

현재 수학 및 과학 타이핑 부업을 하고 있는데,, 아무래도 전공과는 무관한 부업이기도 하고 슬슬 웹크롤링으로 넘어가볼까?하는 막연한 생각으로..작년 여름부터 공부하자고 다짐하다가 1년뒤에 시작하는. 그런 인생을 살고 있어요
1. Web Crawling이란?
웹사이트의 데이터를 자동으로 수집하는 기술 또는 작업을 의미한다.
📌 예를 들어:
- 뉴스 사이트의 기사 제목과 날짜를 자동으로 모으고 싶다
- 쇼핑몰의 상품 가격 변동을 추적하고 싶다
- 명언 사이트에서 명언들을 수집하고 싶다
→ 이럴 때 웹 크롤러를 만들어 자동으로 정보를 수집할 수 있다.
📚 용어 정리
| 용어 | 설명 |
|---|---|
| 크롤링 (Crawling) | 웹페이지를 방문해서 데이터를 수집하는 것 |
| 스크래핑 (Scraping) | HTML에서 원하는 부분만 "긁어내는" 작업 |
| 파싱 (Parsing) | HTML을 구조화해서 원하는 태그나 정보를 찾는 과정 |
참고: 크롤링 = 방문 + 수집, 스크래핑 = 필요한 정보만 추출
2. HTML 요소 이해
| 요소 | 설명 |
|---|---|
| body 요소 | <body>로 시작해서 </body>로 끝나는 모든 HTML 요소 |
| div 요소 | <div>로 시작해서 </div>로 끝나는 블록 단위의 요소 |
3. 사용된 Python 모듈
| 모듈 | 설명 |
