1. 개요
현존하는 해시 함수들(SHA, KECCAK 등)은 수 많은 비트 연산들로 정의되기때문에 컴퓨터로 빠르게 연산 결과를 얻을 수 있다. 하지만 해시함수를 구성하는 모든 비트 연산들을 산술연산으로 표현하려면 많은 제약식들이 필요하고 이는 해시 함수의 입출력 관계에 대한 영지식 증명 회로가 상대적으로 커지게 되는 요인이다. 예를 들어, 다음과 같은 비트 shift 연산을 생각해보자.
비트 연산에 대한 제약조건들을 산술 연산을 이용해서 보이려고 하면, 의 각 자릿수의 이진수를 순서대로 그리고 의 각 자릿수의 이진수를 라고 할때 다음과 같은 식들이 만족함을 보여야 한다.
반면에, 임의의 큰 소수 에 대해 정의되는 prime field 에서 다음식은 위와 동일한 연산을 나타낸다.
따라서, 에 대해서 다음 식을 만족함을 보이면 충분하다.
(이해를 돕기위해 예시를 든것이지 실제로 비트연산을 보이려는 경우에 대한 제약식과 이에 대응되는 산술연산의 제약식은 주어진 상황, 혹은 구현에 따라 다를 수 있다.)
기존의 해시 함수들은 대부분 비트 연산들로 구성되어 있어서 이를 산술 연산들로 표현하기 위해서는 많은 제약식을 필요로 하는데, Poseidon hash는 이러한 문제를 해결하고자 prime field에서의 연산들을 기반으로 설계되었다. 즉, 함수의 내부 연산들은 기존의 비트 연산들을 활용하는 해시함수와는 달리 처음부터 와 같은 산술 연산으로 정의되므로 상대적으로 더 적은 산술 제약식으로 표현가능하다.
2. 구조
Notations & Definitions
- padding: 입력 데이터가 정확히 rate의 배수가 아닌경우, 데이터를 채우는 방법이다.
- permutation: 고정 길이의 블록으로 나뉜 데이터를 섞는 과정으로, 는 permutaiton 함수를 나타내며 고정된 크기의 입력을 받아 동일한 크기의 출력을 만든다.
- 은 rate를 의미하는 poseidon hash 함수에서 메세지 처리 단위로, 데이터를 rate 단위로 나누어 연산한다.
- 는 capacity로 이 값이 클수록 더 높은 보안 수준을 의미하지만 처리 속도는 느려질 수 있다.
- 라운드 횟수: 스펀지 구조에서 permutation을 여러 라운드에 걸쳐 반복적으로 적용하는데, 이때의 반복횟수를 의미하며 파라미터 설정에 따라서 변경될 수 있다.
- state: permuation 과정의 중간 계산 결과이다. state의 길이 는 으로 계산되며 라운드를 거치면서 값이 변경된다.
Sponge 구조
Sponge 구조란, 암호학에서 해시함수를 설계할 때 사용되는 구조로 임의의 길이의 입력을 받아 고정 또는 임의의 길이의 출력을 생성한다. 일반적으로 흡수(Absorbing)와 추출(Squeezing)이라는 두가지 알고리즘으로 정의된다.
