종
- X→Y: Y는 X에 대해 함수 종속, 정보 Y는 정보 X에 의해 결정됨
- e.g. { 생일 } → { 나이 }: 나이 값은 생일 값에 의해 결정됨
1NF
if the domain of each attribute contains only atomic (indivisible) values, and the value of each attribute contains only a single value from that domain
모든 애트리뷰트가 원자 값을 가져야 함
- e.g. 애트리뷰트의 값이
A,B,CA,B,C로 나눠 애트리뷰트가 원자 값을 갖도록 해야 함
2NF
It does not have any non-prime attribute that is functionally dependent on any proper subset of any candidate key of the relation.
1NF이면서, 부분적인 후보 키 → non-prime 애트리뷰트 함수 종속성이 없어야 함
- prime attribute: 후보 키에 속하는 애트리뷰트
- e.g. { 학번, 과목 } → 성적, { 학번 → 학부 }
학부는 후보 키{ 학번, 과목 }전체가 아닌{ 학번 }에 의존하고 있음- 두 함수 종속성을 분리해야 함 (릴레이션 분리!)
- 복합 키 형태의 후보 키가 없거나, 모든 애트리뷰트가 후보 키에 속하면 자동으로 만족함
3NF
all non-prime attributes depend only on the candidate keys and do not have a transitive dependency on another key.
2NF이면서, 모든 함수 종속성의 결정자가 prime 애트리뷰트여야 함
- e.g. { 학번 } → 학부, { 학부 } → 등록금, { 학번 } → 등록금
{ 학부 }가 등록금을 결정하고,{ 학번 }이 학부를 결정정하면,{ 학번 }이{ 등록금 }을 결정할 필요가 없음- "{ 학번 } → 학부"와 "{ 학부 } → 등록금"으로 릴레이션을 분리해야 함
- 모든 애트리뷰트가 후보 키에 속하면 자동으로 만족함
BCNF
for every one of its dependencies X → Y, at least one of the following conditions hold:
- X → Y is a trivial functional dependency (Y ⊆ X),
- X is a superkey for schema R.
3NF이면서, 모든 함수 종속성의 결정자가 슈퍼 키여야 함
- e.g. { 학번, 과목 } → 교수, { 교수 } → 과목
과목의 결정자가 후보키가 아닌{ 교수 }임- "{ 학번, 과목 }"과 "{ 교수 → 과목 }"으로 릴레이션을 분리해야 함
인덱스(Index)
조회 속도를 높이기 위한 자료 구조
인덱스 구조
- 클러스터(Cluster): 여러 개를 묶음 (비슷한(연속된) 값을 묶어서 저장하자!)
Clustered Index
인덱스와 같은 순서로 데이터를 물리적으로 정렬하는 방식
- 한 테이블에 오직 하나만 존재할 수 있음 (보통 PK에 사용)
- 전반적인 조회 속도를 크게 향상시킴
- 디스크에서 데이터가 순서대로 저장되기 때문에, 데이터를 찾을 때 더 적은 수의 블록을 읽게 됨
- 인덱스 컬럼의 값을 변경할 때 인덱스를 갱신하는 데에 시간이 오래 걸림
- 레코드의 물리적인 위치가 바뀌어야 하기 때문
- B+Tree로 구현되며, 리프 노드에 데이터 페이지가 저장됨
Non-clustered Index
임의의 순서로 존재하는 데이터를 논리적으로 정렬하는 방식
- 인덱스의 순서와 상관없이 행이 물리적으로 저장됨
- 일반적으로 PK가 아닌,
JOIN과WHERE,ORDER BY절에 사용되는 컬럼들에 사용함 - 한 테이블에 여러 개 존재할 수 있음
- B+Tree로 구현되며, 리프 노드에 데이터 페이지의 포인터가 저장됨
인덱스 종류
Dense vs Sparse
밀집 인덱스(Dense index)
Key를 통해 레코드를 찾는 방식 (Key가 레코드를 가리킴)
- 이진 탐색을 통해 빠르게 찾을 수 있음 (읽기에 강함)
- 레코드들이 정렬된 상태일 필요가 없음
- DML 작업 시마다 인덱스를 갱신해야 함 (쓰기에 약함)
- MySQL InnoDB의 인덱스는 밀집 인덱스임
희소 인덱스(Sparse index)
Key를 통해 여러 레코드가 담긴 블록을 찾는 방식 (Key가 블록을 가리킴)
- 이진 탐색을 통해 블록을 찾고, 그 블록 내에서 또 다시 찾아야 함 (읽기에 약함)
- 따라서 블록 내 레코드가 정렬된 상태여야 함
- DML 작업이 밀집 인덱스보다 빠름 (쓰기에 강함)
Primary vs Secondary
기본 인덱스(Primary index)
키 필드를 위한 인덱스
- 테이블이 생성될 때 만들어짐
- MySQL InnoDB에서는 Primary index와 Clustered index가 같음
PRIMARY KEY키워드로 표현
보조 인덱스(Secondary index)
키가 아닌 필드들을 위한 인덱스
- MySQL InnoDB에서는 Secondary index와 Non-clustered index가 같음
INDEX키워드로 표현
인덱스의 성능
인덱스는 읽기와 쓰기 작업의 trade-off임
- 중복이 많고, DML이 자주 일어나는 컬럼은 인덱스로 지정해선 안 됨 (인덱스를 만드는 일은 무겁다!)
