- 강의 : 스프링 DB 1편 - 데이터 접근 핵심 원리
- 코드 : Github DB 1편 코드
JDBC
JDBC 등장 이유
개발할 때 중요한 데이터는 대부분 DB에 보관한다. 클라이언트가 애플리케이션 서버를 통해 데이터를 저장하거나 조회하면, 애플리케이션 서버는 과정을 통해서 DB를 사용한다.
1. 커넥션 연결 : 주로TCP/IP를 사용해서 커넥션을 연결
2. SQL 전달 : 애플리케이션 서버는 DB가 이해할 수 있는 SQL을 연결된 커넥션을 통해 DB에 전달
3. 결과 응답 : DB는 전달된 SQL을 수행하고 그 결과를 응답, 애플리케이션 서버는 응답 결과 활용
애플리케이션 서버 - DB 연결 문제
각각의 DB마다 커넥션을 연결하는 방법, SQL을 전달하는 방법, 결과 응답 받는 방법이 모두 다르다. 여기서 문제 2가지가 있다.
- DB를 다른 종류의 DB로 변경하면 애플리케이션 서버에 개발된 DB 사용 코드도 함께 변경해야 한다.
- 개발자가 각각의 DB마다 커넥션 연결, SQL 전달, 그리고 그 결과를 응답 받는 방법을 새로 학습
이런 문제 해결을 위해 JDBC라는 자바 표준 등장
JDBC 표준 인터페이스
JDBC(Java Database Connectivity)는 자바에서 DB에 접속할 수 있도록 하는 자바 API다. JDBC는 DB에서 자료를 쿼리하거나 업데이트하는 방법을 제공한다.
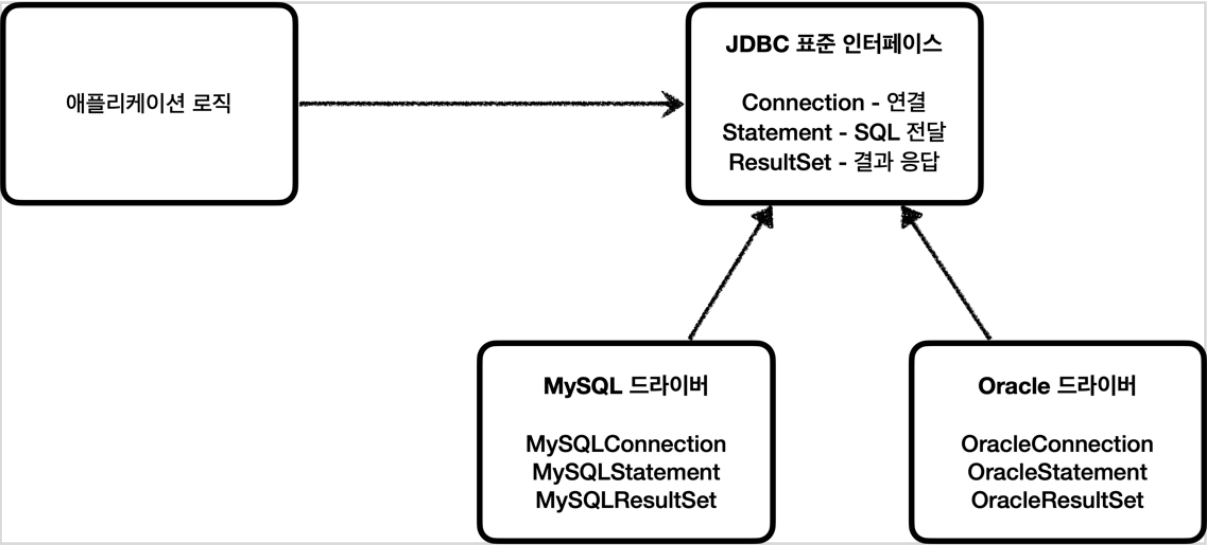
대표적으로 3가지 기능을 표준 인터페이스로 정의해서 제공한다.
java.sql.Connection- 연결java.sql.Statement- SQL을 담은 내용java.sql.ResultSet- SQL 요청 응답
JDBC 최신 기술
SQL MapperORM
JDBC 직접 사용

SQL Mapper

-
장점 : JDBC를 편리하게 사용하도록 도와준다.
- SQL 응답 결과를 객체로 편리하게 변환해준다.
- JDBC의 반복 코드를 제거해준다.
-
단점 : 개발자가 SQL 작성해야한다.
-
대표 기술 : JdbcTemplate, Mybatis
ORM
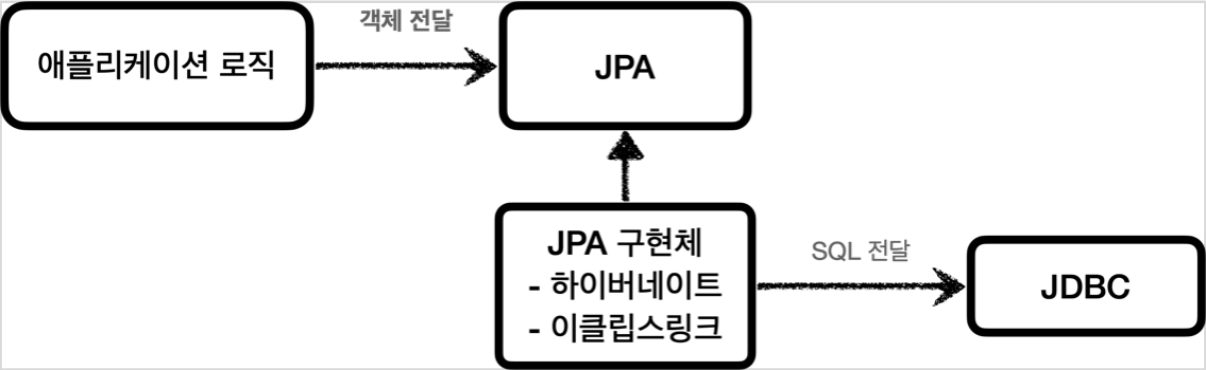
-
ORM은 객체를 관계형 DB 테이블과 매핑해주는 기술