- 흡수(Absorbing): Sponge 구조에서 입력 데이터를 Sponge 함수의 내부 상태에 누적하는 과정
- 추출(Squeezing): Sponge 함수의 내부에 흡수된 state에서 출력 데이터를 가져오는 과정
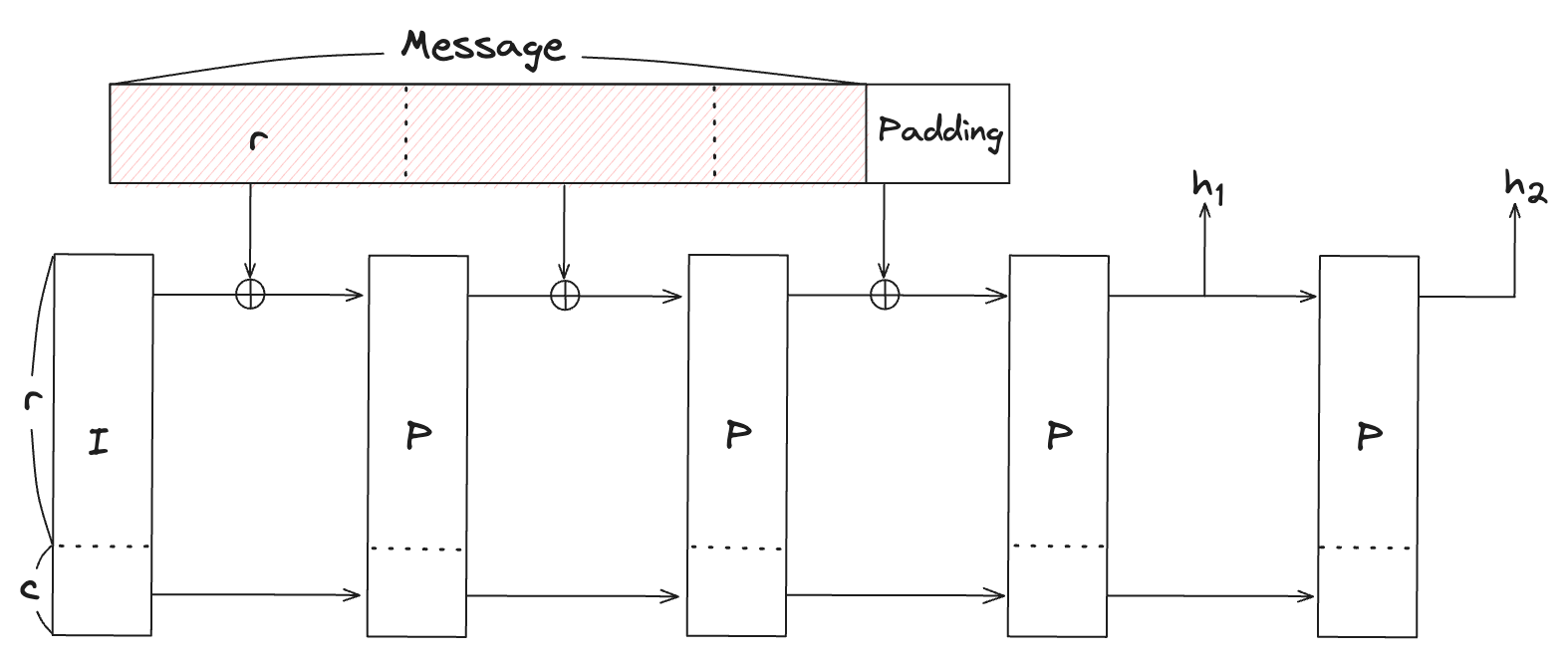
Poseidon hash 함수는 여러 라운드에 거쳐서 permutation을 수행하는 sponge 구조로 구성된다. 아래 그림처럼 메시지를 rate로 나누어 각 permutation의 출력에 더해주어 연산이 이루어지며, permutation은 모든 메세지를 처리할때 까지 반복해서 수행된다.
각 단계는 다음과 같은 과정들로 이루어진다.
- 초기화: 내부의 state를 와 같은 값으로 초기화 한다.
- 흡수(Absorbing): 입력 데이터를 개의 블록들로 나눈다. 예를들어, 입력 데이터의 길이가 이라면 길이가 이 되도록 패딩을 채워준 다음 의 네개의 블록으로 나눈다. 초기 state의 과 첫번째 데이터 블록을 더하고 더한 결과를 나머지 초기 state의 나머지 를 연접한 결과를 permutation한다. 여기서 더하기란 field에서의 덧셈 연산을 의미한다. permutation의 결과는 다음번의 state가 되며 그다음 데이터 블록에 대해서 이를 반복한다.
- 추출(squeezing): 원하는 길이의 해시 값을 생성할 때까지 내부 state의 일부를 추출하고 permutation을 적용한다. 해시 출력을 얻기 위해서 마지막 permutation에서 추출후, permutation을 적용한 다음 를 추출한다. 최종 출력 결과는 이다.
