Architectural Design
Introduction
요구사항 명세가 완벽하게 정의되었다면, 이후에는 무엇을 해야할까?
Use Case는 입력에 따른 반응을 기반으로 한 기술이다. 시스템의 내부는 요구사항 명세가 명확해져도 블랙박스의 형태를 가진다. 고로 개발자인 우리는 블랙박스를 화이트박스로 바꾸는 절차를 거쳐야 하고, 이를 위해 설계(architecture)를 해야한다.
Architectural Design이란?
아키텍쳐 디자인은 Software System이 어떻게 구성되는지 이해하고 그 System의 구조를 전체적으로 디자인하는 것을 말한다. 개발 요구사항과 디자인 사이에서 중요한 역할을 하며, 시스템의 주요 구조적 구성요소와 관계 사이에서 정의한다.
시스템의 세가지 핵심은 1) 기능 (요구 분석에서 결정), 2) 구조 (아키텍처 디자인, 클래스 다이어그램) , 3) 행위 (시퀀스 다이어그램, State 다이어그램) 으로 정의할 수 있다.
설계는 Top-Down 방식으로 진행되고, 점점 세분화되게 설계한다. 컴포넌트를 구성하면서 구조가 짜이면 각 컴포넌트 간의 행위를 정의한다. 아키텍처 디자인은 디자인과 요구 엔지니어링 사이를 연결하는 '링크'이고, 아키텍처 디자인의 장점은 이해 당사자 사이의 소통을 쉽게해주고 큰 규모의 재사용이 가능하며, 시스템 분석이 쉬워지는 장점을 가진다.
Architectural Patterns