|---|---|
requests | 웹 서버에 HTTP 요청을 보내고 응답을 받아오는 라이브러리 |
bs4 (BeautifulSoup) | HTML/XML 문서를 파싱하고 탐색할 수 있는 라이브러리 |
💡 설치가 필요하다면:
pip install requests beautifulsoup4
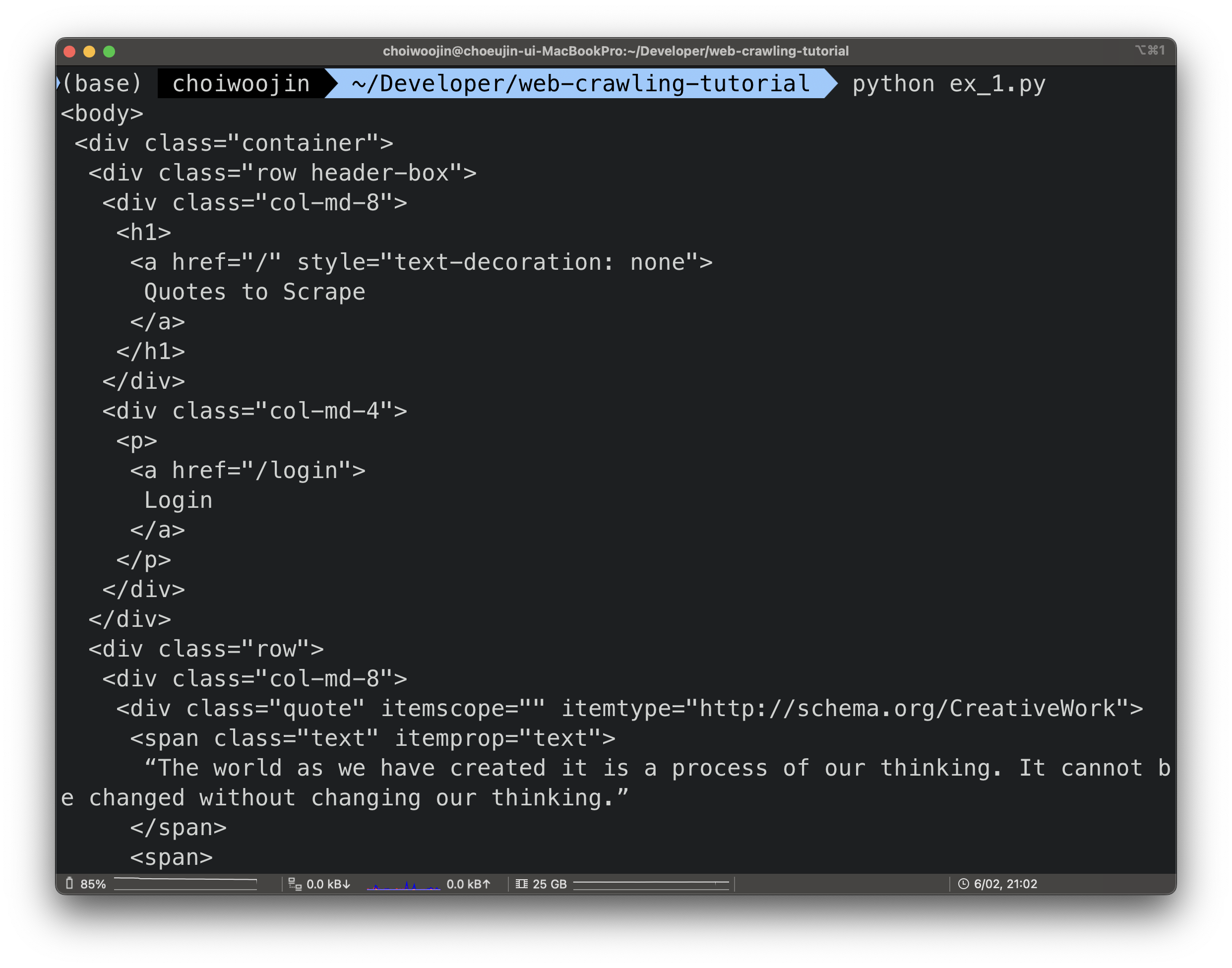
ex 1) Quote.toscrape의 <body> 요소 추출
import requests
from bs4 import BeautifulSoup
# 1. 대상 URL
url = 'https://quotes.toscrape.com'
# 2. 페이지 요청
response = requests.get(url)
response.raise_for_status() # 에러 발생 시 예외 처리
# 3. HTML 파싱
soup = BeautifulSoup(response.text, 'html.parser')
# 4. <body> 요소 추출
body = soup.body
# 5. 결과 출력
print(body.prettify()) # 보기 좋게 들여쓰기 출력출력 결과
ex 2) class 값이 "quote"인 div 요소들의 텍스트 모두 추출
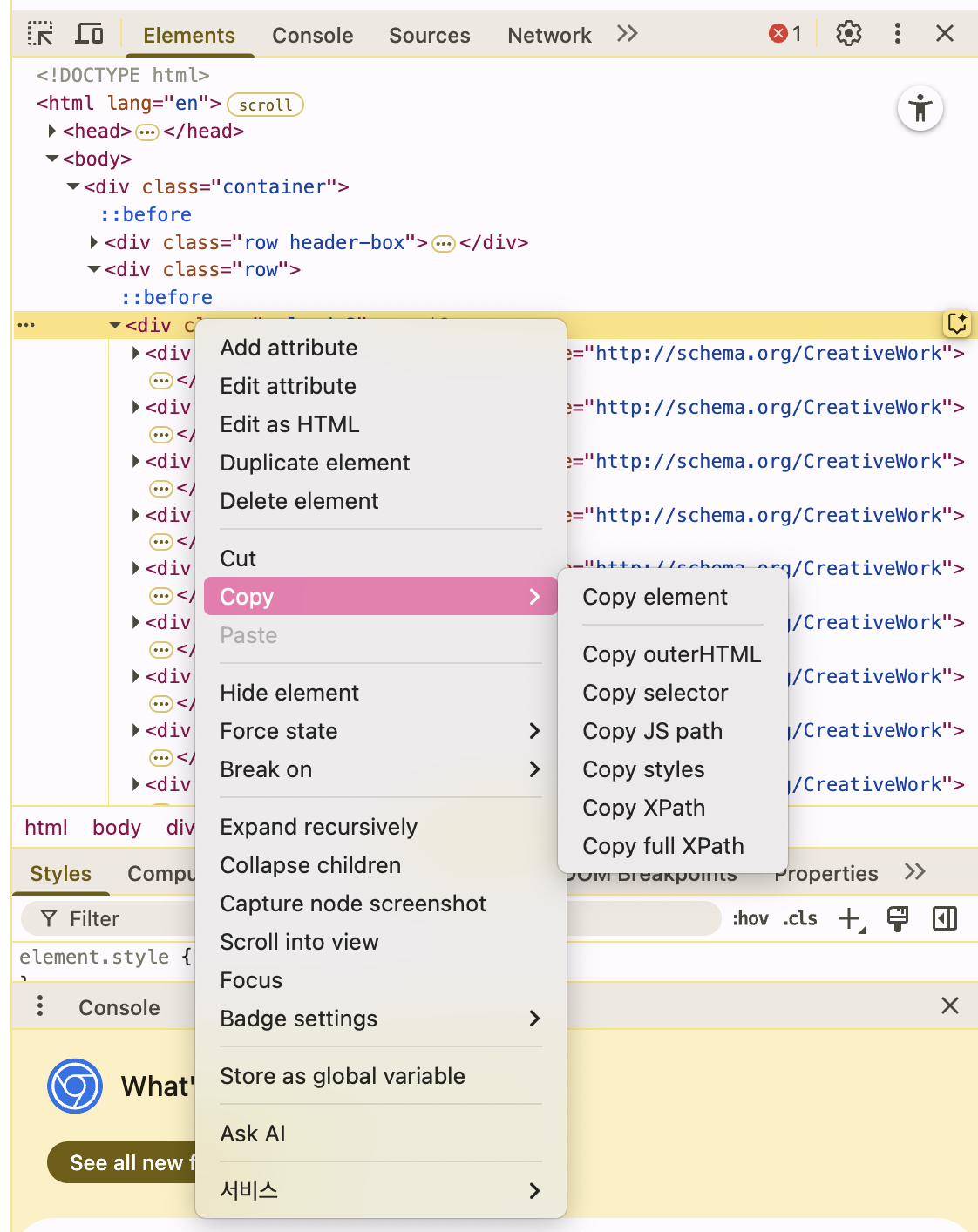
copy 용도 예시
| 메뉴 항목 | 설명 |
|---|---|