- 반복적인 SQL 직접 작성 않음
- 개발자 대신 SQL을 동적으로 만들어 실행
- DB마다 다른 SQL을 사용하는 문제도 중간에서 해결
-
대표 기술 : JPA, 하이버네이트
커넥션풀과 데이터 소스
커넥션 풀
DB 커넥션을 매번 획득
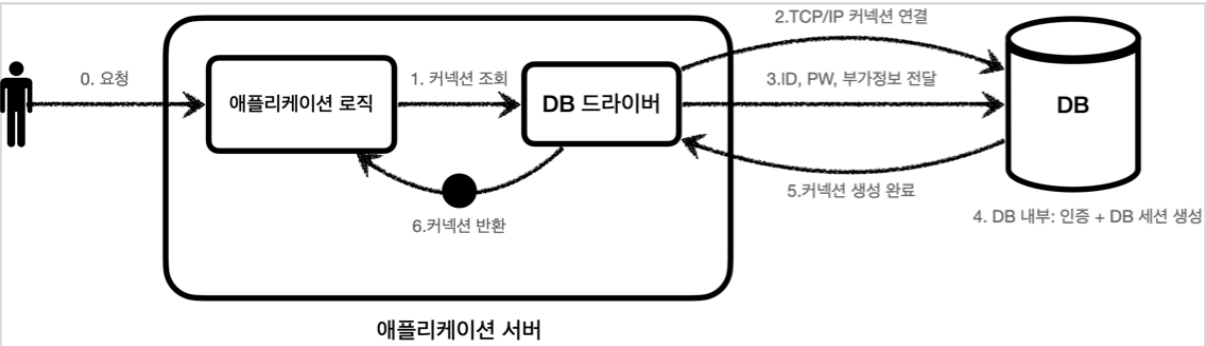
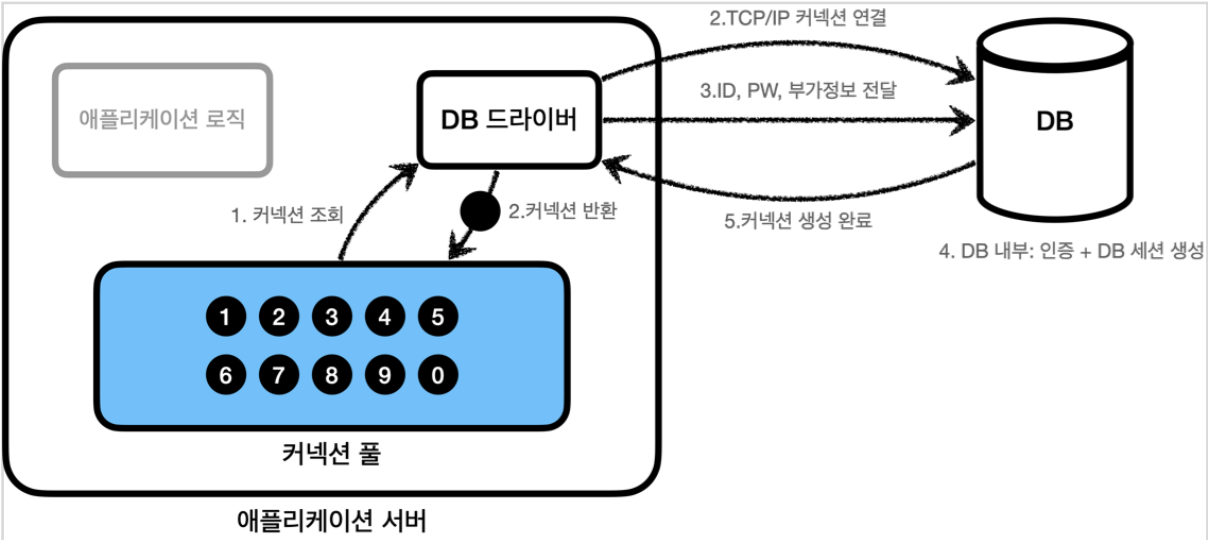
DB 커넥션을 획득할 때는 복잡한 과정을 거친다.
- 애플리케이션 로직은 DB 드라이버를 통해 커넥션을 조회한다.
- DB 드라이버는 DB와
TCP/IP커넥션을 연결한다. (3 way handshake동작 발생)- DB 드라이버는
TCP/IP커넥션이 연결되면 ID, PW와 기타 부가정보 DB에 전달- DB는 ID, PW를 통해 내부 인증을 완료하고, 내부에 DB 세션을 생성
- DB 커넥션 생성이 완료되었다는 응답
- DB 드라이버는 커넥션 객체를 생성해서 클라이언트에 반환
이렇게 커넥션을 새로 만드는 과정 -> 복잡하고 시간이 많이 소모
커넥션을 미리 생성해두고 사용하는 커넥션 풀 방식 사용
커넥션 풀 초기화
애플리케이션을 시작하는 시점에 커넥션 풀은 필요한만큼 커넥션을 미리 확보해서 풀에 보관한다. (보통 디폴트 값 10개)
커넥션 풀 연결 상태
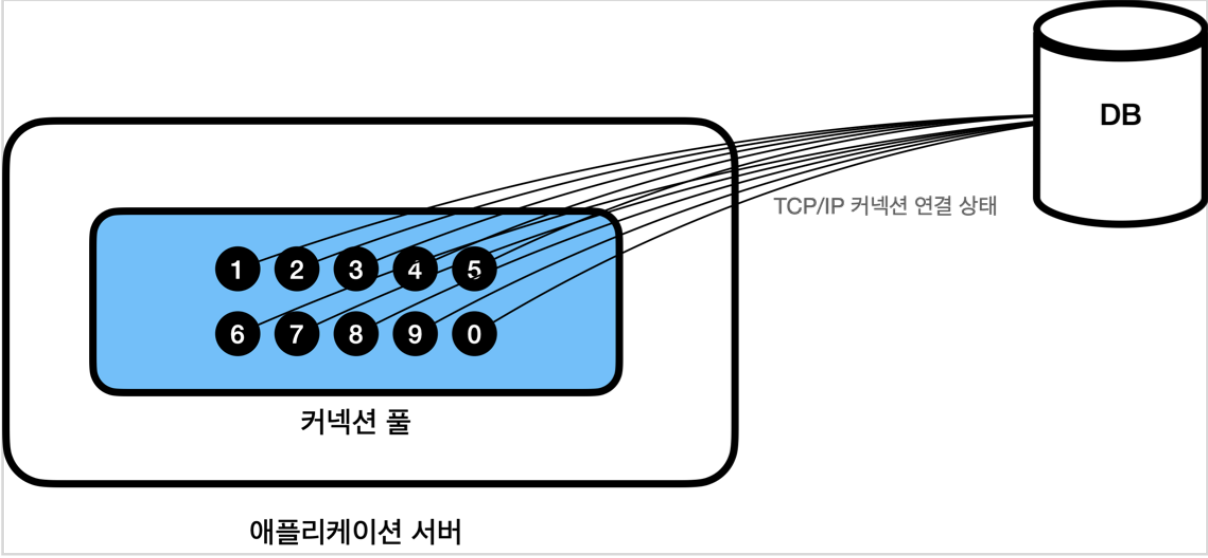
커넥션 풀에 들어있는 커넥션은 TCP/IP로 DB와 커넥션이 연결되어 있는 상태이기 때문에 즉시 SQL을 DB에 전달할 수 있다.
커넥션 풀 사용
- 애플리케이션 로직에서 이제는 DB 드라이버를 통해서 새로운 커넥션을 획득하는 것이 아니다.
- 이제는 커넥션 풀을 통해 이미 생성되어 있는 커넥션을 객체 참조로 가져다 쓰기만 하면 된다.
- 커넥션 풀에 커넥션을 요청하면 커넥션 풀은 자신이 가지고 있는 커넥션 중 하나를 반환한다.
- 애플리케이션 로직은 커넥션 풀에서 받은 커넥션을 사용해서 SQL을 DB에 전달하고 그 결과를 받아서 처리한다.
- 커넥션을 모두 사용하고 나면 커넥션이 살아있는 상태로 풀에 반환한다.
정리
- 이런 커넥션 풀은 얻는 이점이 매우 크기 때문에 실무에서는 항상 기본으로 사용한다.