시스템이 서로 통신하는 구성 요소들의 집합으로 어떻게 구성되는지 설명한다. 이러한 아키텍처를 명시적으로 설계함에 있어서 장점은 아래와 같다. 아키텍처 패턴은 지식을 표현하고 공유하고 재사용하는 일종의 수단이다. 다양한 환경에서 시도되며 디자인 관행을 양식화해서 설명한 것으로 볼 수 있다. 주로 이런 Pattern은 표나 그래프의 형식으로 표현한다.
MVC
MVC 패턴은 Software 디자인 패턴의 일종으로 Model, View, Controller로 분리하여 유지보수성과 확장성을 높이는 방식을 말한다.
간단한 구조 형태로 정의된 이 패턴의 로직은 User가 Controller를 통해서 조작을 하면 Model을 통해서 데이터를 가지요고 View가 그 정보를 바탕으로 시각적인 요소로 User에게 전달한다. 간결하게 보자면 아래와 같은 구조로 형성된다.
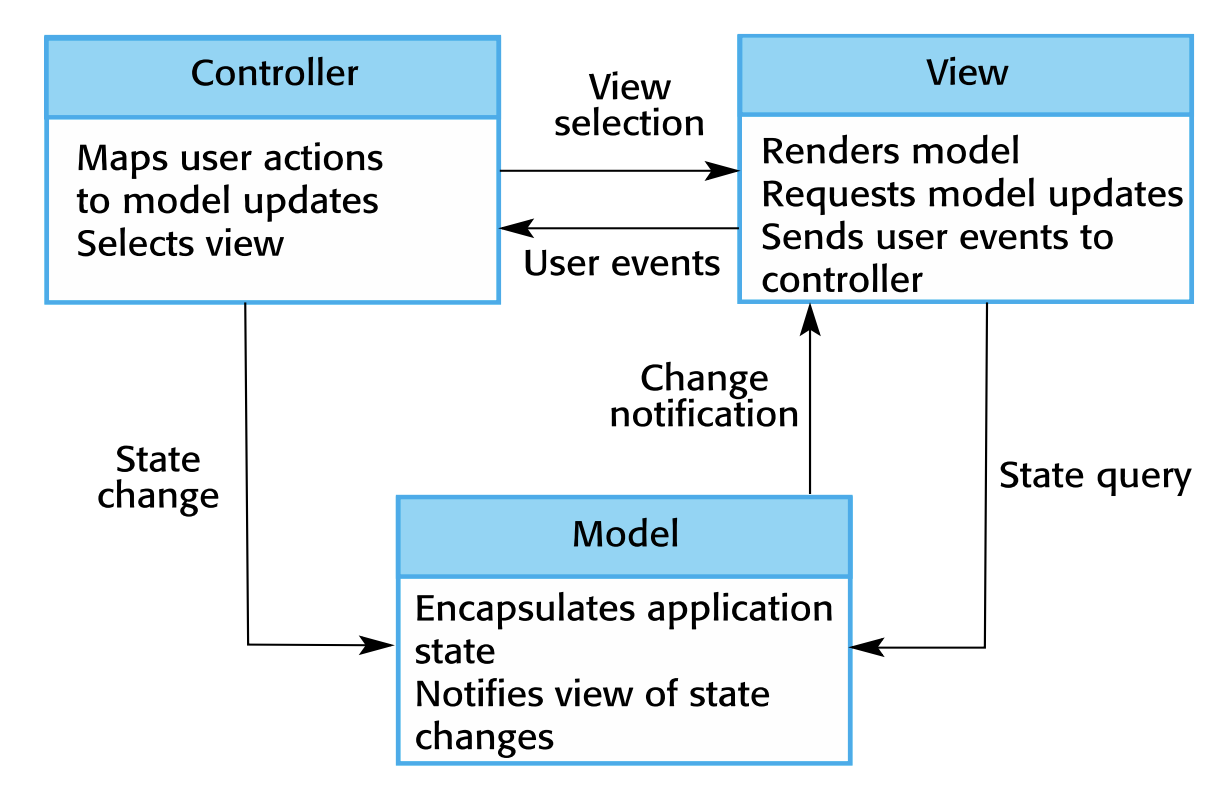
MVC 패턴은 시스템 데이터의 상호작용과 presentation을 분리한다. MVC의 장점은 데이터와 표현 방식 간의 독립적인 변화를 허용하고 그 반대의 경우도 가능하다는 것이다. 모델의 데이터가 변화하면 여러 뷰에 동시에 업데이트가 가능해 GUI 기반 시스템이나 웹 애플리케이션에서는 거의 표준처럼 사용된다.
Layered Architecture
