
Index Range Scan
Index Range Scan은 B*Tree 인덱스의 가장 일반적이고 정상적인 형태의 엑세스 방식이다.
- 수직적 탐색 후 필요함 범위(Range)만 수평적 탐색한다.
- 인덱스 스캔 범위와 테이블 액세스 횟수를 줄이는 것이 성능 향상의 길이다.
Index Full Scan

Index Full Scan은 수직적 탐색 없이 오직 인덱스 리프 블록을 처음부터 끝까지 수평적으로 탐색하는 방식이다.
최적의 인덱스가 없을때, 차선으로 선택된다.
Index Full Scan 효용성
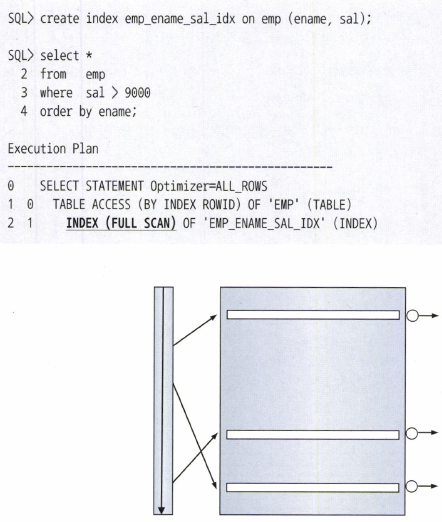
- 선두 컬럼이 조건절에 없으면 옵티마이저가 Index Full Scan을 고려한다.
- 만약 테이블이 고용량이면 인덱스 활용을 고려하지 않을 수 있다.
- 인덱스 스캔 단계에서 대부분 레코드를 필터링하고 아주 일부만 테이블을 액세스하는 상황이라면, 면적이 큰 테이블보다 인덱스를 스캔하는 쪽이 유리하다.
인덱스를 이용한 소트 연산 생략
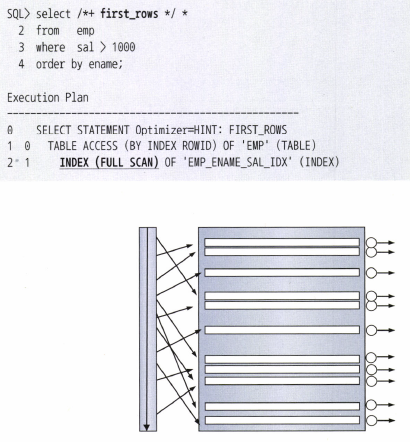
Index Full Scan 역시 Range Scan과 마찬가지로 인덱스 컬럼순으로 정렬된다.
즉, Sort Order By 연산을 생략할 수 있다. 그러한 목적으로도 사용한다.
옵티마이저는 Table Full Scan이 오히려 더 유리한 상황이 와도, Order By가 있다면 이 소트 연산을 생략하기 위해 Index Full Scan을 선택할 경우도 있다.
Index Unique Scan