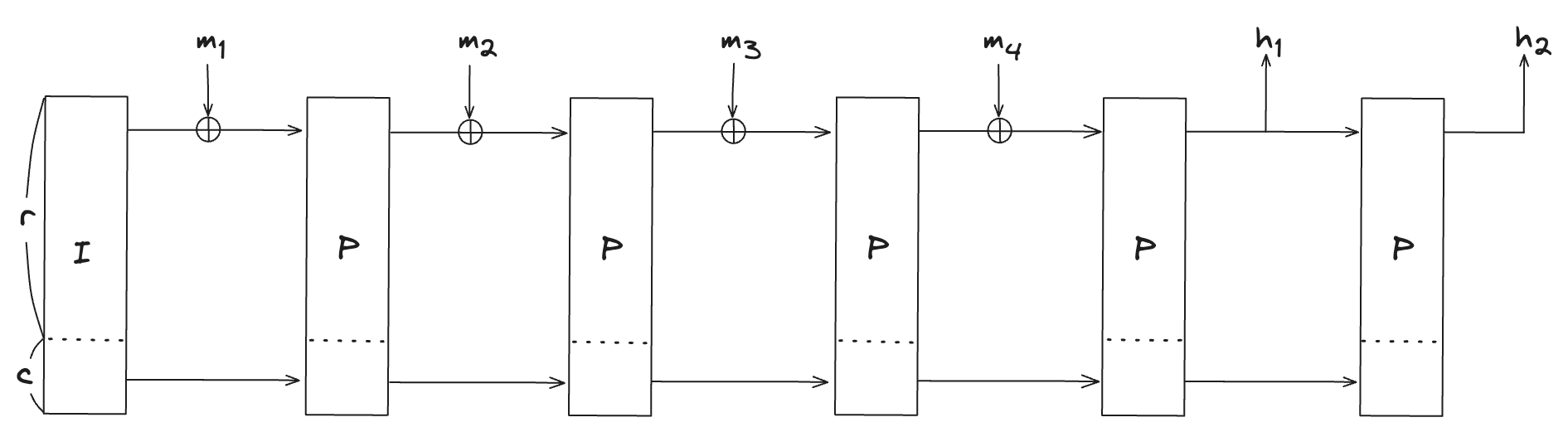
이 내용을 인경우를 예로 들어서 메세지를 처리하는 과정을 대략적으로 살펴보자. 은 임의의 길이의 메세지를 처리하기 위해 긴 메세지를 chunk들로 나누기 위한 단위이며 state의 길이는 로 각 라운드를 진행함에 따라 state 값이 업데이트 된다.
-
초기 설정: 초기 값 , 메시지 라고 가정하자.
-
메세지 블록 나누기: 주어진 메세지를 단위의 chunk들로 나눈다. 즉, 와 로 나눈다.
-
첫 번째 라운드: 초기 값에 첫 번째 블록을 더해서 을 계산하고 permutation 연산을 적용한다. permutation의 결과는 라고 가정하자.
-
두 번째 라운드: 첫번째 라운드의 결과와 두번째 메세지 블록과 더한 결과 에 다시 permutation 연산을 적용한다. permutation의 결과는 라고 가정하자.
-
해시값 출력: 여기에 한번더 permutation 연산을 적용한다. 세번째로 적용한 permutation의 결과가 이라고 가정하자. 해시 출력으로 두번째 라운드의 결과에서 첫번째 값과 마지막 permutation 결과에서의 첫번째 값을 가져오면 해시의 출력은 이 된다.