시스템을 여러 계층으로 구성하고, 하위 계층이 바로 위 상위 계층에 코어 서비스를 제공하는 구조이다. 시스템은 최하위 계층부터 서비스를 제공하는 구조까지 계층이 구성되어있다. 계층적인 구조답게 interface가 변경되면 인접 계층에만 영향을 미친다. interface에서 여러 계층을 통해 최하위 계층에 존재하는 OS, DataBase까지 계층을 구성해서 운영한다
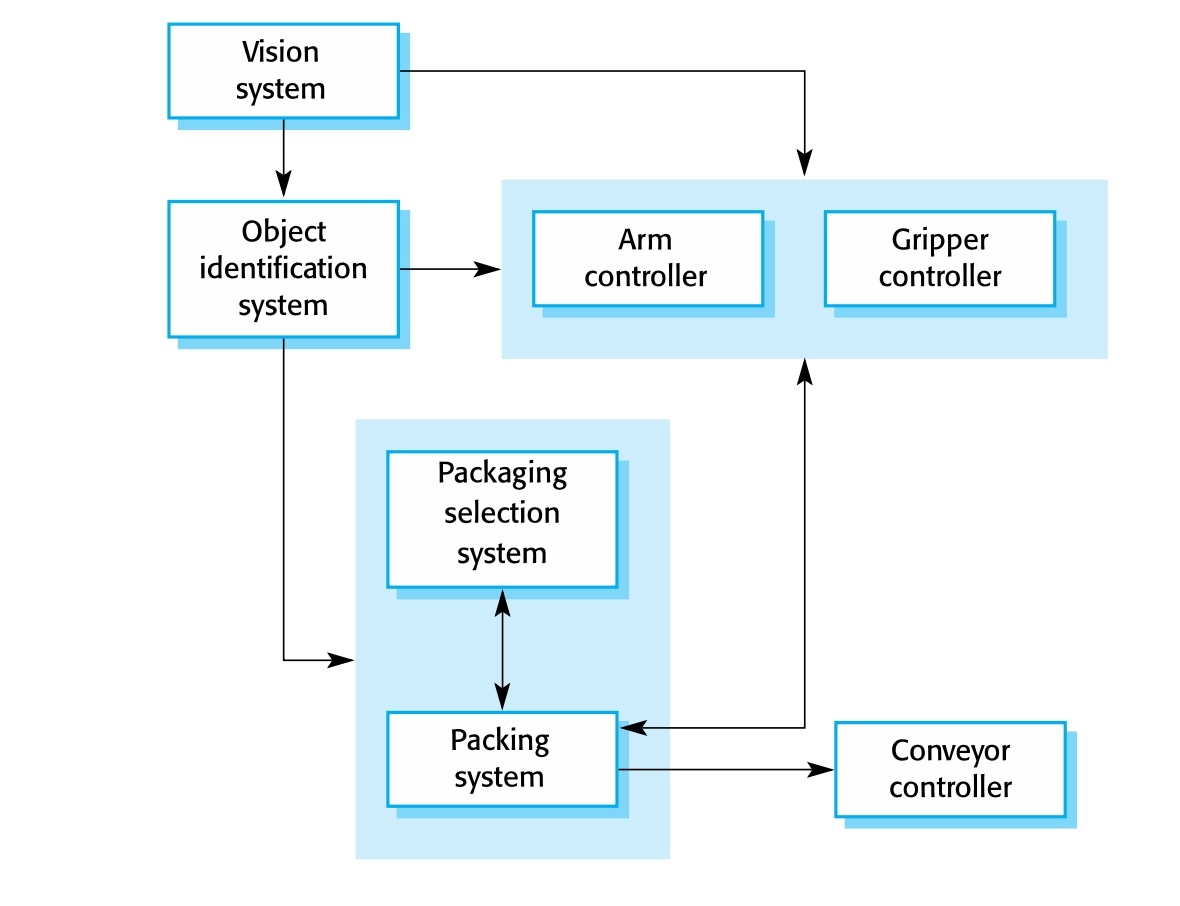
기존 시스템 위에 새로운 기능을 구축하거나 여러 팀에 개발이 분산되고 각 팀이 하나의 계층을 책임지는 경우에 주로 사용하며, 장점으로 인터페이스가 유지되면 전체 계층의 교체가 가능하고 각 계층에 중복 기능을 제공할 수 있다.
가장 단순한 방식인 만큼 단점도 명확히 존재하는데, 첫번째로 층간분리가 명확하게 발생하지 않는다는 점이다. 이에 대한 구현의 난이도 또한 높다. 둘째로 서비스의 요청에 따라 해석 단계가 여러 차례 존재하기에 성능 문제가 발생할 수 있다. 이로 인해 불필요한 계층간 이동이 발생하여 성능저하가 발생하게 된다.
Repository Architecture
모든 데이터가 중앙 저장소에 관리되며, 시스템의 서브 컴포넌트들은 서로 직접 통신하지 않고 오직 중앙 저장소를 거쳐 데이터를 주고 받는다.
데이터를 교환하는 일종의 보조 시스템의 역할을 담당한다. Repository는 2가지 일을 수행하는데 그 일들은 아래와 같다. 첫째로 공유 데이터는 중앙 DB 또는 repository에 저장되며, 모든 하위 시스템에서 접근할 수 있습니다. 둘째로 각 하위 시스템은 자체 데이터베이스를 유지하고 데이터를 다른 하위 시스템에 전달한다.