- 커넥션 풀은 개념적으로 단순해서 직접 구현할 수도 있지만, 사용도 편리하고 성능도 뛰어난 오픈소스 커넥션 풀이 많기 때문에 오픈소스를 사용하는 것이 좋다. 대표적인 커넥션 풀 오픈소스는
commons-dbcp2,tomcat-jdbc pool,HikariCP등이 있다. - 성능과 사용의 편리함 측면에서 최근에는
hikariCP를 주로 사용한다. 스프링 부트 2.0 부터는 기본 커넥션 풀로hikariCP를 제공한다. 성능, 사용의 편리함, 안전성 측면에서 이미 검증이 되었기 때문에 커넥션 풀을 사용할 때는 고민할 것 없이 hikariCP 를 사용하면 된다
DataSource 이해
커넥션을 얻는 방법은 JDBC DriverManager를 직접 사용하거나, 커넥션 풀을 사용하는 등 다양한 방법 존재
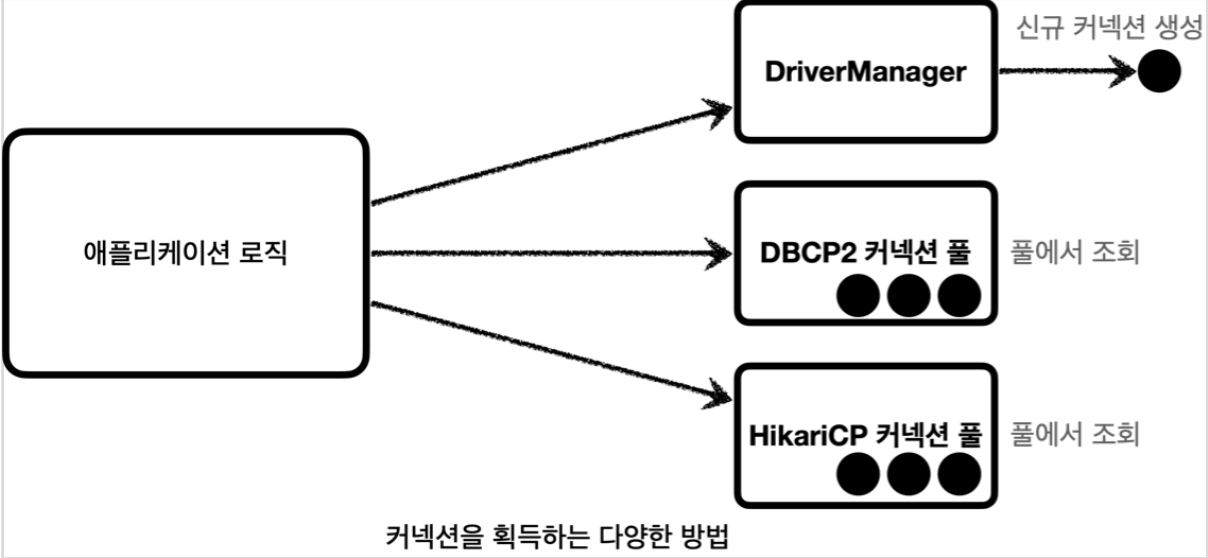
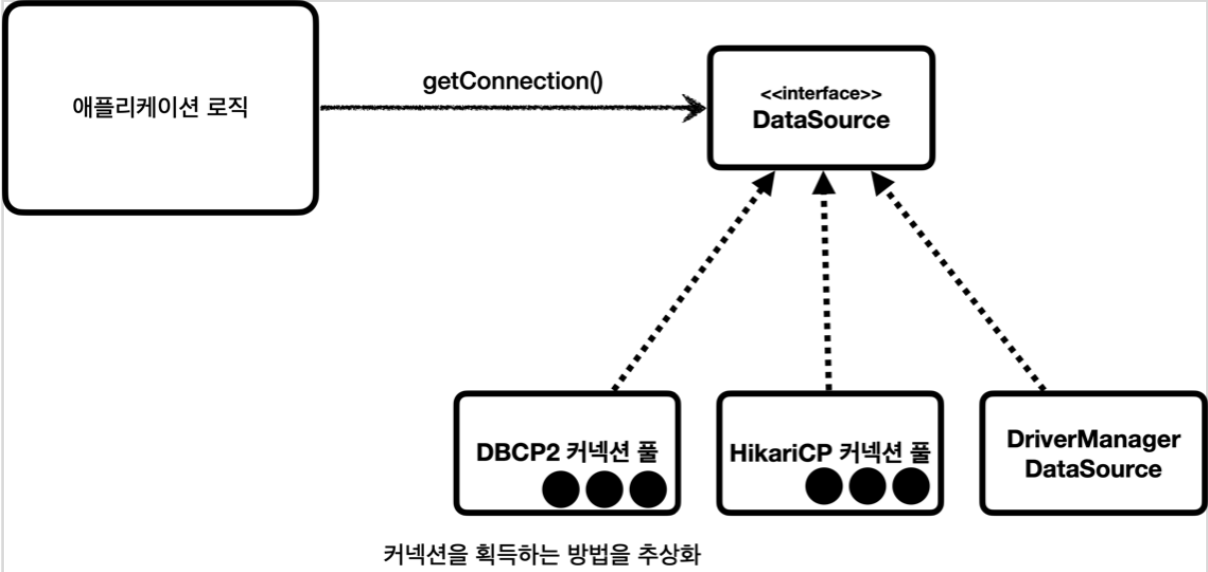
- 자바에서는 이런 문제를 해결하기 위해
javax.sql.DataSource라는 인터페이스 제공 DataSource는 커넥션을 획득하는 방법을 추상화하는 인터페이스- 이 인터페이스의 핵심 기능은 커넥션 조회 하나
DriverManager와 DataSource의 차이
DriverManager는 커넥션을 획득할 때 마다URL,USERNAME,PASSWORD같은 파라미터를 계속 전달해야 한다. 반면에DataSource를 사용하는 방식은 처음 객체를 생성할 때만 필요한 파리미터를 넘겨두고, 커넥션을 획득할 때는 단순히dataSource.getConnection()만 호출하면 된다.
트랜잭션
트랜잭션을 이름 그대로 번역하면 거래라는 뜻이다. 이것을 쉽게 풀어서 이야기하면, 데이터베이스에서
트랜잭션은 하나의 거래를 안전하게 처리하도록 보장해주는 것을 뜻한다.
ACID
- 원자성 : 트랜잭션 내에서 실행한 작업들은 마치 하나의 작업인 것처럼 모두 성공하거나 모두 실패해야 한다.
- 일관성 : 모든 트랜잭션은 일관성 있는 DB 상태를 유지해야 한다.
- 격리성 : 동시에 실행되는 트랜잭션들이 서로에게 영향을 미치지 않도록 격리한다.
- 지속성 : 트랜잭션을 성공적으로 끝내면 결과가 항상 기록되어야 한다. 중간에 문제가 발생해도 DB 로그 등을 사용해서 성공한 트랜잭션 내용을 복구해야 한다.
