상황
한달 동안 속도에 대한 이슈를 개선하는게 내 주된 업무였다.
유저는 늘어나고, 그 유저가 쌓는 데이터는 계속 늘어나다보니 초기에는 속도의 문제가 없어보였지만 데이터가 백만 단위가 넘어가고 가공까지 하니 속도에 대한 이슈가 생겼고, 점진적으로 개선한 내용을 글로 정리해본다.
(예시는 유저가 선택한 기간 내의 Product에 대한 정보를 요약해 보여주는 API 연간 단위로 조회했을 때의 일부분 입니다.)
1. 테이블 인덱스
성능 개선이 한번에 시간에 이어지지 않았는데 처음 적용한 것은 가장 짧은 시간에 적용할 수 있는 DB 인덱스였다.
일단 간단하게 인덱스에 대해 알아보면
인덱스- -> 책의 페이지와 동일 기능
- 장점
- 테이블 조회 속도와 성능 향상
- 전반적인 시스템 부하 감소
- 단점
- 인덱스를 관리하기 위한 DB 약 10% 정도의 저장공간 필요
- 추가 작업 필요
- 잘못 사용할 경우 오히려 성능 저하
- 동작
- Index Table에서
where에 포함된 값을 찾음 - 해당 값의
table_id [PK]을 가져옴 - 가져온
