
파티션을 쓰면 대량 추가 변경 삭제 작업을 빠르게 처리할 수 있다.
테이블 파티션
파티셔닝은 테이블 또는 인덱스 데이터를 특정 컬럼 값에 따라 별도 세그먼트에 나눠서 저장하는 것이다.
파티션이 필요한 이유
- 관리적 측면 : 파티션 단위 백업, 추가, 삭제, 변경 ⇒ 가용성 향상
- 성능적 측면 : 파티션 단위 조회 및 DML, 경합 또는 부하 분산
파티션에는 Range, Hash, List 세 종류가 있다.
Range 파티션
가장 기초적인 방식의 파티션.
주로 날짜 컬럼을 기준으로 파티셔닝한다.
create table 주문(주문번호 number, 주문일자 varchar2(8), 고객id varchar2(5)
, 배송일자 varchar2(8, 주문금액 number, … )
partition by range(주문일자) (
partition p2017_q1 values less than (‘20170401’)
, partition p2017_q2 values less than (‘20170701’)
, partition p2017_q3 values less than (‘20171001’)
, partition p2017_q4 values less than (‘20180101’)
, partition p2018_q1 values less than (‘20180401’)
, partition p9999_mx values less than (maxvalue) --> 주문일자 >= '20180401'
);위와 같은 파티션 테이블에 값을 입력하면 각 레코드를 파티션 키 값에 따라 분할 저장하고, 읽을때도 검색조건을 만족하는 파티션만 골라 읽어줄 수 있어 이력성 데이터를 Full Scan 방식으로 조회할 때 성능을 크게 향상시킨다.
부관주기 정책에 따라 과거 데이터가 저장된 파티션만 백업하고 삭제하는 등 데이터 관리 작업을 효율적이고 빠르게 수행할 수 있는 장점도 있음.
테이블 파티션에 대한 SQL 성능 향상 원리
파티션 Pruning이 답이다.
파티션 Pruning은 SQL 하드파싱이나 실행 시점에 조건절을 분석해 읽지 않아도 되는 파티션 세그먼트를 액세스 대상에서 제외하는 기능이다.
select * from 주문 where 주문일자 >= '20120401' and 주문일자 <= '20120630'위 조건절에 해당하는 데이터는 1200만건중 25%에 해당하는 300만건이라고 치면,
인덱스 타고 랜덤 액세스하면 더 느리다. 그런데 테이블 전체 스캔은 사이즈가 너무커 부담이다.
이때 테이블 파티션을 사용하면 Full Scan 해도 전체가 아닌 일부라서 일부 파티션 세그먼트만 읽고 멈출 수 있다.
파티션과 병렬 처리가 만나면 그 효과는 배가 된다.
해시 파티션
- 파티션 키 값을 해시 함수에 입력해서 반환받은 값이 같은 데이터를 같은 세그먼트에 저장하는 방식
- 파티션 개수만 사용자가 결정하고 데이터를 분산하는 알고리즘은 오라클 내부 해시함수가 결정한다.
해시 파티션은 고객ID처럼 변별력이 좋고 데이터 분포가 고른 컬럼을 파티션 기준으로 선정해야 효과적이다. 아래는 고객ID 기준으로 고객 테이블을 해시 파티셔닝하는 방법을 예시한다.
create table 고객(
고객id varchar2(5)
, 고객명 varchar2(10)
, …
)
partition by hash(고객id) partitions 4;- 검색할 때는 조건절 비교 값(상수 또는 변수)에 똑 같은 해시 함수를 적용함으로써 읽을 파티션을 결정한다.
- 해시 알고리즘 특성상 등치(=) 조건 또는 IN-List 조건으로 검색할 때만 파티션 Prning이 작동한다.