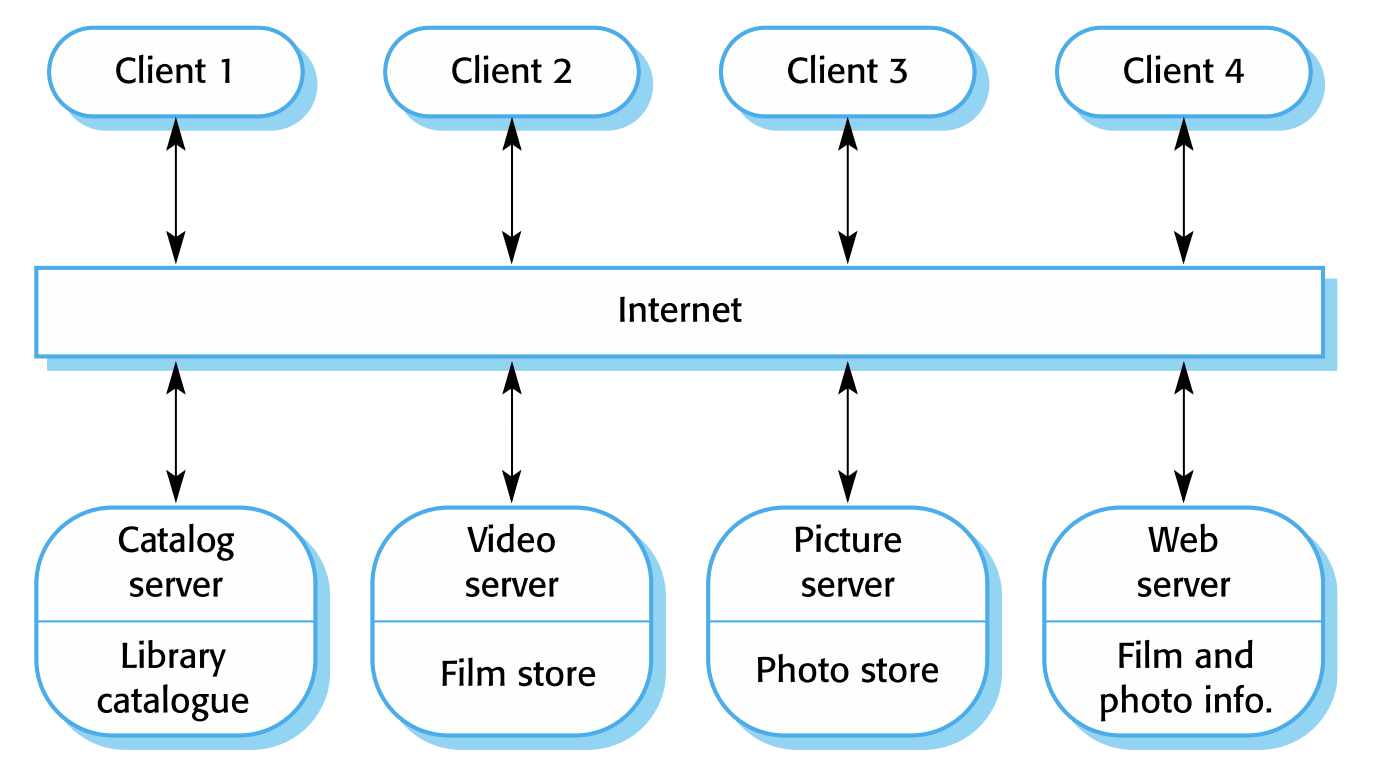
장기간 대량 정보가 생성되는 시스템에서 주로 사용하고, 컴포넌트가 모두 독립적이어서 개발하기 편하고 데이터를 일관성 있게 관리할 수 있다는 장점이 있지만, 저장소가 문제가 생기면 전체 시스템에 문제가 생긴다는 점과 모든 통신을 저장소를 통해 구성하는 것이 비효율적인 단점이 존재하기도 한다.