table_id [PK]값으로 원본 테이블에서 값을 조회 - B+Tree 알고리즘
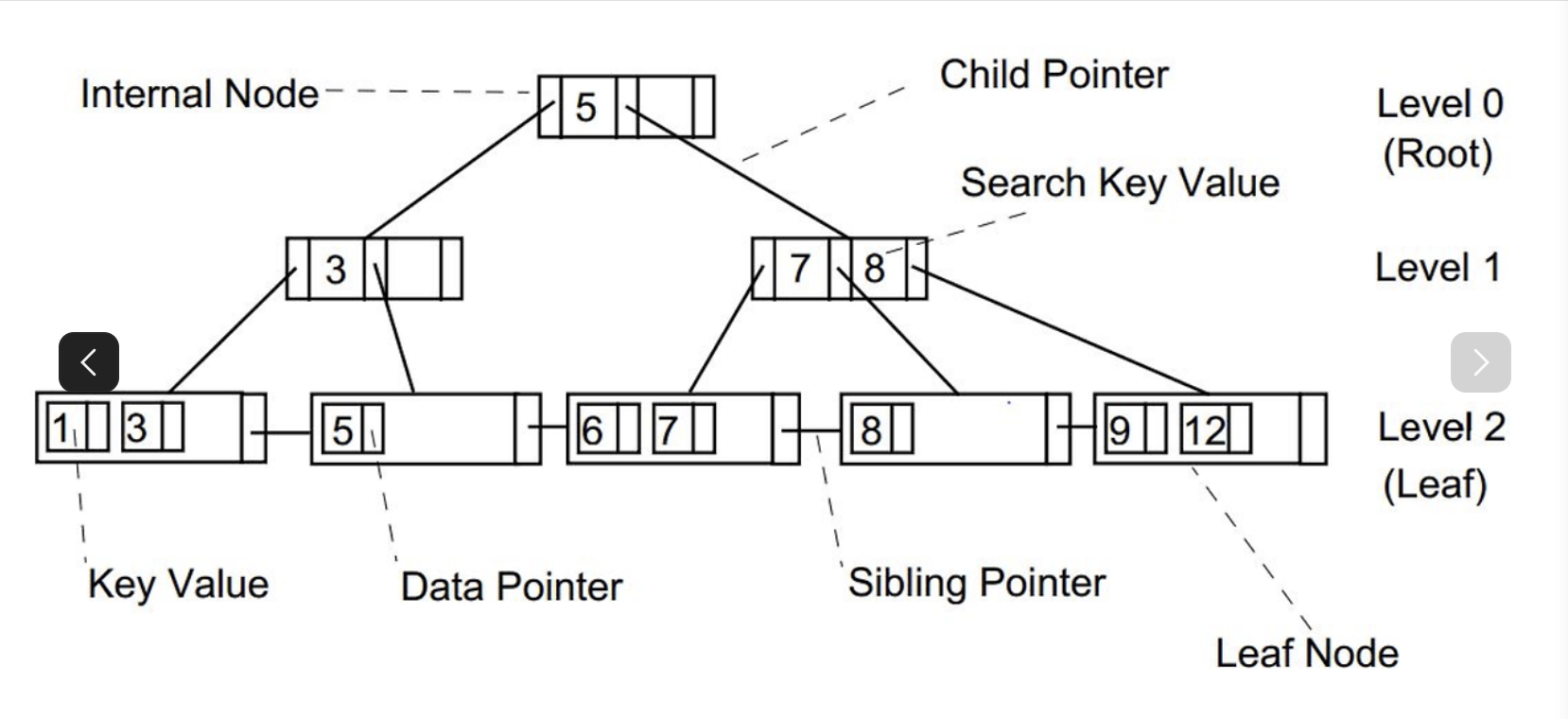
- Index Table에서
- 인덱스 설계 참고
- 조회시 자주 사용하는 칼럼 사용
- 고유한 값 위주로 설계
- PK, JOIN의 연결고리가 되는 칼럼
- JOIN시 자주 사용하는 칼럼
- 카디널리티 높을수록 좋음
- 테이블당 3~5개가 적당
- 성능, 메모리, 관리 복잡
실제 사용해보면
CREATE INDEX idx_orders_user_status_date ON orders(user_id, status, order_date DESC);위 인덱스는
SELECT * FROM orders
WHERE user_id = 123 AND status = 'pending'
ORDER BY order_date DESC;라는 쿼리에 최적화되어있는 인덱스이다.
다른 API의 호출에서 약 30만개의 데이터를 처리할 때
-
BEFORE
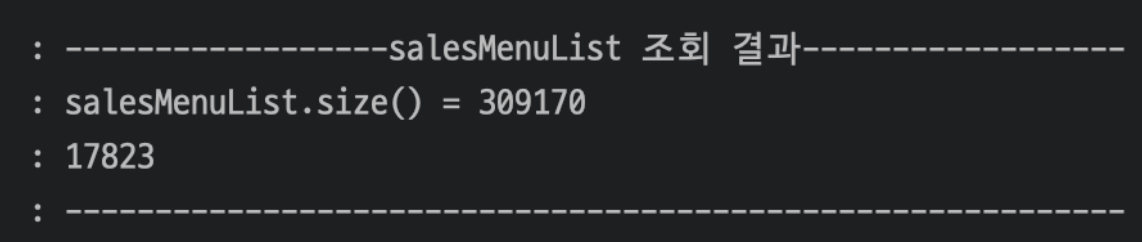
-
AFTER