Index Unique Scan은 수직적 탐색으로만 데이터를 찾는 방식으로, Unique 인덱스를 = (equal) 조건으로 탐색하는 경우이다.
Unique 인덱스가 존재하는 컬럼은 중복값 없이 입력되지 않게 DBMS가 정합성 관리해준다. 그래서 데이터를 = 조건으로 찾은 후 더이상 탐색이 필요없다.
- Unique 인덱스가 존재해도 Between, Like 등 범위 조건으로 검색하면 Index Range Scan을 한다.
- Unique 결합 인덱스도 검색 할 때, Index Range Scan을 사용한다.
Index Skip Scan
오라클은 9i버전에서 인덱스 선두 컬럼이 조건절에 없어도 인덱스를 활용하는 Index Skip Scan을 사용한다.
Index Skip Scan은 조건절에 빠진 인덱스 선두 컬럼의 Distinct Value 개수가 적고 후행 컬럼의 Distinct Value 갯수가 많을때 유용하다.
예시
Index Skip Scan이 동작하는 방식을 예시로 설명한다.
- Distinct Value 개수가 가장 적은 컬럼은 '성별'이다.
- Distinct Value 개수가 가장 많은 컬럼은 '고객번호'다.
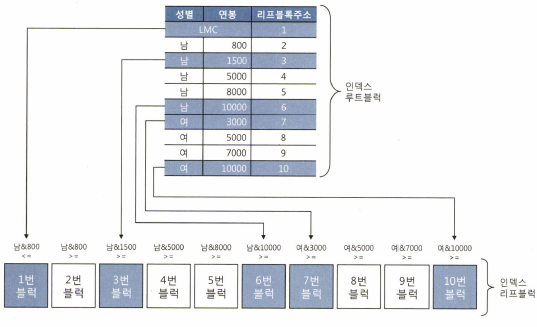
-- 스캔방식 유도를 위한 index_ss 힌트 사용.
select /*+ index_ss(사원 사원_IDX) */ *
from 사원
where 연봉 between 2000 and 4000- 성별 '남'보다 작은 값이 있을까봐 일단 첫번때 리프 블록 액세스
- 연봉 >= 800인 2번째 리프 블록은 Skip
- 연봉 >= 1500인 3번째 리프 블록 다음이 연봉 >= 5000이기 때문에 조건을 만족하는 값이 있을 가능성이 있어 3번째 리프 블록 액세스
- 연봉 >= 5000인 4번째 리프 블록은 애초에 조건에 만족하지 않기 때문에 Skip
- 5번째 리프 블록 또한 같은 이유로 Skip
- 6번째 리프 블록은 연봉 >= 10000이라 skip 될것 같지만, 다음 블록에서 성별 조건이 바뀌어서 일단 액세스
- 7번 블록은 성별 상관없이 연봉 >= 3000 이고, 다음 레코드는 연봉 >= 5000이기 때문에 액세스
- 8번 ~ 9번 블록은 연봉 >= 5000, 연봉 >= 7000 이기 때문에 조건에 만족하지 않아 Skip
- 10번 블록 또한 연봉 >= 10000으로 조건에 만족하지 않지만, 다음 성별이 있을수 있으니 일단 액세스
Index Skip Scan이 작동하기 위한 조건
인덱스 선두 컬럼이 없을때만 Index Skip Scan이 아니다.
인덱스에 컬럼이 3개일 경우 => 일별업종별거래_PK : 업종유형코드 + 업종코드 + 기준일자
- 선두 컬럼이 조건절에 있고, 중간 컬럼이 조건절에 없어도 Index Skip Scan을 사용할 수 있다.
- Distinct Value 개수가 적은 두 개의 선두컬럼이 다 조건절에 없어도 Index Skip Scan 사용할 수 있다.
- 선두 컬럼이 부등호, BETWEEN, LIKE 같은 범위 검색 조건일때도 Index Skip Scan 사용할 수 있다.
인덱스는 기본적으로 최적의 Index Range Scan을 목표로 설계해야 한다.
만약 수행 횟수가 적은 SQL을 위해 인덱스를 추가하는 것이 비효율적일 때, 이들 스캔 방식을 차선책으로 활용하는 전략이 바람직하다.
Index Fast Full Scan
Index Fast Full Scan은 Index Full Scan보다 빠르다.
그 이유는, 논리적인 인덱스 트리 구조를 무시하고 인덱스 세그먼트 전체를 Multiblock I/O 방식으로 스캔하기 때문이다.
인덱스의 논리적 구조와 물리적 순서에 따라 재배치된 구조의 차이
인덱스의 논리적 구조
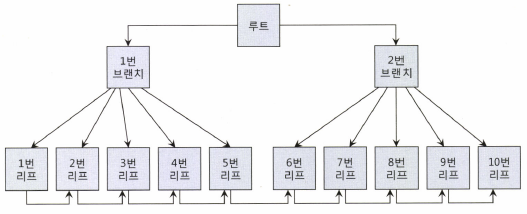
Index Full Scan은 인덱스의 논리적 구조를 따라 루트 → 브랜치1 → 1 → 2 → 3 → 4 → 5 → 6 → 7 → 8 → 9 → 10번 순으로 블록을 읽어들인다.
물리적 순서에 따라 재배치된 구조
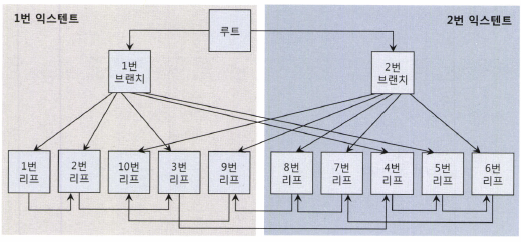
Index Fast Full Scan은 물리적으로 디스크에 저장된 순서대로 인덱스 리프 블록들을 읽어들인다.
Multiblock I/O 방식으로 왼쪽 익스텐트에서 1 → 2 → 10 → 3 → 9번 순으로 읽고,
그 다음 오른쪽 익스텐트에서 8 → 7 → 4 → 5 → 6번 순으로 읽는다.
루트와 두 개의 브랜치 블록도 읽지만 필요 없는 블록이므로 버린다.
Index Fast Full Scan 특징
- Multiblock I/O 방식을 사용한다.
- 디스크로부터 대량의 인덱스 블록을 읽어야 할 때 큰 효과 발휘한다.
- 인덱스 키 순서대로 정렬되지 않다. (연결 리스트 구조를 무시해서 결과집합이 인덱스 키 순서대로 정렬되지 않음)
- 쿼리에 사용한 컬럼이 모두 인덱스에 포함돼 있을 때 사용 가능함.
- 인덱스가 파티션 돼 있지 않더라도 병렬 쿼리가 가능
- 병렬 쿼리 시에는 Direct I/O방식 사용하기 때문에 I/O 속도가 더 빨라짐
| Index Full Scan | Index Fast Full Scan |
|---|---|
| 1. 인덱스 구조를 따라 스캔 2. 결과집합 순서 보장 3. Single Block I/O 4. (파티션 돼 있지 않다면) 병렬스캔 불가 5. 인덱스에 포함되지 않은 컬럼 조회 시에도 사용 가능 | 1. 세그먼트 전체를 스캔 2. 결과집합 순서 보장 안 됨 3. Multiblock I/O 4. 병렬스캔 가능 5. 인덱스에 포함된 컬럼으로만 조회할 때 사용 가능 |
Index Range Scan Descending
Index Range Scan과 기본적으로 동일 스캔방식이나, 인덱스를 뒤에서 앞으로 스캔하기 때문에 내림차순으로 결과집합을 얻는다.

Order By Desc가 있으면 옵티마이저는 Index Range Scan Descending을 실행Order By Desc없이 "옵티마이저 힌트"를 이용하여 Index Range Scan Descending 실행 가능- MAX 함수를 사용하면 인덱스 범위 뒤에서부터 읽는것이 빠르기 때문에, Index Range Scan Descending 사용.