- Cardinality: 한 인덱스 컬럼에 저장된 값들의 유일성을 나타내는 것 (중복을 제외한 총 원소의 개수)
- Cardinality가 높은 컬럼일수록 좋음 (값의 범위가 커야 중복이 덜 하다!)
- 여러 컬럼을 인덱스로 지정할 경우, 높은 Cardinality가 먼저 오도록 함 (중복이 덜한 컬럼을 먼저 봐야 초반에 많은 데이터가 걸러진다!)
트랜잭션(Transaction)
데이터베이스의 논리적 작업 단위
ACID
트랜잭션이 안전하게 수행되기 위해 갖는 특성
- 원자성(Atomicity): 트랜잭션은 부분적으로 처리되지 않음
- 변경 사항의 일부만 반영되면 데이터의 일관성이 깨진다!
- 일관성(Consistency): 트랜잭션 실행 후에도 데이터베이스가 여전히 유효한 상태임
- 제약 조건이나 cascade 등 정해진 규칙들을 지켜야 한다!
- 독립성(Isolation): 트랜잭션 실행이 독립적이여서 동시에 수행될 수 있음
- 트랜잭션 실행 중에 다른 트랜잭션에서의 변경 사항을 알 수 없도록 한다! (Concurrency control)
- 지속성(Durability): 트랜잭션 결과는 영구적으로 보존됨 (정전이 나도 복구됨)
- 데이터를 비휘발성 메모리(디스크)에 저장하기 때문!
Redo와 Undo
- Redo logs: 모든 작업을 기록하는 곳
- 데이터베이스에 크래시가 났을 때 복구하기 위해 읽음
- Undo logs: 트랜잭션 내에서 변경 사항을 만들 때마다 기존 값을 기록하는 곳
- 트랜잭션 롤백 시 원래 상태를 복구하기 위해 읽음 (작업을 거꾸로 수행함!)
격리 수준(Isolation Level)
트랜잭션의 독립성을 위해 동시성을 희생하는 방법
| Dirty read | Non-repeatable read | Phantom read | |
|---|---|---|---|
| Read uncomitted | ◯ | ◯ | ◯ |
| Read comitted | ✕ | ◯ | ◯ |
| Repeatable read | ✕ | ✕ | ◯ |
| Serializable | ✕ | ✕ | ✕ |
Read uncomitted
가장 낮은 단계의 동시성, 아무 것도 안 함
- Dirty Read 문제가 발생함
- 다른 커밋되지 않은 트랜잭션이 수정한 데이터를 읽을 수 있음 (내가 건든 적 없는 데이터가 나온다!)
Read committed
커밋 이후의 데이터만 읽을 수 있도록 함
- write lock을 걸면 단순히 구현 가능
- Non-repeatable read 문제가 발생함
- 두 번의 read 사이에서 다른 트랜잭션의 커밋으로 데이터가 변경되면, read의 결과가 서로 다를 수 있음 (내가 건든 적 없는데 바뀐다!)
Repeatable read
반복적인 read의 결과가 서로 같도록 함
- read lock과 write lock을 모두 걸면 단순히 구현 가능
- Phantom read 문제가 발생함
- 한 트랜잭션이 읽고 있는 레코드 범위 내에서, 다른 트랜잭션이 새 레코드를 추가하거나 기존 레코드를 삭제하면, 해당 변경 사항이 트랜잭션에 노출됨 (아까 봤던 레코드가 사라졌다!, 아깐 없었던 유령 레코드가 보인다!)