Client-Server Architecture
독립적인 특정 서비스를 제공하는 '서버'의 집합과 네트워크를 통해 서버들에 접속하는 서비스를 이용하는 '클라이언트' 집합으로 분산된 모델이다. 서버 1개와 다수 클라이언트가 소통하는 구조로, 여러 컴포넌트에 걸쳐 분산을 보이는 분산시스템의 모델이다.
주로 공유 DB의 데이터를 다양한 위치에서 접근할 때 사용하고, 시스템의 부하가 가변적일 때에도 적용할 수 있다. 서버를 네트워크 상에 분산시키거나 복제해 부하를 조절할 수 있다. 하지만 시스템의 성능이 네트워크 상태에 의존하기에 예측이 어렵고 특정 서버가 다운되거나 DoS공격을 받게되면, 서비스가 중단될 위험이 있다.
Pipe And Filter Architecture
우리가 흔히 아는 Unix Shell이 이 Pipe and filter 구조로 만들어졌다. 입력 데이터를 각 컴포넌트(필터)가 한가지 형태의 데이터 변환으로 처리한 이후 Pipe를 통해 다음 컴포넌트로 넘겨주는 구조이다. interactive한 시스템에는 적합하지 않지만 순차적으로 처리하는 경우에는 주로 사용할 수 있다.
