ECCV의 DETR 이후에 'vision transformer'들 곰국들이 쏟아지고 있다.
새로운 패러다임을 제시한 건 맞는데, '착한 성능에 그렇지 못한 학습 과정'으로 깃허브 이슈부터도 터지곤 했다. (사실 성능도 comparable 하다 수준이지, 엄청 뛰어난 건 또 아니라서..)
그 extension 곰국들 중 오호?/오오~ 스러운 것들 모음.
DETR의 단점 개선
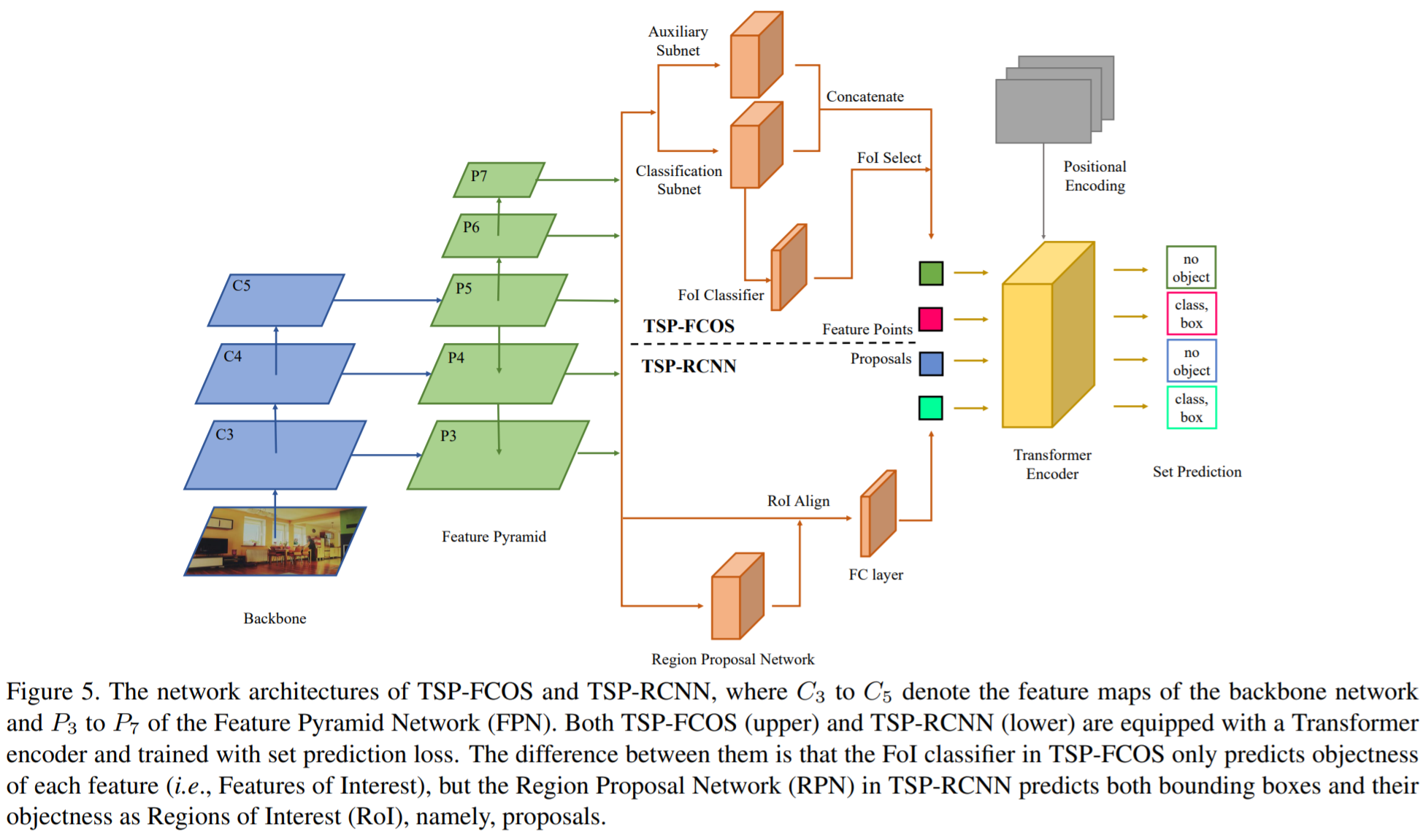
Rethinking Transformer-based Set Prediction for Object Detection 2011.10881
-
풀려는 문제
DETR 학습이 왜 어려운지 분석 및 개선 (Hungarian loss, the Transformer cross attention mechanism) -