리스트 파티션
- 리스트 파티션은, 사용자가 정의한 그룹핑 기준에 따라 데이터를 분할 저장하는 방식
아래는 지역분류 기준으로 인터넷매물 테이블을 리스트 파티셔닝하는 방법을 예시한다.
create table 인터넷매물(
물건코드 varchar2(5)
, 지역분류 varchar2(4)
, …
)
partition by list(지역분류) (
partition p_지역1 values (‘서울’)
, partition p_지역2 values (‘경기’. ‘인천’)
, partition p_지역3 values (‘부산’, ‘대구’, ‘대전’, ‘광주’)
, partition p_기타 values (default) -> 기타 지역
);Range 파티션에선 값의 순서에 따라 저장할 파티션이 결정
하지만 리스트 파티션은 순서와 상관없이 불연속적인 값의 목록에 의해 결정된다.
해시 파티션은 오라클이 정한 해시 알고리즘에 따라 임의로 분할함.
반면 리스트 파티션은 사용자가 정의한 논리적인 그룹에 따라 분할함.
💡 업무적인 친화도에 따라 그룹핑 기준을 정하되, 될 수 있으면 각 파티션에 값이 고르게 분산되도록 해야 한다.
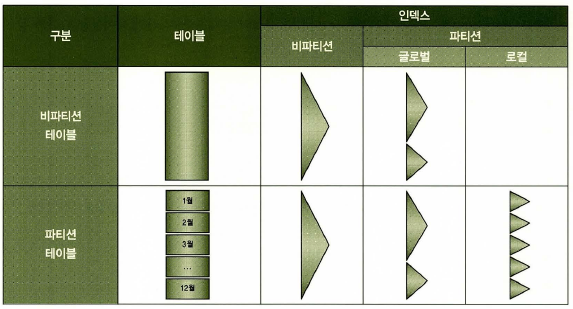
인덱스 파티션
인덱스 파티션은 테이블 파티션과 맞물려 다양한 구성이 있다.
테이블 파티션 구성
- 비파티션 테이블
- 파티션 테이블
인덱스 파티션 구성
- 로컬 파티션 인덱스
- 글로벌 파티션 인덱스
- 비파티션 인덱스
로컬 파티션 인덱스
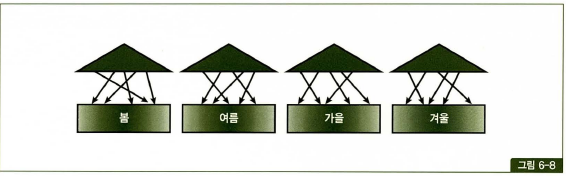
- 로컬 파티션 인덱스는 별도 색인을 만드는 것과 같음. 줄여서 “로컬 인덱스” 라고도 함.
- 각 테이블 파티션과 인덱스 파티션이 서로 1:1 대응 관계가 되도록 오라클이 자동 관리 파티션 인덱스이다.
- 로컬 파티션 인덱스를 만들때는 CREATE INDEX 문 뒤에
LOCAL옵션을 추가하면 된다.
create index 주문_x01 on 주문 (주문일자, 주문금액) LOCAL;
create index 주문_x02 on 주문 (고객ID, 주문일자) LOCAL;- 인덱스 파티션은 테이블 파티션 속성을 그대로 상속받는다.
- 테이블 파티션 키가 주문 일자면 인덱스 파티션키도 주문 일자가 됨.
- 테이블 파티션 구성을 변경(add, drop, exchange 등)하더라도 인덱스 재생성 할 필요가 없음.
- 변경작업이 순식간에 끝나고 피크 시간대만 피하면 서비스 중단하지 않고도 작업가능
- 로컬 인덱스의 장점은 관리 편리성
글로벌 파티션 인덱스
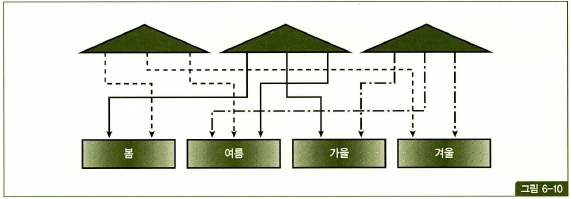
- 파티션을 테이블과 다르게 구성한 인덱스
- 테이블 파티션과 독립적인 구성(파티션 키, 파티션 기준값 정의)을 갖는다.