DB 연결 구조와 DB 세션
DB 연결구조 1

- 사용자는 WAS나 DB 접근 툴 같은 클라이언트를 사용해서 DB 서버에 접근, 클라이언트는 DB 서버에 연결을 요청하고 커넥션을 맺고, DB 서버는 내부에 세션을 만들어 앞으로의 커넥션을 통한 모든 요청은 세션을 통해 실행
- 개발자가 클라이언트를 통해 SQL을 전달하면 현재 커넥션에 연결된 세션이 SQL을 실행
- 세션은 트랜잭션을 시작, 커밋 또는 롤백을 통해 트랜잭션 종료
- 사용자가 커넥션을 닫거나, DBA(DB 관리자)가 세션을 강제로 종료하면 세션 종료
DB 연결구조 2

커넥션 풀이 10개의 커넥션을 생성하면, 세션도 10개 만들어진다.
트랜잭션 - 개념 이해
사용법 :
- 데이터 변경 쿼리를 실행하고 DB에 그 결과를 반영하려면
commit을 호출, 롤백하려면 명령어rollback호출- 커밋을 호출하기 전까지는 임시로 데이터 저장
- 등록, 수정, 삭제 모두 같은 원리 -> 변경
커밋하지 않은 데이터를 다른 곳에서 조회할 수 있으면 심각한 문제 발생
자동 커밋, 수동 커밋
자동 커밋
커밋이나 롤백을 직접 호출하지 않아 편리, 실행할 때마다 자동 커밋되기 때문에 원하는 트랜잭션 기능을 제대로 사용할 수 없다.
수동 커밋
수동 커밋 모드로 설정하는 것을 트랜잭션 시작이라고 표현
수동 커밋 설정하면 이후 꼭 commit, rollback 호출
DB 락
세션이 트랜잭션을 시작하고 데이터를 수정하는 동안 커밋이나 롤백 전까지 다른 세션에서 해당 데이터를 수정할 수 없게 막아야 한다.
-> DB 락 개념 제공
락 순서
- 세션1은 트랜잭션 시작
- 세션1은
memberA의money를 500으로 변경 시도, 이때 로우 락을 먼저 획득 - 세션1은 락을 획득했으므로 로우에 update sql 수행
- 세션2는 트랜잭션 시작
- 세션2도
memberA의money데이터 변경 시도, 락이 없으므로 락이 돌아올 때까지 대기 (락 대기시간 넘어가면 타임아웃 오류 발생) - 세션1 커밋 수행과 트랜잭션 종료, 락 반납
- 대기하던 세션2가 락을 획득 후 update sql 수행, 트랜잭션 종료 후 락 반납
스프링 어플리케이션 구조와 문제점
애플리케이션 구조

프레젠테이션 계층
- UI와 관련된 처리 담당
- 웹 요청과 응답
- 사용자 요청 검증
- 주 사용 기술 : 서블릿과 HTTP 웹 기술, 스프링 MVC
서비스 계층
- 비즈니스 로직을 담당
- 주 사용 기술 : 가급적 특정 기술에 의존하지 않고, 순수 자바 코드로 작성
데이터 접근 계층
- 실제 DB에 접근하는 코드
- 주 사용 기술 : JDBC, JPA, File, Redis, Mongo ...
순수한 서비스 계층
- 가장 핵심 비즈니스 로직이 들어있는 계층, 시간이 흘러 다른 부분이 변해도 비즈니스 로직은 최대한 변경없이 유지해야 한다.
- 종속적인 개발
- 서비스 계층은 가급적 비즈니스 로직만 구현하고 특정 구현 기술에 직접 의존해서는 안된다.
문제점
- 트랜잭션 문제
- 예외 누수 문제
- JDBC 반복 문제
트랜잭션 문제
- JDBC 구현 기술이 서비스 계층에 누수되는 문제
- 트랜잭션을 적용하기 위해 JDBC 구현 기술이 서비스 계층에 누수
- 서비스 계층은 순수해야 한다. -> 구현 기술을 변경해도 서비스 계층 코드는 최대한 유지할 수 있어야 한다.
- 그래서 데이터 접근 계층에 JDBC 코드 몰아두는 것
- 데이터 접근 계층의 구현기술이 변경될 수 있으니 데이터 접근 계층은 인터페이스 제공하는 것이 좋다.
트랜잭션 동기화
스프링이 제공하는 트랜잭션 매니저는 크게 2가지 역할을 한다.
트랜잭션 추상화
리소스 동기화
트랜잭션을 유지하려면 트랜잭션의 시작부터 끝까지 같은 DB 커넥션을 유지해야한다. 결국 같은 커넥션을 동기화하기 위해서 이전에는 파라미터로 커넥션을 전달하는 방법을 사용
트랜잭션 매니저와 트랜잭션 동기화 매니저
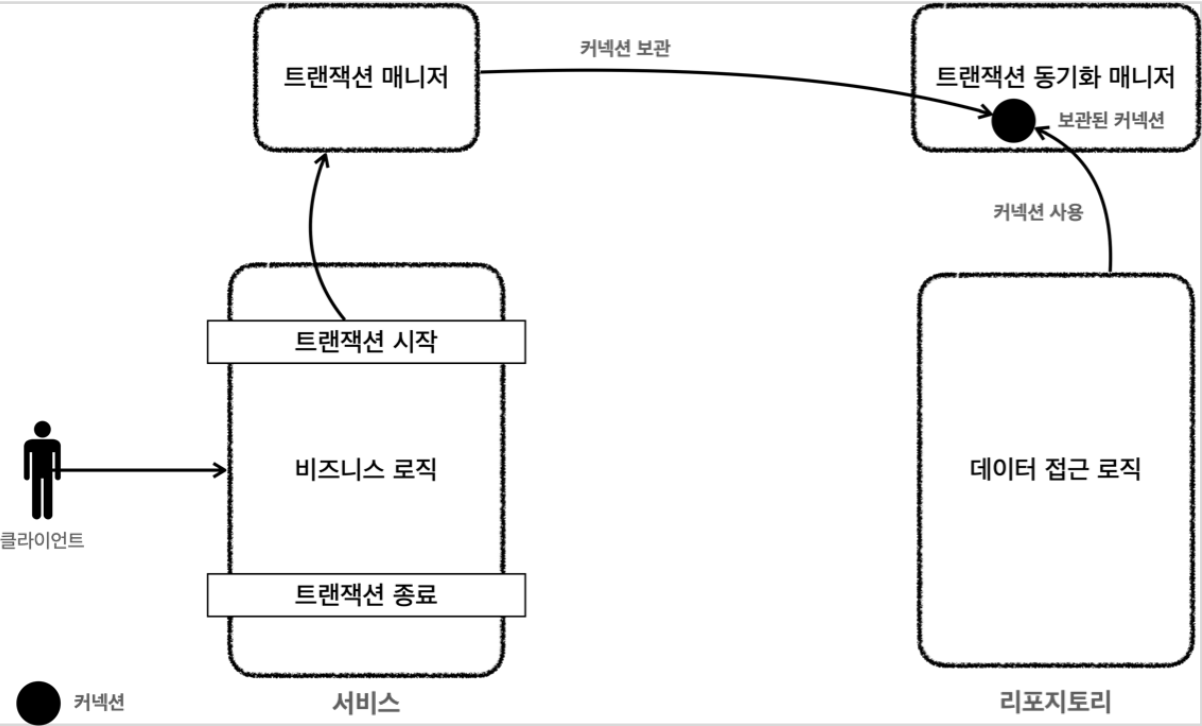
- 스프링 트랜잭션 동기화 매니저를 제공. 이것은 쓰레드 로컬을 사용해서 커넥션을 사용해서 커넥션을 동기화해준다. 트랜잭션 매니저는 내부에서 이 트랜잭션 동기화 매니저를 사용한다.