Permutation
Poseidon hash에서 사용하는 permutation은 여러 라운드에 걸쳐 계산이 이루어지며 라운드의 횟수는 파라미터에 따라서 달라질 수 있다. Permutation을 구성하는 라운드는 full, partial 라운드 두가지 종류로 구분되며 논문에서 제시하고있는 permutation의 연산 과정은 다음과 같다.
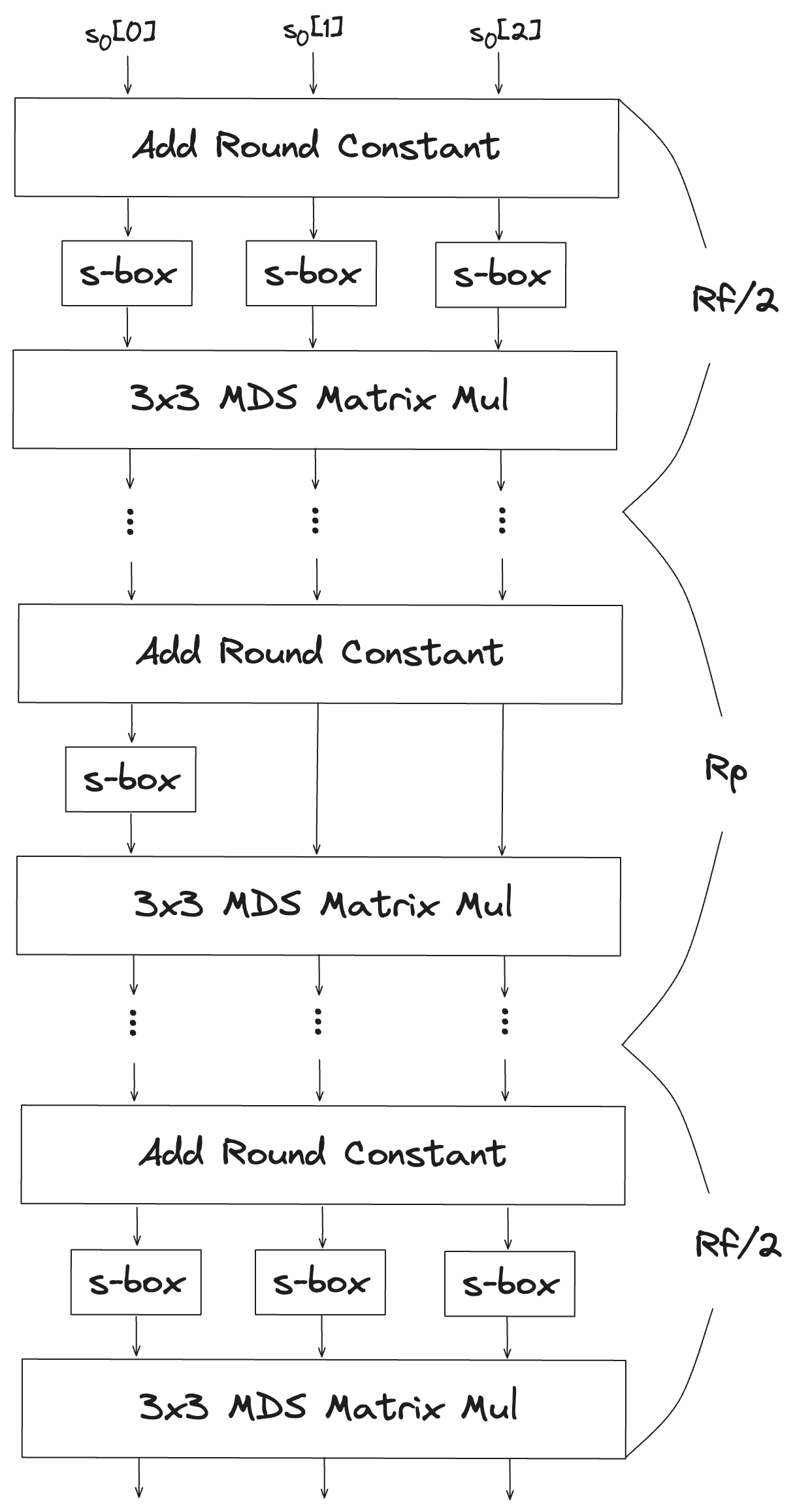
- : full 라운드 진행 횟수
- : partial 라운드 진행 횟수
하나의 라운드는 다음 세가지 연산으로 이루어진다.
- : 라운드 상수 더하기 (AddRoundConstant)
- : s-box (non-linear 연산)
- : MDS(Maximum Distance Separable) 행렬 곱
s-box는 비선형연산으로 선형연산과 비교하여 상대적으로 많은 연산이 필요하게되어 여러 라운드에 거쳐서 비선형연산을 수행시 poseidon hash의 수행 속도에 영향을 주는데, 이는 라운드의 종류를 full과 partial 라운드로 구분하는 이유와 연결이 된다.
