[LeetCode Top Interview 150]
[문제 링크]
[문제 설명]
- 무방향 그래프의 전체 클론 반환
- 그래프의 각 노드에는 이웃 노드의 값(int)과 목록List[Node]이 포함되어 있음
class Node {
public int val;
public List<Node> neighbors;
}[테스트 케이스 형식]
- 단순화를 위해 각 노드의 값은 노드의 인덱스와 동일함. 예를 들어 첫 번째 노드는 val == 1, 두 번째 노드는 val == 2
그래프는 인접 목록을 사용하여 테스트 케이스에 표시- 인접 목록은 그래프를 나타내는데 사용되는 순서가 지장되지 않은 목록의 모음. 각 목록은 그래프에 있는 노드의 이웃 집합
- 주어진 노드는 항상 val = 1이 첫번째 노드가 된다. 복제된 그래프에 대한 참조로 지정된 노드의 복사본을 반환해야 함
[예시1]
Input: adjList = [[2,4],[1,3],[2,4],[1,3]]
Otput: [[2,4],[1,3],[2,4],[1,3]]
Explanation: There are 4 nodes in the graph.
1st node (val = 1)'s neighbors are 2nd node (val = 2) and 4th node (val = 4).
2nd node (val = 2)'s neighbors are 1st node (val = 1) and 3rd node (val = 3).
3rd node (val = 3)'s neighbors are 2nd node (val = 2) and 4th node (val = 4).
4th node (val = 4)'s neighbors are 1st node (val = 1) and 3rd node (val = 3).
[예시2]
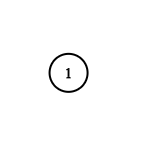
Input: adjList = [[]]
Output: [[]]
Explanation: Note that the input contains one empty list. The graph consists of only one node with val = 1 and it does not have any neighbors.
[예시3]
Input: adjList = []
Output: []
Explanation: This an empty graph, it does not have any nodes.
[제약]
- 그래프의 노드 수가 범위 내에 있다. [0, 100].
- 1 <= Node.val <= 100
- Node.val은 각 노드마다 고유하다.
- 그래프에는 반복되는 간선이나 자가 루프가 없다.
- 그래프는 연결되어 있으며 해당 노드부터 모든 노드를 방문할 수 있다.
[내가 생각한 방법]
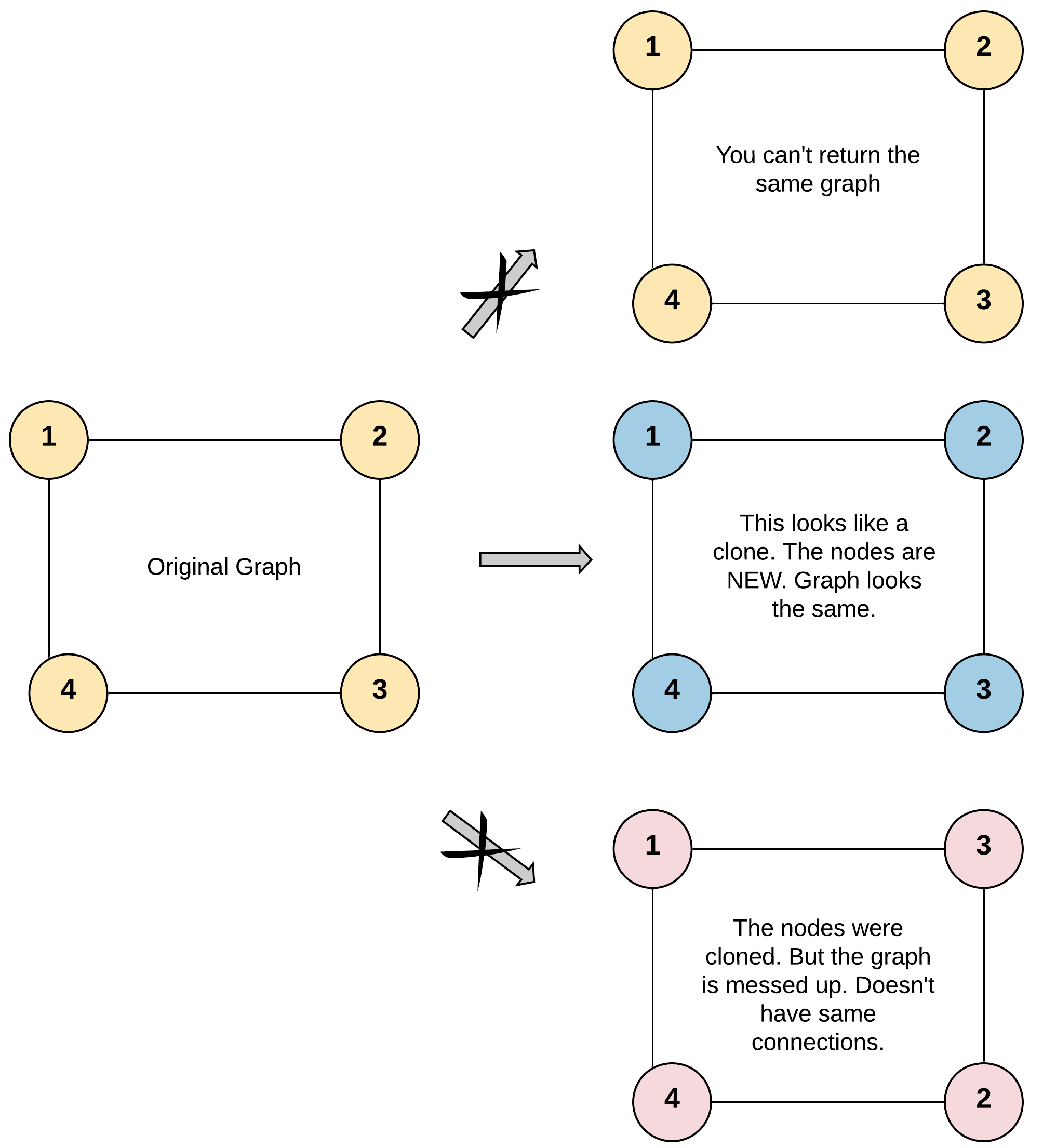
사실 이 문제는 '복제'가 가장 중요한 키워드인데 처음에 이 노드를 복제하는 방법에 대해 깊게 생각을 안했던 것 같다. 예시 그림을 토대로 다시 문제를 이해해보면
원본 그래프 A의 정점 노드가 4개이면, 복제 그래프 B의 정점 노드도 4개여야 하고
정점 노드의 간선 연결 관계, 인접한 노드도 동일하게 복제가 되어야 한다.