- 트랜잭션 동기화 매니저는 쓰레드 로컬을 사용하기 때문에 멀티 쓰레드 상황에 안전하게 커넥션을 동기화 할 수 있다. 커넥션이 필요하면 트랜잭션 동기화 매니저를 통해 커넥션 획득하면 된다.
동작 방식
1. 트랜잭션 시작에 커넥션 필요, 트랜잭션 매니저는 데이터 소스를 통해 커넥션을 만들고 트랜잭션 시작
2. 트랜잭션 매니저는 트랜잭션이 시작된 커넥션을 트랜잭션 동기화 매니저에 보관
3. 리파지토리는 트랜잭션 동기화 매니저에 보관된 커넥션을 꺼내 사용, 파라미터로 커넥션을 전달하지 않아도 된다.
4. 트랜잭션이 종료되면 트랜잭션 매니저는 트랜잭션 동기화 매니저에 보관된 커넥션을 통해 트랜잭션을 종료하고, 커넥션도 닫는다.
트랜잭션 매니저의 전체 동작 흐름
트랜잭션 매니저1 - 트랜잭션 시작
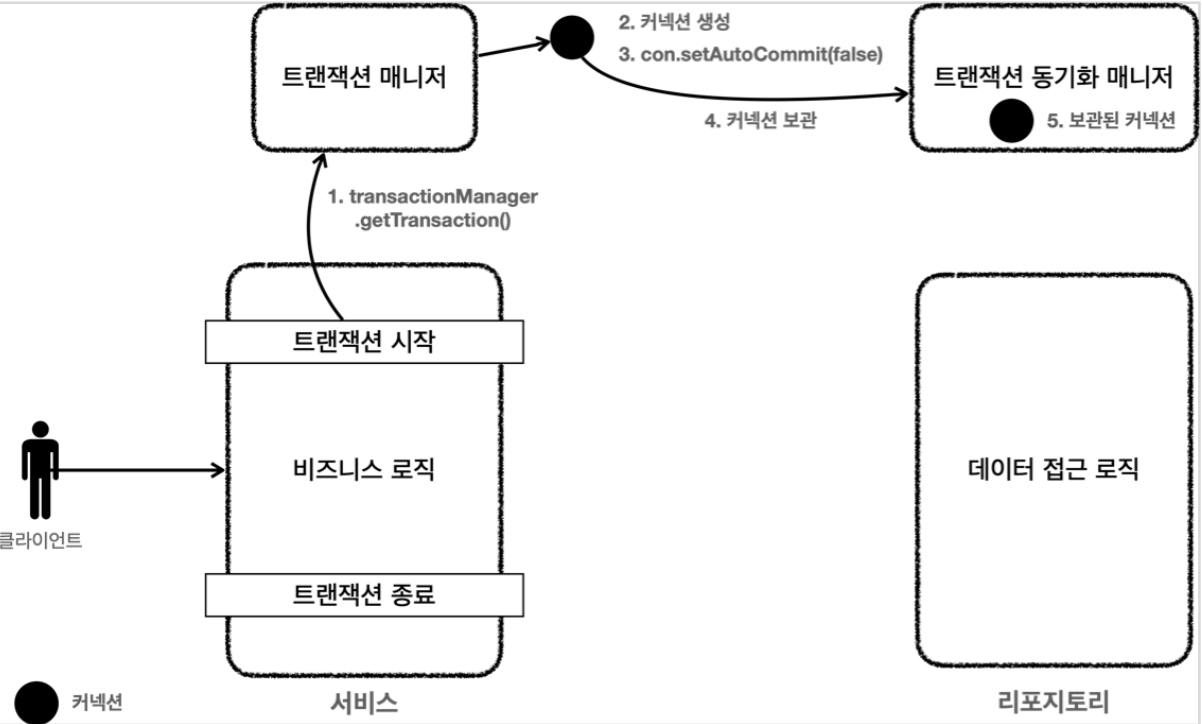
클라이언트의 요청으로 서비스 로직을 실행
1. 서비스 계층에서 transactionManager.getTransaction()을 호출해서 트랜잭션 시작
2. 트랜잭션 매니저는 내부에서 데이터 소스를 사용해서 커넥션 생성
3. 커넥션을 수동 커밋 모드로 변경해서 실제 데이터베이스 트랜잭션을 시작
4. 커넥션을 트랜잭션 동기화 매니저에 보관
5. 트랜잭션 동기화 매니저는 쓰레드 로컬에 커넥션을 보관, 멀티 쓰레드 환경에 안전하게 커넥션을 보관
트랜잭션 매니저2 - 로직 실행

- 서비스는 비즈니스 로직을 실행하면서 리파지토리의 메서드들을 호출한다. 이때 커넥션을 파라미터로 전달하지 않는다.
- 리파지토리 메서드들은 트랜잭션이 시작된 커넥션이 필요 ->
DataSourceUtils.getConnection()을 사용해서 트랜잭션 유지 - 획득한 커넥션을 사용해서 SQL을 DB에 전달해서 실행
트랜잭션 매니저3 - 트랜잭션 종료
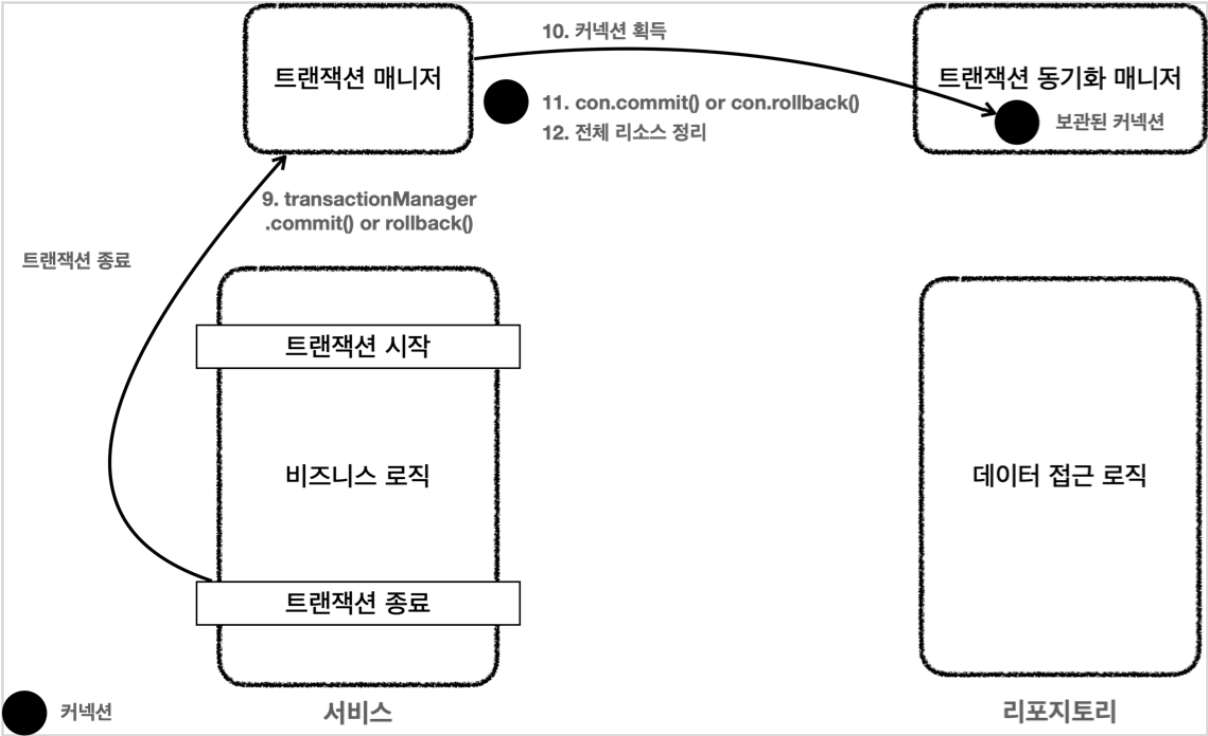
- 비즈니스 로직이 끝나고 트랜잭션 종료, 트랜잭션은 커밋하거나 롤백하면 종료
- 트랜잭션을 종료하려면 동기화된 커넥션이 필요, 트랜잭션 동기화 매니저를 통해 동기화된 커넥션 획득
- 획득한 커넥션을 통해 DB에 트랜잭션을 커밋하거나 롤백
- 전체 리소스 정리
- 트랜잭션 동기화 매니저 정리, 쓰레드 로컬은 사용후 꼭 정리
con.setAutoCommit(true)로 되돌린다. 커넥션 풀을 고려해야 한다.con.close()를 호출해서 커넥션을 종료한다. 커넥션 풀을 사용하는 경우con.close()를 호출하면 커넥션 풀에 반환
트랜잭션 문제 해결 - 트랜잭션 AOP
반복적은 트랜잭션 로직을 해결하기 위해 트랜잭션 템플릿 도입
순수한 서비스 로직만 남긴다는 목표 달성은 못함 -> 스프링 AOP 도입
스프링이 제공하는 트랜잭션 AOP
개발자는 트랜잭션 처리가 필요한 곳에 @Transactional 애노테이션만 붙여주면 된다.