하나의 컴포넌트에서 다른 컴포넌트로의 데이터 흐름을 말한다. 주로 흔히 데이터 처리 기반 애플리케이션에서 사용된다. 하지만 데이터 전송 형식은 통신하는 변환 간에 합의되야한다는 점이 필요하다.(우리는 이것을 프로토콜이라고 부른다)
워크플로우 비즈니스 프로세스에 적합하며, 변환 단계들이 병렬 처리(Parallelism)가 가능해 효율을 크게 높일 수 있다. 다만 컴포넌트 간에 호환되는 데이터 포맷을 맞춰야하는 오버헤드가 발생한다.
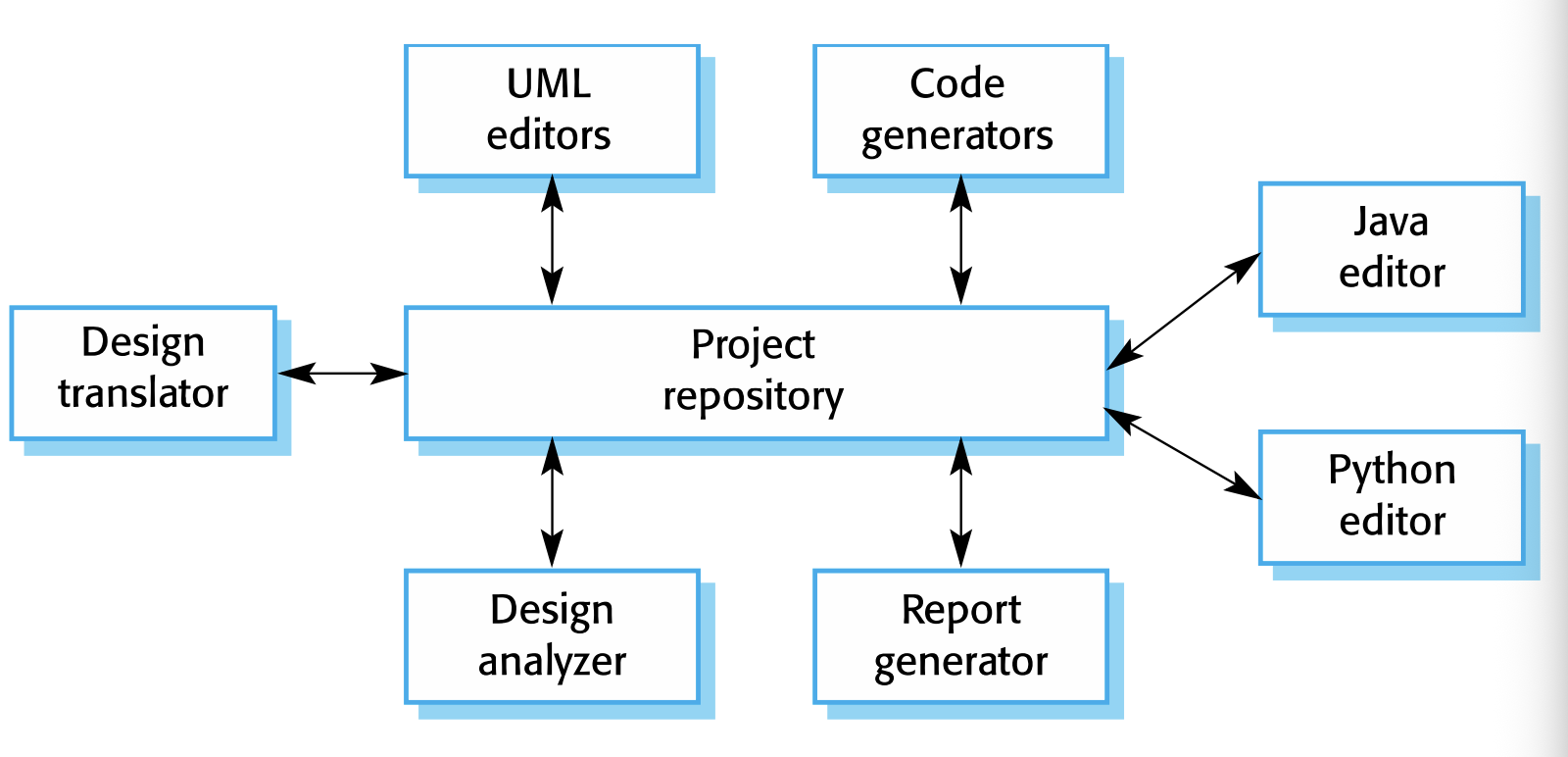
Application Architecture
도메인마다 사용하는 어플리케이션 구조가 비슷해 이를 정리한 구조이다. 주로 조직의 요구사항을 충족하도록 설계한다. 비슷한 구조를 중심으로 특정 요구사항을 충족하는 시스템을 구축하기 위해 구성 및 적용할 수 있는 SW System 유형의 아키텍처이다. 크게 두가지의 종류로 표현된다.
Transaction processing systems
우리가 흔히 아는 웹 정보 시스템(전자상거래, 예약 시스템, ATM 등)으로, 주로 데이터베이스와의 상호작용을 다룬다.
가장 밑에 DB가 깔리고, 그 위에 비즈니스 로직, UI가 올라가는 형태를 취한다. 데이터베이스에서 정보를 검색하거나 데이터베이스를 업데이트하려는 사용자의 비동기적 요청을 처리한다.