약 38프로 개선을 확인했다.
2. 쿼리 최적화
BEFORE 코드
(실제 코드는 중간에 많은 코드가 들어있지만 속도 개선에 영향을 준 주요 부분을 요약했다.)
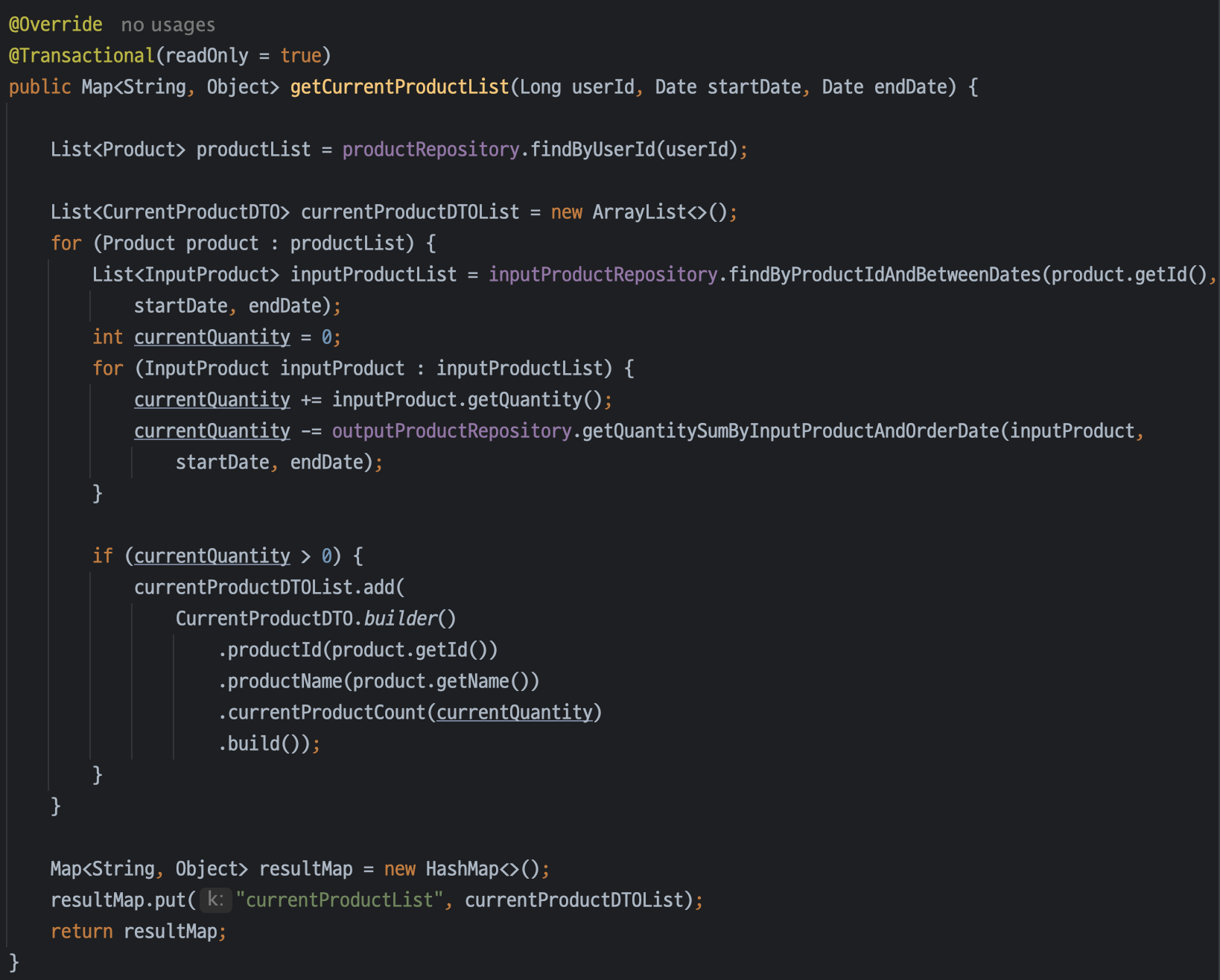
엔티티간의 관계는 product > inputProduct > outputProduct 조인 관계이고,
product: 제품 정보 (ex. 가격, 이름 등)inputProduct: 실제로 들어온 제품 (ex. 수량, 입고 날짜 등)outputProduct: 사용된 제품 (ex. 사용된 수량, 사용된 시간)
쿼리 시간복잡도가 O(n^2)이다. 초창기에 기능 구현에 집중했을 때는 문제가 없었겠지만 지금은 이전보다 사용자도 많아지고, 데이터도 쌓이다 보니까 속도에 O(n^2)은 큰 영향을 끼치고 있다.
일단 기능 구현 전 같은 기능을 측정해보고 개선을 해보자
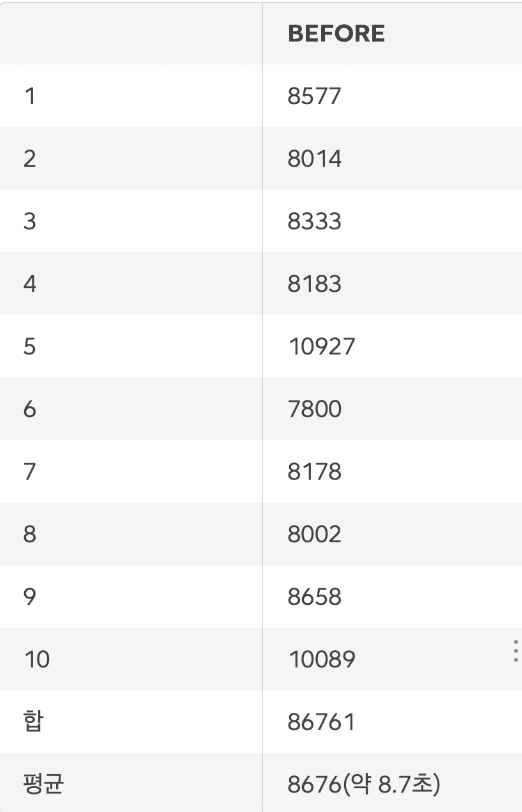
시간만 있다는 가정 하에 원래 목표는 쿼리를 최적화해서 시간 복잡도를 O(n)으로 만드는 것이였다.