원본 그래프 A이면 안되고, 원본 그래프를 복제한 복제 그래프 B이어야 한다.
방문 여부를 추적하는 visited는 어차피 원본 그래프에도, 복제한 그래프에도 필요하므로 어차피 현재 노드를 체킹하면 함께 추적이 가능할 것 같았다.
[의사 코드]
복제노드 매핑 맵 선언;
노드 방문 stack 선언;
방문 여부 체크 visited 선언;
스택에 node 추가;
반복문(stack이 빌 때까지) {
현재 노드 = stack에서 꺼내온 값;
현재 노드가 방문했는지 여부 확인
방문x 경우, 방문했다고 추가하여 기록하기;
복제 노드 맵에 현재 노드가 포함되어있는지 확인
포함x 경우, 현재 노드의 복제본을 추가하기, 이때 현재 노드의 값으로 새로운 노드 생성;
현재 노드의 모든 이웃 노드 순회
복제 노드 맵에 이웃 노드가 포함되어있는지 확인
포함x 경우, 현재 이웃 노드의 복제본을 추가하기, 이때 현재 이웃 노드의 값으로 새로운 노드 생성;
현재 노드 복제본과 이웃 노드 복제본의 관계 연결 (간선 복제);
이웃 노드를 stack에 추가하여 다음 방문 노드로 설정;
}
반복문 끝나고, 모든 노드와 간선 연결 관계를 복제한 후에
시작 노드의 복제본을 반환 (복제 그래프의 시작 지점이기 때문);
}[완성 코드]
시간복잡도: O(V + E), V = 정점 수, E = 간선 수
class Solution {
public Node cloneGraph(Node node) {
if (node == null) return null;
Map<Node, Node> cloneGraph = new HashMap<>();
Stack<Node> stack = new Stack<>();
Set<Node> visited = new HashSet<>();
stack.add(node);
while (!stack.isEmpty()) {
Node current = stack.pop();
if (!visited.contains(current)) {
visited.add(current);
if (!cloneGraph.containsKey(current)) {
cloneGraph.put(current, new Node(current.val));
}
for (Node neighbor : current.neighbors) {
if (!cloneGraph.containsKey(neighbor)) {
cloneGraph.put(neighbor, new Node(neighbor.val));
}
cloneGraph.get(current).neighbors.add(cloneGraph.get(neighbor));
stack.push(neighbor);
}
}
}
return cloneGraph.get(node);
}
}1) node가 null인 경우는 null 반환 (빈 그래프인 경우 복제할 필요가 없으니까)
2) 원래 노드와 해당 노드의 복제본을 매핑하는 clonedNode를 HashMap으로 선언
3) 그래프 노드를 방문하기 위한 stack 선언
4) visited는 노드의 방문 여부를 추적하는 HashSet으로 선언
5) 시작 노드 node를 stack에 추가하고
6) stack이 빌 때까지 계속 반복
7) stack에서 노드를 하나 꺼내서 current 변수에 할당해줌. 현재 처리 중인 노드를 의미
8) 만약 visited에 현재 노드인 current가 없는 경우에는 처음 방문하는 경우이니까, visited에 current 현재 노드를 추가해서 방문되었음을 표시
9) clonedNode 맵에 현재 노드 current가 없는 경우 (해당하는 노드를 처음 복제하는 경우 확인)
10) clonedNode 맵에 현재 노드 current의 복제본을 추가함. 현재 노드의 값을 사용해서 새로운 노드를 생성해줌
11) 현재 노드 current의 모든 이웃 노드에 대한 반복문 실행
12) clonedNode 맵에 이웃노드 neighbor가 없는 경우 (해당하는 이웃 노드를 처음 복제하는 경우 확인)
13) clonedNode 맵에 이웃노드 neighbor의 복제본을 추가함. 현재 이웃 노드의 값을 사용해서 새로운 노드를 생성해줌
14) 현재 노드 current의 복제본과 이웃 노드 neighbor의 복제본을 연결함. 그래프의 간선 복제
15) 이웃 노드 neighbor를 stack에 추가하여 다음에 방문할 노드로 설정함
위 과정들을 계속 반복해서 그래프의 모든 노드와의 간선 연결 관계를 복제하고
모든 노드와 연결 관계의 복제가 끝나면, 시작 노드 node의 복제본을 반환함
(복제 그래프의 시작 지점이기 때문)
[회고]
항상 강의 볼 땐 흥미로운데 직접 코드로 작성하고 구현할 땐 막막한지..ㅎㅎ
노드 클래스로 DFS를 구현하려니까 어려웠다.
정말 기본적인 원리도 자주 들여다봐야 할 것 같고
꾸준하게 하는 것이 중요할 것 같다는 생각이 드는 요즘이다.