| Copy element | HTML element markup 선택한 요소 전체의 HTML 마크업 |
| Copy outerHTML | Outer HTML serialization 요소 자체 + 내부 콘텐츠를 포함한 HTML 문자열 |
| Copy selector | CSS selector path 해당 요소를 지정할 수 있는 CSS 선택자 경로 |
| Copy JS path | JavaScript DOM query path JavaScript로 DOM 요소에 접근할 수 있는 경로 |
| Copy styles | Inline and computed CSS styles 요소에 적용된 CSS 스타일 속성들 |
| Copy XPath | Relative XPath expression 선택한 요소에 대한 상대 XPath 경로 |
| Copy full XPath | Absolute XPath expression HTML 문서 루트부터의 절대 XPath 경로 |
body > div > div:nth-child(2) > div.col-md-8요소 안에 클래스 값이 "quote"인 div 요소들의 텍스트 출력
소스코드
import requests
from bs4 import BeautifulSoup
# 웹페이지 요청
url = "http://quotes.toscrape.com"
response = requests.get(url)
soup = BeautifulSoup(response.text, "html.parser")
# body > div > div:nth-child(2) > div.col-md-8 안의 div.quote 요소 선택
quote_container = soup.select_one("body > div > div:nth-child(2) > div.col-md-8")
quotes = quote_container.find_all("div", class_="quote")
# 텍스트 출력
for quote in quotes:
text = quote.find("span", class_="text").get_text(strip=True)
author = quote.find("small", class_="author").get_text(strip=True)
print(f"{text} — {author}")
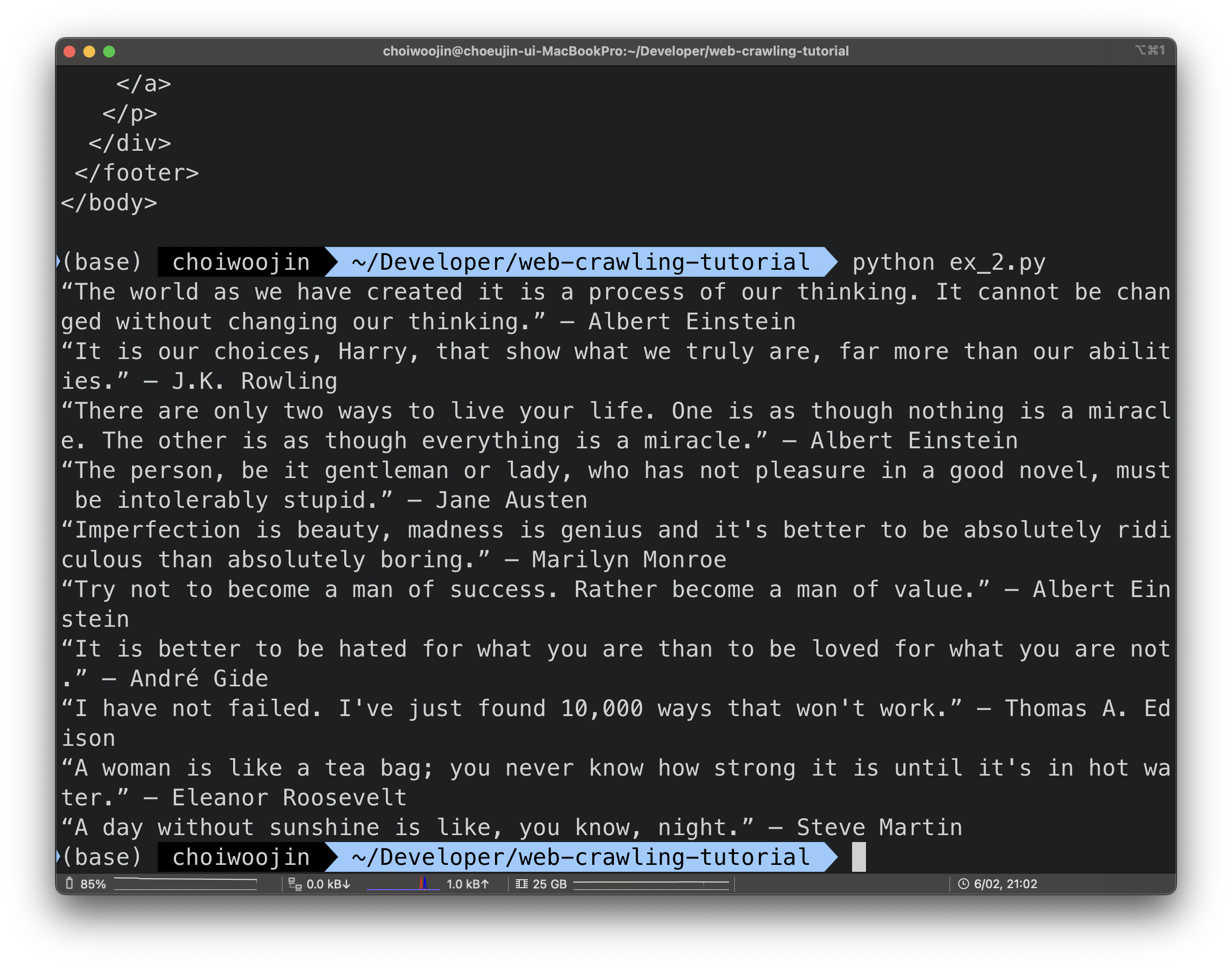
출력결과
🔗 참고자료
⚒️ 개발자 도구 열기
- macOS: 우클릭 > 검사
- Windows:
F12키
🤓 마무리 말
HTML 공부를 손에 놓은지 3년(..?)은 다되어가는 것 같은데 그동안 gpt의 무궁무진한 성장으로 공부해야겠다는 생각을 안하고 있다가.. 전혀 기억이 안나는 그런 사태가 발생했다. 정신체리.🍒🍒🍒

일단 하긴 합니다.