제안하는 방법
이를 개선한 새로운 모델 제안 : TSP-FCOS (Transformer-based Set Prediction with FCOS) & TSP-RCNN (Transformer-based Set Prediction with RCNN) -
제안하는 방법의 장점
1) 더 빠른 수렴 2) 더 나은 detection accuracy 성능
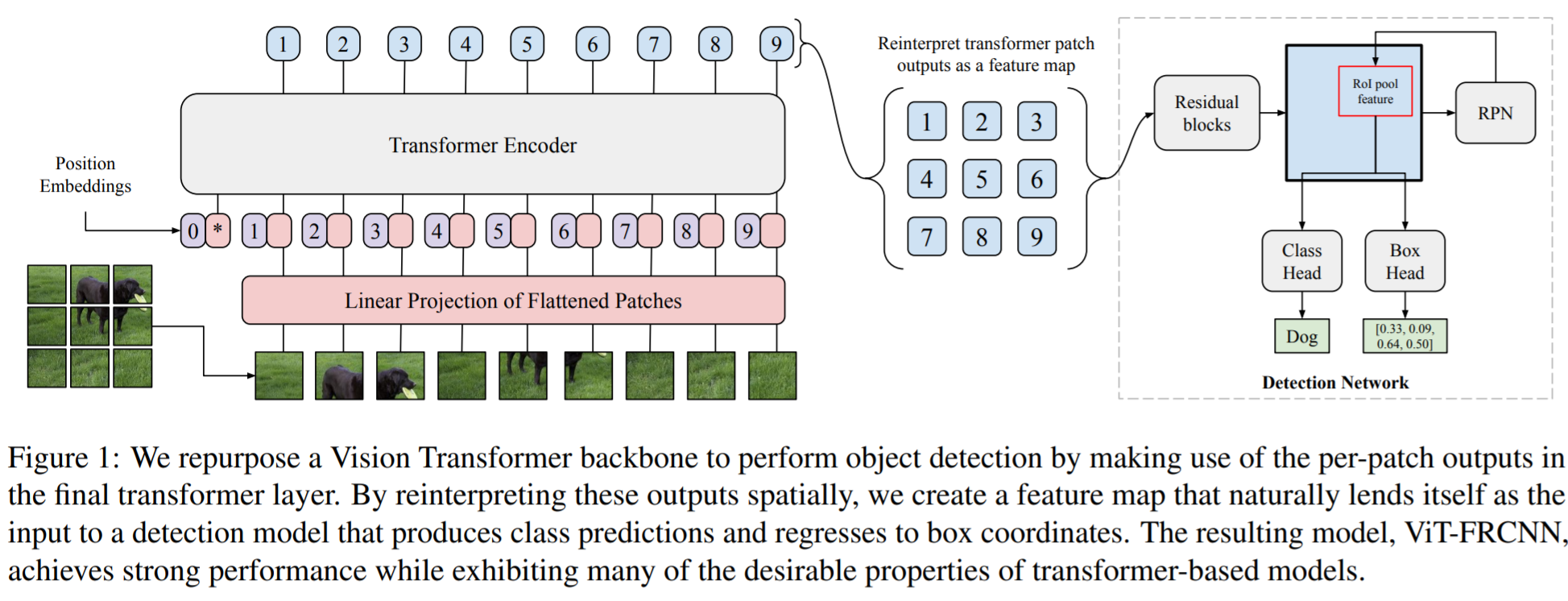
Toward Transformer-Based Object Detection 2012.09958
-
풀려는 문제
비싼 attention 연산 때문에, 더 복잡한 task에서 고해상도 처리 어려움 (detection, segmentation 등)
"Vision Transformer 들이 classification 말고도 잘 할 수 있을까?"