- (=같은말) 파티션 유형이 다르거나, 파티션 키가 다르거나, 파티션 기준값 정의가 다른 경우임.
- 비 파티션 테이블이어도 인덱스는 파티셔닝 가능.
- 만들때는 CREATE INDEX 문 뒤에
GLOBAL옵션을 추가하고 파티션을 정의하면 된다.
create index 주문_x03 on 주문 (주문금액, 주문일자) GLOBAL
partition by range(주문금액) (
partition P_01 values less than (100000)
partition P_MX values less than (MAXVALUE) --> 주문금액 >= 100000
);- 글로벌 파티션 인덱스는 테이블 파티션 구성을 변경하면 Unusable 되어서 인덱스를 바로 재생성 해줘야 함. 그동안 해당 테이블을 사용하는 서비스는 중단해야 한다.
- 글로벌 파티션 인덱스를 로컬 인덱스처럼 구성해도 파티션 옵션은 글로벌이라서 오라클이 관리해주지 않는다.
비파티션 인덱스
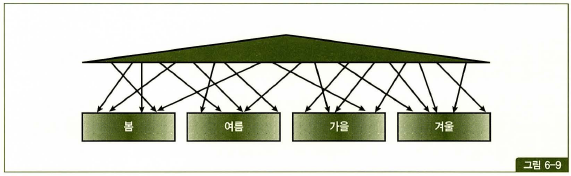
- 파티셔닝 하지 않은 인덱스
- 만드는 방법은 그냥 CREATE INDEX 한다.
- 그림과 같이 여러 테이블 파티션을 가리킨다. 그래서 ‘글로벌 비파티션 인덱스’라고도 부름.
- 비파티션 인덱스는 테이블 구성이 변경되는 순간 Unusable 상태로 바뀌어서 인덱스를 재생성해줘야 한다. 그동안 해당 테이블을 사용하는 서비스는 중단해야 한다.
Prefixed vs Nonprefixed
- Prefixed : 인덱스 파티션 키 컬럼이 인덱스 키 컬럼 왼쪽 선두에 위치한다.
- Nonprefixed : 인덱스 파티션 키 컬럼이 인덱스 키 컬럼 왼쪽 선두에 위치하지 않는다. 파티션 키가 인덱스 컬럼에 아에 속하지 않을때도 있음.
글로벌 파티션 인덱스는 Prefixed만 지원한다. 로컬 파티션 인덱스는 Prefixed, Nonprefixed 다 가능하다.
그래서 비파티션을 포함해 4가지 유형으로 정리할 수 있다.
- 로컬 Prefixed 파티션 인덱스
- 로컬 Nonprefixed 파티션 인덱스
- 글로벌 Prefix 파티션 인덱스
- 비파티션 인덱스
중요한 인덱스 파티션 제약
Unique 인덱스를 파티셔닝 하려면, 파티션 키가 모두 인덱스 구성 컬럼이여야 한다.
- 파티션 키가 인덱스 컬럼에 포함되어야 하는 조건은 DML 성능 보장을 위해 당연히 있어야 할 제약조건임.
- 파티션 키 조건 없이 PK 인덱스로 액세스 하는 수많은 쿼리 성능을 위해 필요한 제약조건이다.
- 이 제약으로 인해 PK 인덱스를 로컬 파티셔닝하지 못하면, 파티션 Drop, Truncate, Exchange, Split, Merge 같은 파티션 구조 변경 작업도 쉽지 않음. (Unusable 되기 때문)
- 서비스 중단 없이 파티션 구조를 빠르게 변경하려면 PK를 포함한 모든 인덱스는 로컬 파티션 인덱스여야 한다.
파티션을 활용한 대량 UPDATE 튜닝
인덱스는 DML 성능에 큰 영향을 미침. 그래서 인덱스 없이 대량의 데이터 작업 후, 인덱스 생성이 더 빠르고 그런 방법을 많이 쓴다.