자바 예외
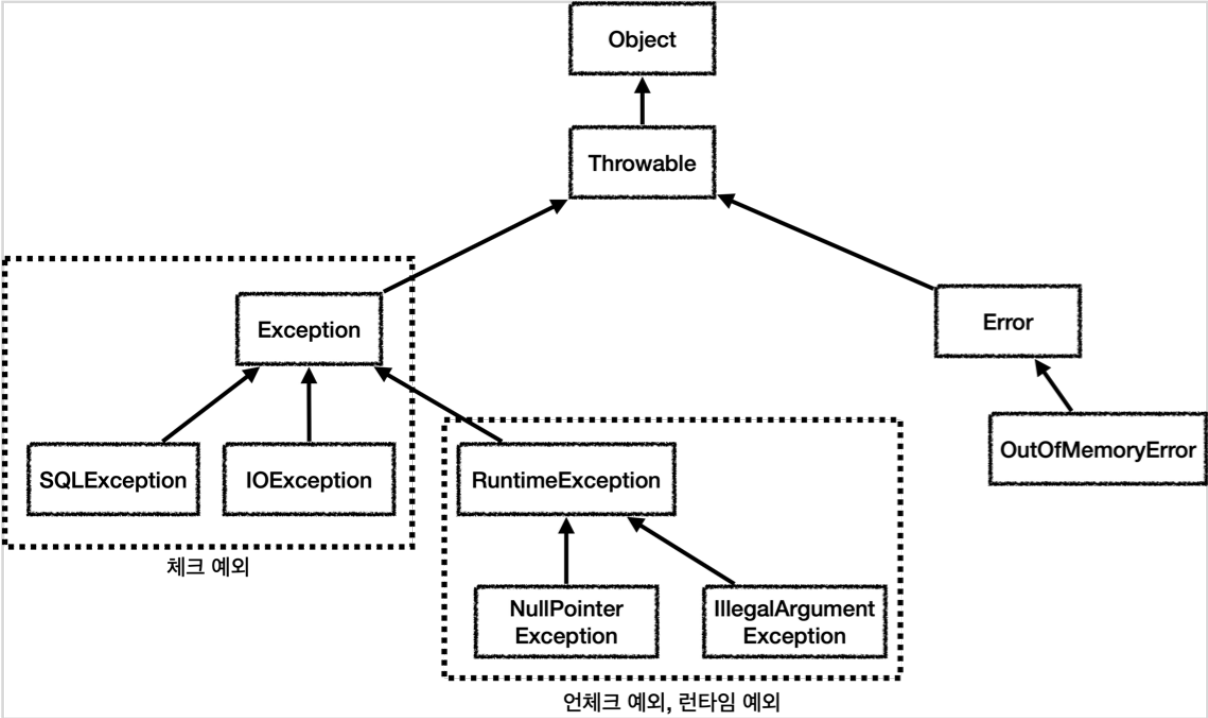
Object: 예외도 객체, 모든 객체의 최상위 부모는Object이므로 예외의 최상위 부모도ObjectThrowable: 최상위 예외, 하위에Exception과ErrorError: 메모리 부족이나 심각한 시스템 오류와 같이 애플리케이션 복구 불가능한 시스템 예외, 애플리케이션 개발자는 이 예외를 잡으려고 해서는 안된다.- 상위 예외를
catch로 잡으면 그 하위 예외까지 함께 잡는다. 애플리케이션 로직에서는Throwable에외도 잡으면 안되는데, 앞서 이야기한Error예외도 함께 잡을 수 있기 때문이다. 애플리케이션 로직은 이런 이유로Exception부터 필요한 예외로 생각하고 잡으면 된다. - 참고로
Error도 언체크 예외
- 상위 예외를
Exception: 체크 예외- 애플리케이션 로직에서 사용할 수 있는 실질적 최상위 예외
Exception과 그 하위 예외는 모두 컴파일러가 체크하는 체크 예외, 단RuntimeException은 예외
RuntimeException: 언체크 예외, 런타임 예외- 컴파일러가 체크하지 않는 언체크 예외
RuntimeException과 그 자식 예외는 모두 언체크 예외RuntimeException의 이름을 따라서RuntimeException과 그 하위 언체크 예외를 런타임 예외라고 많이 부른다.
예외 기본 규칙
예외는 폭탄 돌리기와 같다. 잡아서 처리하건, 처리할 수 없으면 밖으로 던져야한다.
