DDMI: Domain-Agnostic Latent Diffusion Models For Synthesizing High-Quality Implicit Neural Representations (1)
DDMI
Abstract
기존 모델들은 도메인에 구애 받지 않는 생성 모델의 가능성을 열어줬지만, 고품질 이미지 생성을 달성하지 못하는 경우가 많았다.
그 이유는 고정 위치 임베딩(PE)을 사용하여 신경망의 가중치를 생성하고 평가하는데, 이는 생성모델의 표현력을 제한하고 낮은 품질의 INR(신경망을 사용하여 연속적인 신호나 데이터를 암묵적으로 표현하는 방법) 생성을 초래하기 때문이다.
💡 핵심 아이디어
DDMI: 도메인 무관 잠재 확산 모델
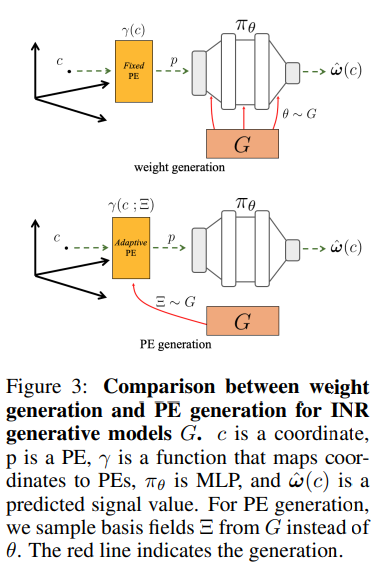
- 신경망의 가중치 대신 적응형 위치 임베딩을 생성
- 이산 데이터를 연속 신호 함수와 연결하는 D2C-VAE를 개발
- 계층적으로 분해된 PEs를 사용해 INRs를 평가하는 새로운 conditional mechanism도입-> 표현력 향상
Introduction
- 도메인에 구애받지 않는 DDMI를 소개하여, 다양한 도메인에서 고품질의 INR을 생성하는 모델을 제안
- 이산 데이터를 연속 함수 공간과 연결하는 공유 latent space를 학습하는 Discrete to Continuous space Variational AutoEncoder (D2C-VAE)를 정의하여 적응형 위치 임베딩(PEs)을 생성
- 표현력을 향상시키기 위해 Hierarchically-Decomposed Basis Fields (HDBFs) and Coarse-to-Fine Conditioning (CFC)를 제안
- 네가지 모달리티와 일곱 개의 벤치마크 데이터셋을 통한 실험을 통해 DDMI의 우수성 입증
Related Works
- INR-based genertive models.
- 2D 이미지에는 CIPS와 INR-GAN이, 3D 형태에는 GANs나 확산 모델을 사용하는 연구가, 비디오에는 DIGAN과 StyleGAN-V가 사용됨
- 그러나 이러한 모델들은 특정 모달리티에 맞춰져 있어 다양한 신호에 적응하기 어려움
- GASP, Functa, GEM, DPF와 같은 도메인-무관 아키텍처가 연구되었으나, 대규모 데이터셋 처리에 한계가 존재
- 2D 이미지에는 CIPS와 INR-GAN이, 3D 형태에는 GANs나 확산 모델을 사용하는 연구가, 비디오에는 DIGAN과 StyleGAN-V가 사용됨
논문에서는 MLP의 가중치 대신 적응형 위치 임베딩을 생성하는 도메인 무관 생성모델을 제안
- Latent diffusion models.