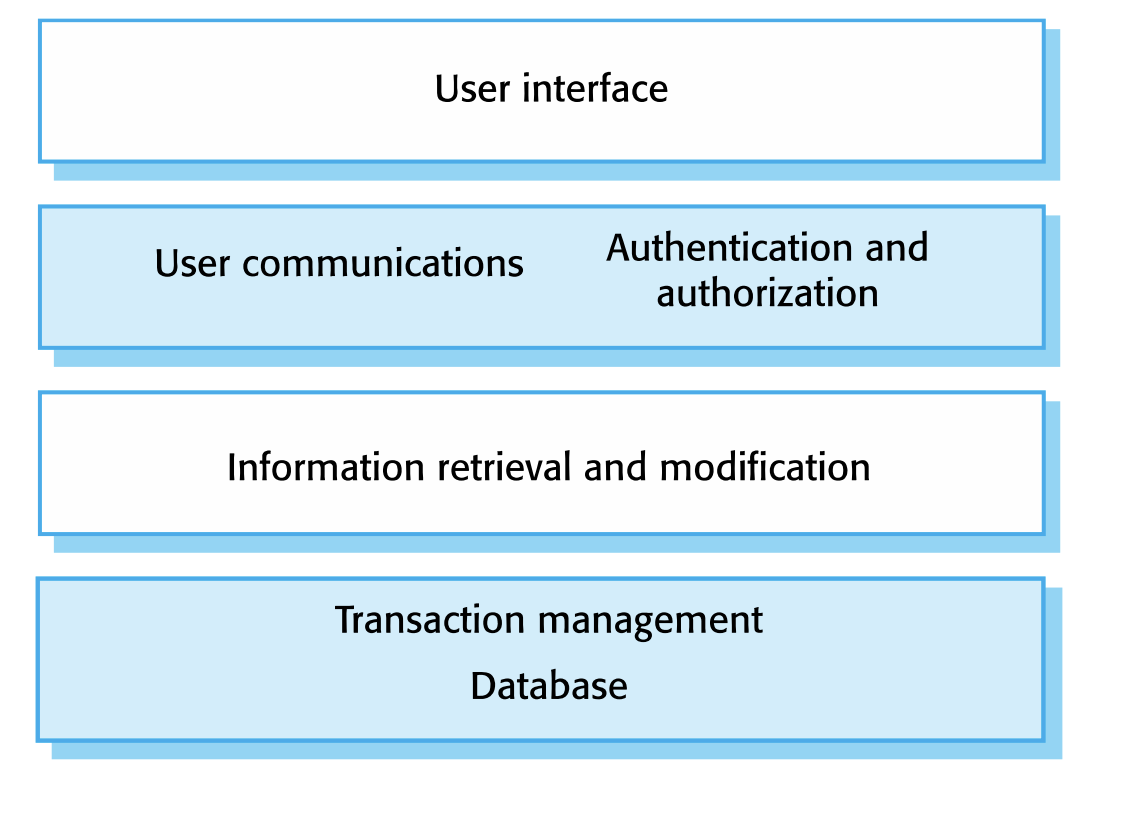
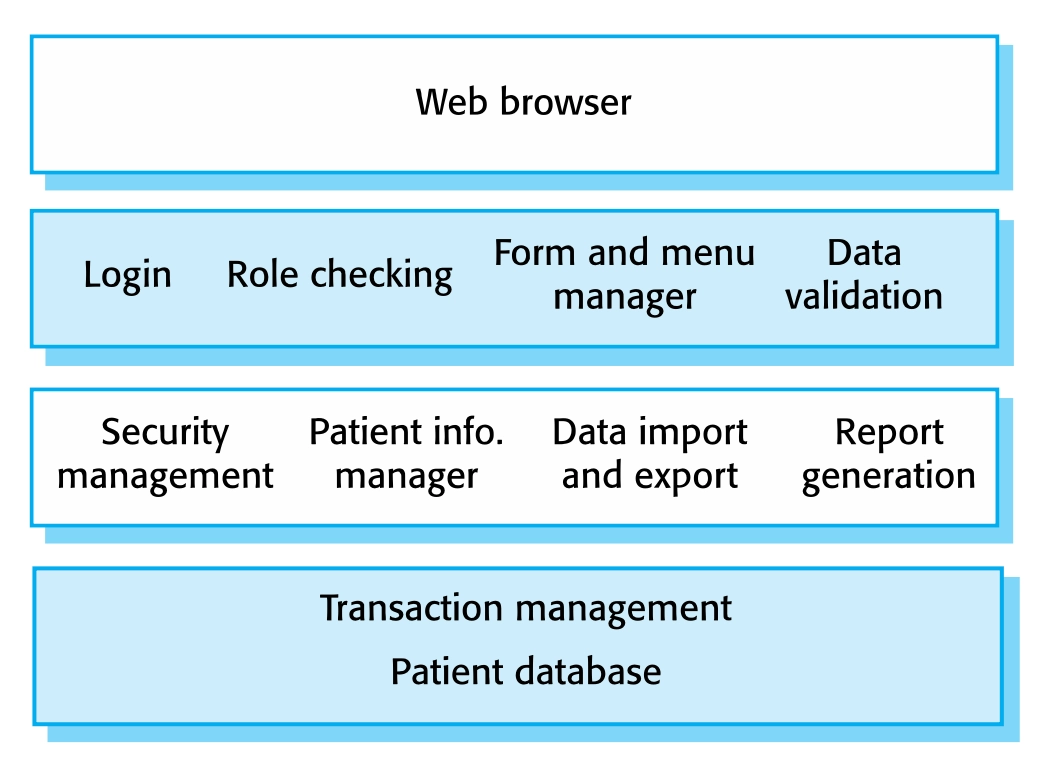
Information System Architecture
정보 시스템은 계층형 아키텍처로 구성될 수 있는 보편적인 아키텍처이다. 계층에는 사용자 인터페이스, 사용자 통신, 정보 검색, 시스템 데이터베이스를 포함한다.
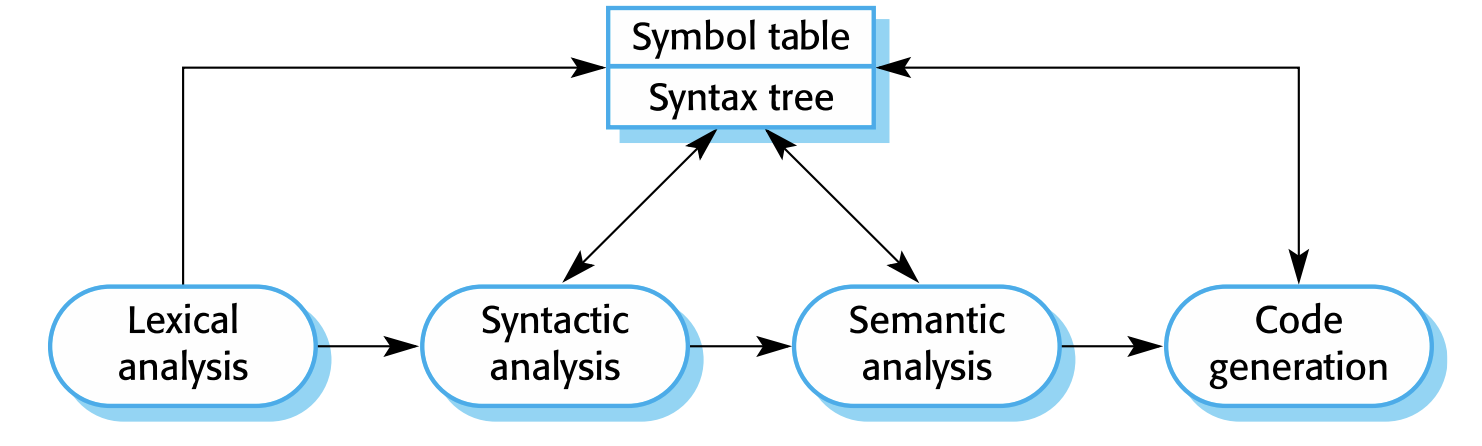
Language processing system
기계어나 자연어를 입력받아 다른 표현으로 변환하는 시스템을 말한다. 우리가 흔히 생각하는 컴파일러, 인터프리터가 이 시스템에 포함된다.
컴파일러의 경우 아키텍처가 방식에 따라 여러개로 나뉘고, 이전에 Architecture Pattern에서 보였던 기법들을 주로 사용한다. (pipe-and-filter , repository 등)
오늘은 Architecture Pattern에 대해서 알아보았다.