예외 처리
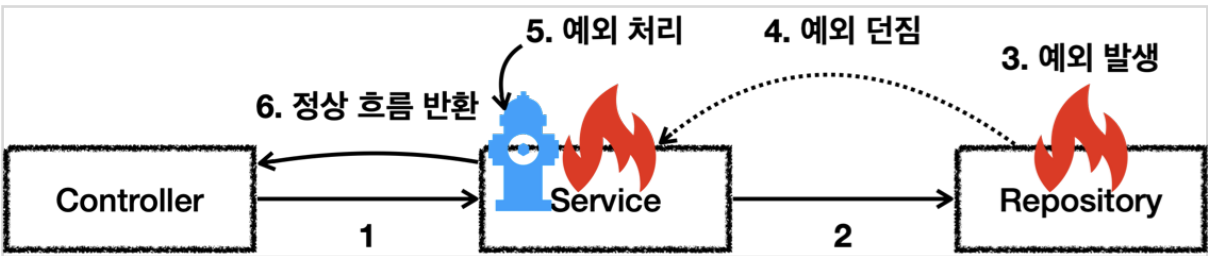
예외 던짐
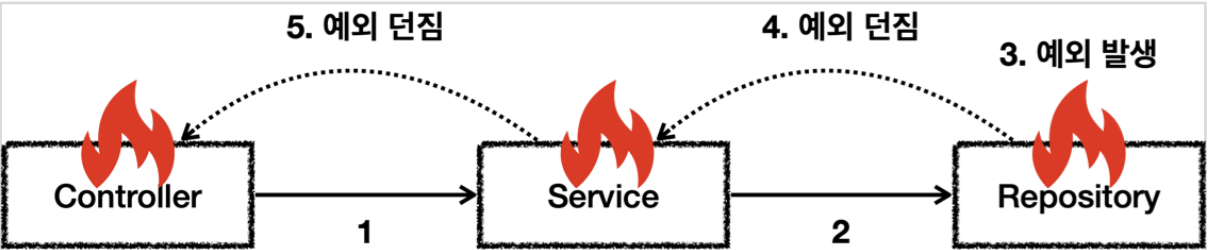
예외 2가지 기본 규칙
1. 예외는 잡아서 던지거나 처리해야 한다.
2. 예외를 잡거나 던질 때 지정한 예외 뿐만 아니라 그 예외 자식들도 함께 처리된다.
체크 예외 기본 이해
Exception과 그 하위 에외는 모두 컴파일러가 체크하는 체크 예외,RuntimeException은 예외로 한다.- 체크 예외는 잡아서 처리하거나, 또는 밖으로 던지도록 선언해야 한다. 그렇지 않으면 컴파일 오류가 발생
체크 예외의 장단점
체크 예외는 예외를 잡아서 처리할 수 없을 때, 예외를 밖으로 던지는 throw 예외를 필수로 선언해야 한다. 그렇지 않으면 컴파일 오류 발생
- 장점 : 개발자가 실수로 예외를 누락하지 않도록 컴파일러를 통해 문제를 잡아주는 훌륭한 안전 장치
- 단점 : 실제로 개발자가 모든 체크 예외를 반드시 잡거나 던지도록 처리해야하기 때문에 번거로움, 크게 신경쓰지 않는 예외까지 모두 챙겨야함
언체크 예외 기본 이해
RuntimeException과 그 하위 예외는 언체크 예외로 분류- 언체크 예외는 말 그대로 컴파일러가 예외를 체크하지 않는다는 뜻
- 언체크 예외는 체크 예외와 기본적 동일, 차이가 있다면
throws선언하지 않고, 생략 가능 이 경우 자동으로 예외를 던진다.
체크 예외 vs 언체크 예외
- 체크 예외 : 예외를 잡아서 처리하지 않으면 항상
throws에 던지는 예외를 선언 - 언체크 예외 : 예외를 잡아서 처리하지 않아도
throws를 생략
언체크 예외의 장단점
언체크 예외는 예외를 잡아서 처리할 수 없을 때, 예외를 밖으로 던지는 throws 예외를 생략할 수 있기 때문에 장점과 단점 동시 존재
- 장점 : 신경쓰고 싶지 않은 언체크 예외 무시 가능
- 단점 : 언체크 예외는 개발자가 실수로 예외를 누락할 수 있다.
체크 예외 활용
- 기본적으로 언체크 예외 사용
- 체크 예외는 비즈니스 로직상 의도적으로 던지는 예외에만 사용
- 예) 계좌 이체 실패
- 결제 포인트 부족
- 로그인 ID, PW 불일치
체크 예외의 문제점
1. 처리할 수 있는 체크 예외라면 서비스나 컨트롤러에서 처리 DB나 네트워크 통신처럼 시스템 레벨에서 올라온 예외들은 복구 불가능
2. 문제는 이런 예외를 사용하면 아래에서 복구 불가능한 예외를 각각의 클래스가 알아야 한다. 그래서 불필요한 의존 관계 문제 발생
언체크 예외 활용
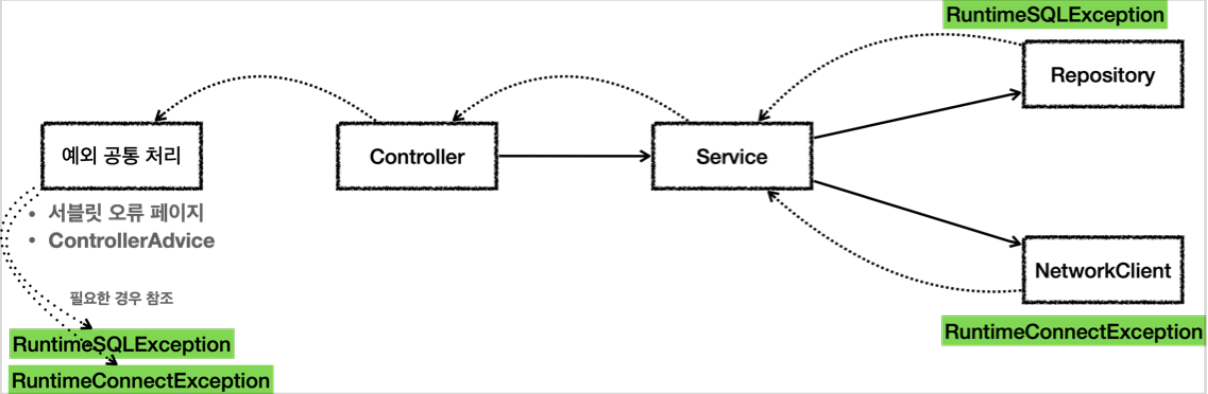
SQLException을 런타임 예외인RuntimeSQLException으로 변환ConnectionException대신에RuntimeConnectException을 사용하도록 바꾸었다.- 런타임 예외이기 때문에, 컨트롤러는 해당 예외들을 처리할 수 없다면 별도의 선언없이 그냥 놔둔다.
런타임 예외 - 대부분 복구 불가능한 예외
시스템에서 발생한 예외는 대부분 복구 불가능 예외, 런타임 예외를 사용하면 서비스나 컨트롤러가 이런 복구 불가능한 예외를 신경쓰지 않아도된다. 물론 이렇게 복구 불가능한 예외는 일관성있게 공통으로 처리
런타임 예외 - 의존 관계에 대한 문제
런타임 예외는 해당 객체가 처리할 수 없는 예외는 무시하면 된다. 따라서 체크 예외처럼 예외를 강제로 의존하지 않아도 된다.