- 확산 모델은 고품질 결과를 얻지만, 많은 단계가 필요하며 비효율적임
- 최근에는 데이터 분포를 저차원 latent space에서 학습하여 효율성을 높인 LDM이 제안
논문에서는 LDM을 채택하여 효율적인 생성 모델을 설계
Methodology
- D2C-VAE가 shared latent space를 학습함
- 고정된 네트워크를 유지하면서 shared latent space에서 확산 모델을 훈련
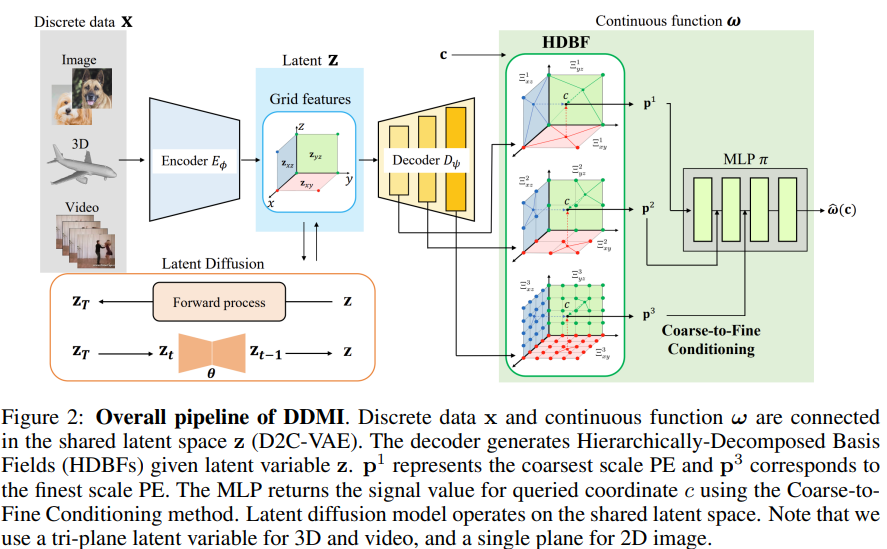
DDMI
이 논문에서 는 임의의 신호와 그 신경망에 의한 근사값을 나타내는 연속 함수로, 는 연속 함수 공간을 의미한다. 좌표 c가 주어졌을 때, 훈련 데이터 x는 좌표에서 연속 함수의 평가값으로 볼 수 있으며, 이는 로 표현된다.
D2C-VAE.
D2C-VAE는 불연속 데이터 공간과 연속 함수 공간을 공유된 잠재 공간을 통해 연결하는 비대칭 VAE아키텍처다. 인코더 는 불연속 데이터x를 2D격자 특징으로 잠재 변수 z에 매핑하며, 디코더는 z로부터 기저 필드를 생성한다. 좌표 c에 대한 위치 임베딩 p는 bilinear interpolation을 통해 계산되며, 최종적으로 MLP 가 위치 임베딩 p를 입력받아 신호 값을 반환한다.
이 방법은 기존의 INR 생성 모델보다 더 뛰어난 표현력을 제공하며, 특히 위치 임베딩 생성이 성능을 향상시키는 것으로 나타났다.
Hierarchically-decomposed basis fields.
단일 스케일의 basis field에 의존하지 않고, 신호의 다중 스케일 특성을 더 잘 반영하기 위해 이를 여러 스케일로 분해하는 방법.
다중 스케일의 basis fields를 효율적으로 생성하기 위해 단일 신경망의 특징 계층구조를 활용.
📌 HOW?
- 디코더 는 다양한 스케일 i에서 특징 맵을 출력
->- 특징 맵들은 1x1 합성곱을 통해 각 스케일 간의 특징 차원을 맞춤
이렇게 분해된 basis fields를 Hierarchically-decomposed basis fields(HDBF)라고 한다. 실험 결과, HDBF에서 생성된 샘플들의 공간 주파수가 여러 수준으로 분해됨을 확인했으며, 각 필드는 특정 세부 사항을 학습하는데 집중하여 더 표현력 있는 표현을 제공한다는 것을 입증함
Coarse-to-fine conditioning (CFC).
CFC는 HDBF의 다중 스케일 위치 임베딩을 MLP 에 사용하는 방법으로, 단순히 채널 차원에서 이를 연결하는 방식이 비효율적이기 때문에, 점진적으로 낮은 스케일에서 높은 스케일로 MLP를 조건화하는 기법을 제안한다. 이를 통해 낮은 스케일의 basis fields가 더 높은 스케일의 basis fields에서 놓친 세부 사항에 집중할 수 있도록 유도한다. 구체적으로, 가장 낮은 스케일의 위치 임베딩을 MLP에 입력한 후, 중간 출력을 다음 스케일의 위치 임베딩과 연결하는 과정을 반복해 최종 스케일까지 진행한다.
Training Procedure and Inference
[DDMI training Stage]
1. D2C-VAE는 인코더 를 통해 불연속 데이터를 잠재 벡터 z로 매핑하고, 디코더 를 사용해 기저필드 를 생성하며 공유된 잠재 공간을 학습한다.
2. 잠재 공간에서 확산 모델을 훈련시켜 잠재 벡터 z의 경험적 분포를 학습한다.
D2C-VAE training.
D2C-VAE를 훈련시킬때 discrete data x를 사용하여 연속 함수의 log likelihood의 evidence lower boiund(ELBO)를 최대화 시키도록 훈련한다.