-
제안하는 방법
이를 확인하는 새로운 classification 모델 제안 : ViT-FRCNN -
제안하는 방법의 장점
1) 기존 transformer의 장점 유지 : large pretraining capacity, fast fine-tuning,
2) 기존 backbone 대비 실험적으로 확인된 장점 : better out-of-domain performance, better performance on large objects, and a lessened reliance on non-maximum suppression
3) detection task 의 backbone으로 사용해서 'competitive'한 수준 COCO 결과
-
잡소리
두번째 논문 내신 분, 11월에 앞 논문 올라온 거 보고 철렁하셨을 듯 ㅋㅋㅋ
Graph로 확장
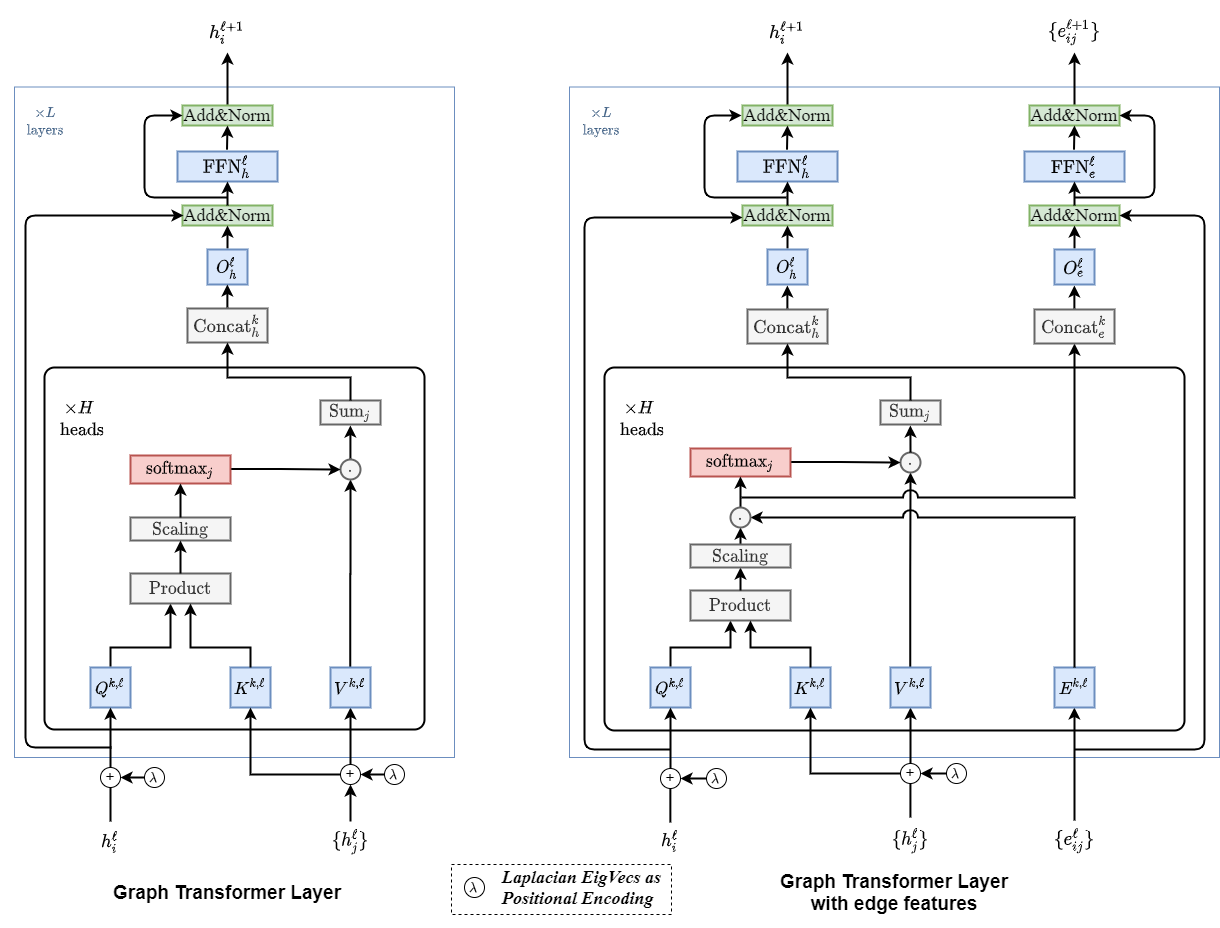
A Generalization of Transformer Networks to Graphs 2012.09699
(AAAI 2021 Workshop on Deep Learning on Graphs: Methods and Applications (DLG-AAAI 2021))
code
-
풀려는 문제
그래프로 Transformer 확장 -
제안하는 방법
각각의 핵심 구성 요소들을 그래프 처리에 맞게 재구성