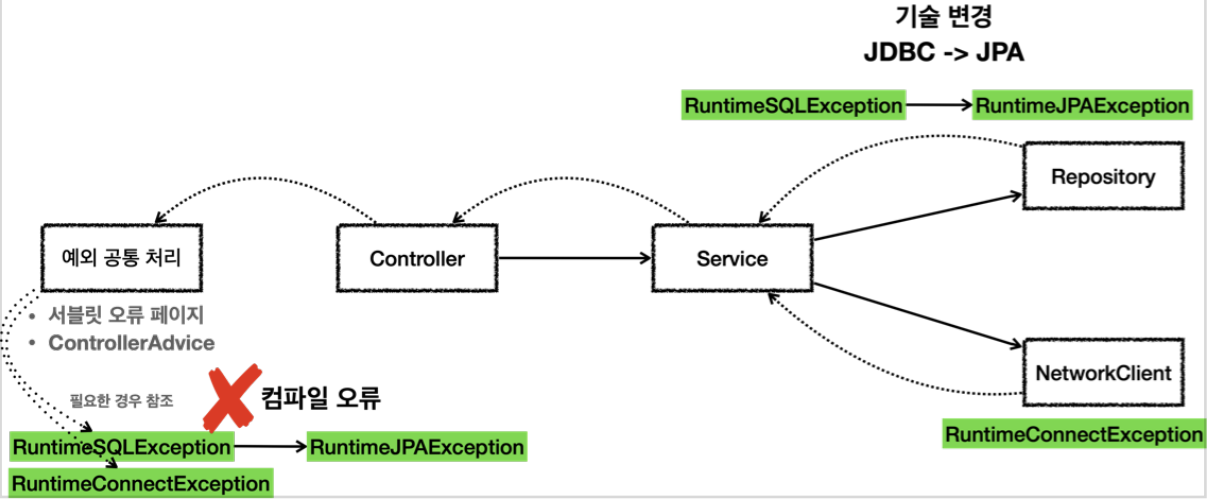
- 런타임 예외를 사용하면 중간에 기술이 변경되어도 해당 예외를 사용하지 않는 컨트롤러, 서비스에는 코드를 변경하지 않아도 된다.
- 구현 기술이 변경되는 경우, 예외를 공통으로 처리하는 곳에서는 예외에 따른 다른 처리가 필요할 수 있다. 하지만 공통 처리하는 한곳만 변경하면 되기 때문에 변경의 영향 범위는 최소화된다.
로그와 스택 트레이스
- 로그를 출력할 때 마지막 파라미터에 예외를 넣어주면 로그에 스택 트레이스를 출력할 수 있다.
- 예) log.info("message={}", "message", ex) , 여기에서 마지막에 ex 를 전달 하는 것을 확인할 수 있다. 이렇게 하면 스택 트레이스에 로그를 출력할 수 있다.
- 예) log.info("ex", ex) 지금 예에서는 파라미터가 없기 때문에, 예외만 파라미터에 전달하면 스택 트레이스를 로그에 출력할 수 있다.
스프링의 예외 처리, 반복 문제 해결
체크 예외와 인터페이스
서비스 계층은 가급적 특정 구현 기술에 의존하지 않고, 순수하게 유지하는 것이 좋다. 예외에 대한 의존도 함께 해결해야한다.
서비스가 처리할 수 없는 SQLException에 대한 의존을 제거하려면 런타임 예외로 전환해서 서비스 계층에 던지자 이렇게 하면 서비스 게층이 해당 예외를 무시할 수 있기 때문에, 특정 구현 기술에 의존하는 부분을 제거하고 서비스 게층을 순수하게 유지할 수 있다.
코드
MyDbException
public class MyDbException extends RuntimeException {
public MyDbException() {
}
public MyDbException(String message) {
super(message);
}
public MyDbException(String message, Throwable cause) {
super(message, cause);
}
public MyDbException(Throwable cause) {
super(cause);
}
}MemberRepository
...
public Member save(Member member) {
String sql = "insert into member(member_id, money) values(?, ?)";
Connection con = null;
PreparedStatement pstmt = null;
try {
con = getConnection();
pstmt = con.prepareStatement(sql);
pstmt.setString(1, member.getMemberId());
pstmt.setInt(2, member.getMoney());
pstmt.executeUpdate();
return member;
} catch (SQLException e) {
throw new MyDbException(e);
} finally {
close(con, pstmt, null);
}
}
...SQLException이라는 체크 예외를MyDbException이라는 런타임 예외로 변환해서 던진다.
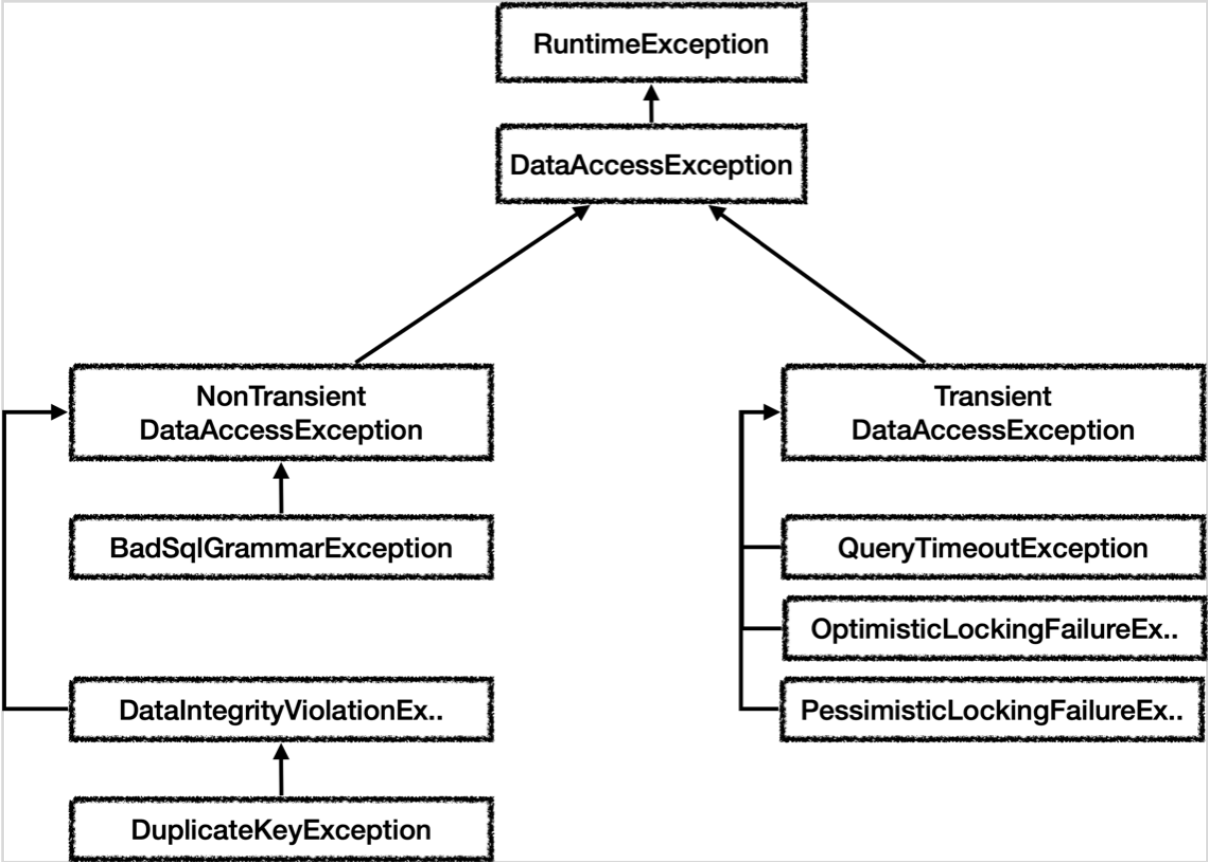
스프링 예외 추상화