1) full / partial 라운드
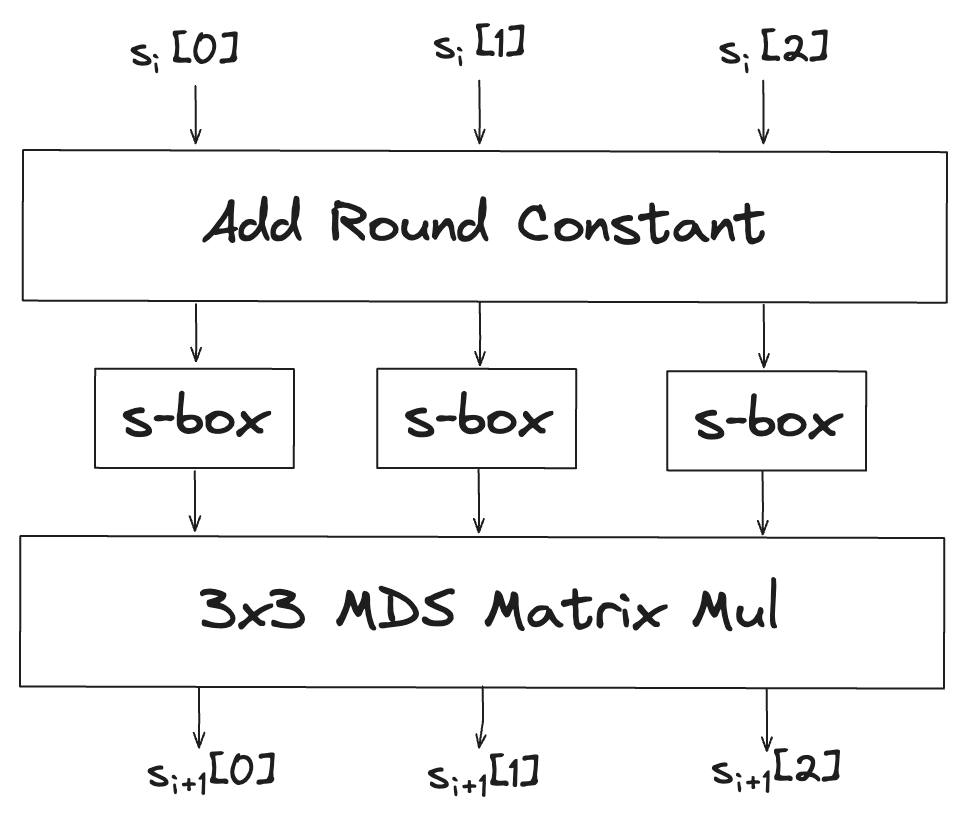
Permutation을 구성하는 라운드는 full, partial 라운드 두가지 종류로 구분되는데 전체 연산의 과정의 흐름은 유사하지만 s-box 연산을 적용하는 방식이 조금 다르다.
-
Full 라운드
-
Partial 라운드
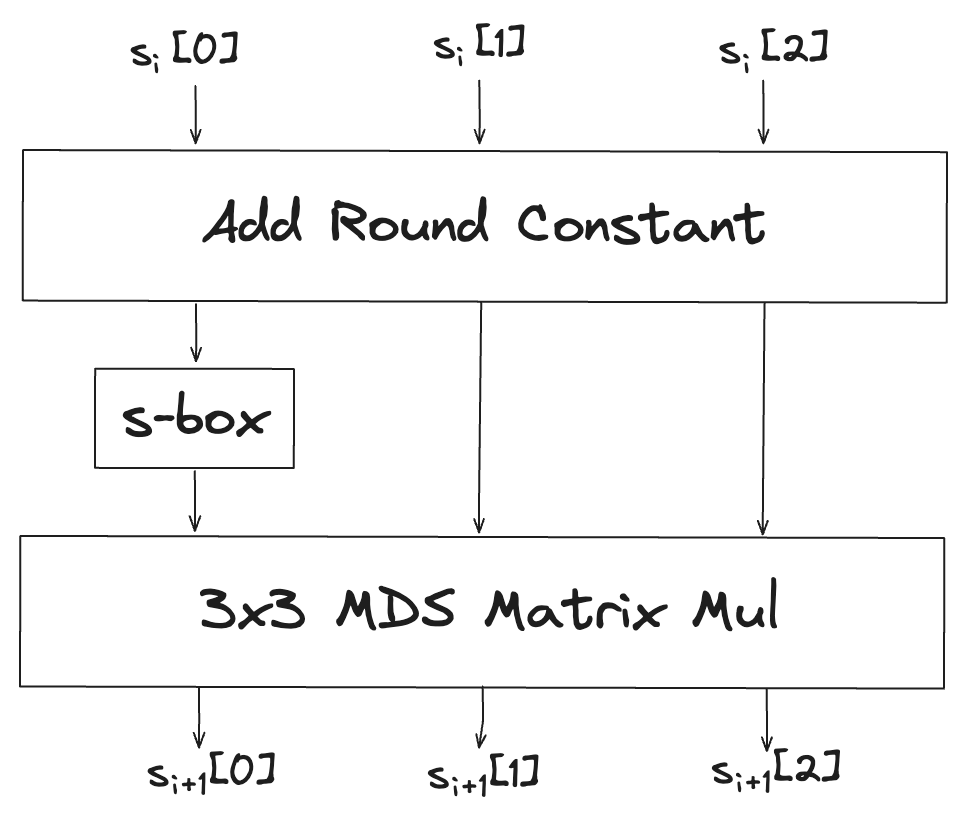
각 라운드들의 입력 및 출력이 되는 값을 state라고하는데, 위 그림에서 확인할 수 있듯이 partial 라운드에서는 일부 state에만 s-box 연산을 적용하기 때문에 더 적은 리소스로 빠르고 효율적으로 연산을 수행할 수 있다.