Serializable
가장 높은 단계의 동시성, 각 트랜잭션이 마치 연속적인 방식처럼(serializably) 실행됨
- read lock과 write lock, range-lock을 걸면 단순히 구현 가능
- 독립성이 완벽한 만큼 동시성이 크게 떨어짐 (너무 느리다!)
동시성 제어(Concurrency Control)
낮은 Isolation level에서 데이터의 일관성을 지킴으로써 트랜잭션의 동시성을 높이는 기술
2PL(Two-phase locking)
트랜잭션이 수행되는 동안 데이터의 접근을 잠굼
- 확장 단계 → 데이터 연산 수행 → 수축 단계
- 확장 단계(Expanding phase): 데이터에 잠금을 검
- 수축 단계(Shrinking phase): 데이터의 잠금을 품
- 다른 트랜잭션이 잠긴 데이터에 접근하려면, 잠금이 풀릴 때까지 대기해야 함 (blocking)
- 따라서 Deadlock이 발생할 수도 있음 (주의해야 함!)
Lock의 종류
- Read-lock(shared-lock, s-lock): 읽기 잠금(공유 잠금)
- 다른 트랜잭션이 대상을 읽을 수만 있도록 잠굼
- 대상을 읽기 위해 사용함 (내가 이거 잠깐 볼건데 건들지 마봐!)
- read-lock이 걸린 레코드에 다른 트랜잭션이 read-lock을 걸 수 있음
- read-lock이 걸린 레코드에 다른 트랜잭션이 write-lock을 걸려면 대기해야 함
- Write-lock(exclusive-lock, x-lock): 쓰기 잠금(배타적 잠금)
- 다른 트랜잭션이 대상을 읽지도, 쓰지도 못 하도록 잠굼
- 대상에 DML 연산을 적용하기 위해 사용함 (내가 이거 바꿀거니까 손 대지 마!)
- write-lock이 걸린 레코드에 다른 트랜잭션이 read-lock이나 write-lock을 걸려면 대기해야 함
| Lock type | read-lock | write-lock |
|---|---|---|
| read-lock | 양립 ◯ | 양립 ✕ |
| write-lock | 양립 ✕ | 양립 ✕ |
낙관적(Optimistic) 동시성 제어
잠금을 사용하지 않고 작업하며, 다뤘던 데이터가 커밋 시에 최신 버전인지 검사
- 정수나 Timestamp 등의 형태로 데이터의 버전을 다룸
- 트랜잭션을 커밋할 때, 다른 트랜잭션이 데이터를 수정해 버전이 바뀌었다면 트랜잭션을 롤백함
- 데이터에 대한 경쟁이 적을 때 사용함
MVCC(Multiversion concurrency control)
데이터베이스의 특정 시각 상황을 제공함으로써 트랜잭션 환경을 격리
- 잠금을 걸지 않으므로 다른 트랜잭션들이 블록되지 않음
- MySQL InnoDB는 기본적으로 Repeatable read 단계와 MVCC 기술을 사용함 (Consistent read)
- Undo 로그를 통해 특정 시각 상황을 읽어냄 (이전의 이전의 ...의 값!)
- 트랜잭션 내 최초
SELECT문이 실행된 시점의 Snapshot을 읽어 동작을 수행함- 따라서 Phantom read가 발생하지 않음 (과거 시점을 읽으므로!)
- 이때, DML 연산을 적용한 데이터들에 대해서는 이후
SELECT시 최신 데이터를 불러옴- 최신 데이터에는 다른 트랜잭션이 커밋한 내용이 있을 수 있음
- 따라서 DML 연산을 적용하려면 write-lock을 걸어둬야 함 (Non-repeatable read가 발생할 수 있으므로!)
- Serializable 단계는
SELECT마다 read-lock을 거는 방식으로 구현함
ORM
Object-relational mapping: OOP 언어로 데이터베이스를 다룰 수 있도록 하는 기술
- 데이터베이스를 객체 지향적으로 다룰 수 있음
- 객체-관계 임피던스 불일치: ORM이 RDB를 다루기 위해서 객체를 테이블로 매핑해야 하는 문제
- 이를 최소화할 수 있으나, 타입 안전성이나 성능 문제 등 한계가 존재함