파티션 Exchange를 통한 대량 데이터 변경
테이블이 파티셔닝이 되어있고, 인덱스도 로컬 파티션이라면, 수정된 값을 갖는 임시 세그먼트를 만들어 원본 파티션과 바꿔치기 하는 방법을 사용한다.
- 임시 테이블을 생성, nologging 모드로 생성
create table 거래_t
nologging
as
select * from 거래 where 1 = 2;- 거래 데이터를 읽어 임시 테이블에 입력하면서 상태코드 값을 수정한다.
insert /*+ append */ into 거래_t
select 고객번호, 거래일자, 거래순번 ...
,(case when 상태코드 <> 'ZZZ' then 'ZZZ' else 상태코드 end) 상태코드
from 거래
where 거래일자 < '20150101';- 임시테이블에 원본 테이블과 같은 구조로 인덱스 생성 nologging 모드
- 파티션과 임시 파티션을 Exchange 한다.
alter table 거래
exchange partition p201412 with table 거래_t
including indexes without validation;- 임시 테이블 Drop
- nologging 한 파티션 logging 모드 전환
파티션을 활용한 대량 DELETE 튜닝
DELETE가 느린 이유는 여러 부수적인 작업을 수반해야해서 느리다.
특히 인덱스 레코드를 찾아 삭제하는 작업 부담이 크다.
- 테이블 레코드 삭제
- 테이블 레코드 삭제 Undo Logging
- 테이블 레코드 삭제 Redo Logging
- 인덱스 레코드 삭제
- 인덱스 레코드 삭제 Undo Logging
- 인덱스 레코드 삭제 Redo Logging
- Undo에 대한 Redo Logging
파티션 Drop을 이용한 대량 데이터 삭제
삭제 조건절 컬럼 기준으로 파티셔닝 되어 있고, 로컬 파티션이라면 1줄로 대량 데이터를 삭제할 수 있다.
alter table 거래 drop partition p201412;
-- 오라클 11g 버전 : 대상 파티션 지정
alter table 거래 drop partition for('20141201');파티션 Truncate를 이용한 대량 데이터 삭제
거래일자 조건에 해당하는 데이터를 일괄 삭제하지 하지 않고 다른
- 임시 테이블을 생성하고 남길 데이터만 복제
- 삭제 대상 테이블 파티션을 Truncate
- 임시 테이블에 복제해둔 데이터를 원본 테이블에 입력
- 임시 테이블 Drop
서비스 중단 없이 파티션 Drop, Turncate 하기 위한 조건
- 파티션 키와 커팅 기준 컬럼이 일치해야 함.
- ex) 파티션 키와 커팅 기준 컬럼이 모두 ‘신청일자’
- 파티션 단위가 커팅 주기가 일치해야 함.
- ex) 월 단위 파티션을 월 주기로 커팅
- 모든 인덱스가 로컬 파티션 인덱스여야 함.
- ex) 파티션 키는 ‘신청일자’, PK는 ‘신청일자 + 신청순번’
- PK인덱스는 지금처럼 삭제 기준 컬럼이 인덱스 구성 컬럼이어야 로컬 파티셔닝 가능
파티션을 활용한 대량 INSERT 튜닝
비파티션 테이블일 때
비파티션 테이블에 손익분기점 넘는 대량 데이터 INSERT 하려면, 인덱스 Unusable하고 재생성하는 방식이 빠를 수 있음.
- 테이블을 nologging 모드
- 인덱스 Unusable 상태로 전환
- 대량 데이터 입력
- 인덱스 재생성
- logging 모드로 전환
파티션 테이블일 때
테이블이 파티셔닝 되어 있고, 인덱스도 로컬 파티션이면 파티션 단위로 인덱스 재생성 할 수 있다.
- 작업 대상 테이블을 nologging 모드
- 작업 대상 테이블 파티션과 매칭되는 인덱스 파티션을 Unusable 상태로 전환
- 대량 데이터 입력
- 인덱스 파티션 재생성
- 작업 파티션을 logging 모드로 전환