그러면 모든 라운드를 partial 라운드로 구성해서 훨씬 더 효율성을 얻으면 안될까?라고 생각할 수 있다. 하지만 보안성을 해치지 않는 수준에서 효율성을 유지해야 한다. full 라운드에서는 s-box 연산을 모든 state에 적용하면서 연산비용이 많이들기는 하지만 이 과정을 통해서 모든 state의 값이 변경되어 특정한 입력에 대해 복잡한 재배열과 변환을 수행하여 출력값에 대한 통계적인 공격을 막아주는 기능을 한다.
그러면 중간에 몇 라운드를 partial 라운드로 구성하는것이 안전할까?라는 의문이들 수 있다. 하지만 partial 라운드는 역시 full 라운드와 유사하게 대수적인 공격을 막을 수 있는 기능을 한다.
통계적 공격: 어떤 암호알고리즘의 출력 결과의 통계적인 패턴을 찾아서 원본 데이터나 키를 추측해내는 공격으로 빈도 분석, 차분 공격등이 이에 해당한다.
대수적 공격: 암호 시스템의 대수적인 특성을 이용하는 공격으로 다항식이나 방정식을 통해 암호를 분석해 내는 경우가 이에 해당한다. 결론적으로, partial 라운드와 full 라운드를 적절히 조합함으로써, 특정 응용 상황에서의 보안 요구 사항과 성능 사이에 균형을 맞출 수 있다.
2) 라운드 상수 더하기 (AddRoundConstant)
라운드 상수는 Grain LFSR로 생성되는데, 원하는 파라미터 설정에 따라서 미리 계산해놓고 사용되는 값이다.
3) s-box (non-linear 연산)
비선형 연산 s-box는 입력 에 대해서 로 정의하며 는 3보다 크거나 같으면서 과 서로소인 가장작은 정수로 선택한다. 논문에서는 를 예시로 사용한다.
4) MDS(Maximum Distance Separable) 행렬 곱
MDS행렬은 블록암호나 해시함수 설계등에 많이 활용되는 행렬로 부호이론(coding theory)과 관련이 깊다. 이름 그대로 부호이론에서 정의하는 거리(distance)가 최대가 되는 부호들로 정의되며, 안전한 MDS 행렬의 설정은 논문을 참고하자.
Poseidon hash가 정의된 prime field 에서 와 가 주어졌을때 을 만족하면 이러한 MDS행렬의 존재성이 보장된다.
3. 라운드 횟수 설정
Poseidon 해시 함수에서는 원하는 보안 수준과 너비에 따라 라운드 횟수가 달라질 수 있다. 논문에서는 다음과 같이 이러한 보안 수준과 너비 T를 고려하면서 '보수적으로 설정'한 라운드 횟수 설정 예시를 제공하고 있다. 보수적인 파라미터 설정을 위한 'security margin'에 대한 내용은 논문을 참고하자.
| security level / width | full 라운드 ( RF ) | parital 라운드 ( RP ) |
|---|---|---|
| 128 / 3 | 8 | 57 |
| 128 / 5 | 8 | 60 |
| 80 / 3 | 8 | 33 |
| 80 / 5 | 8 | 35 |
| 256 / 6 | 8 | 120 |
| 256 / 10 | 8 | 120 |
위와 같은 파라미터는 포세이돈 해시 함수가 응용되는 응용 환경의 보안 요구 사항에 따라서 결정되어야 하며 해시의 결과가 충분히 랜덤하고 예측 불가능해야 한다.
4. 정리
Poseidon hash 설계의 핵심적인 요소는 다음과 같다.
- 형식의 비선형 연산을 s-box 연산으로 채택
- permutation의 partial 라운드에서 복잡한 비선형 연산을 state의 일부에만 적용하여 계산의 복잡성을 줄이면서도 라운드의 시작과 끝에는 full 라운드를 배치하여 충분한 암호학적 안전성을 유지
이러한 전략으로 영지식 증명과 같이 산술연산에 특화되어 있으면서 연산의 복잡도에 민감한 여러 암호학적 알고리즘들에서 활용할 수 있는 효율적인 해시 함수를 설계한다.
실제로 여러 영지식 증명을 활용하는 프로젝트들에서 poseidon 해시 함수를 활용해서 circuit을 설계하여 사용한다. 이 다음 글에서는 어떻게 이러한 해시함수를 설계하고 있는지에 대해서 실제 코드와 함께 다루도록 하겠다.