그러기에 컴파일 하는데 오류도 잘 찾아주고, 복잡하거나 동적 쿼리 생성이 쉬운 Querydsl을 사용하였다.
처음은
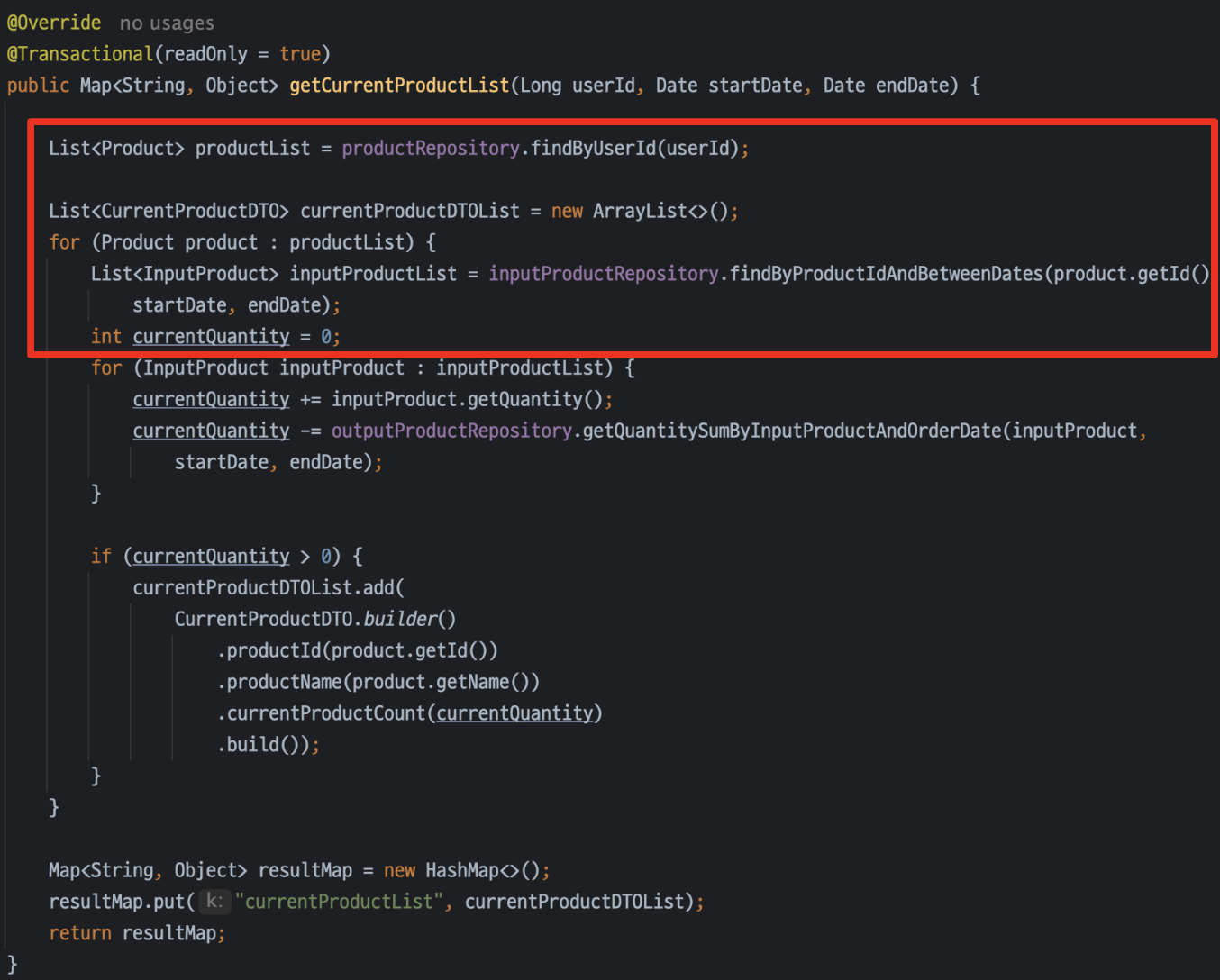
위의 빨간 네모 부분을 하나로 줄여보았다.
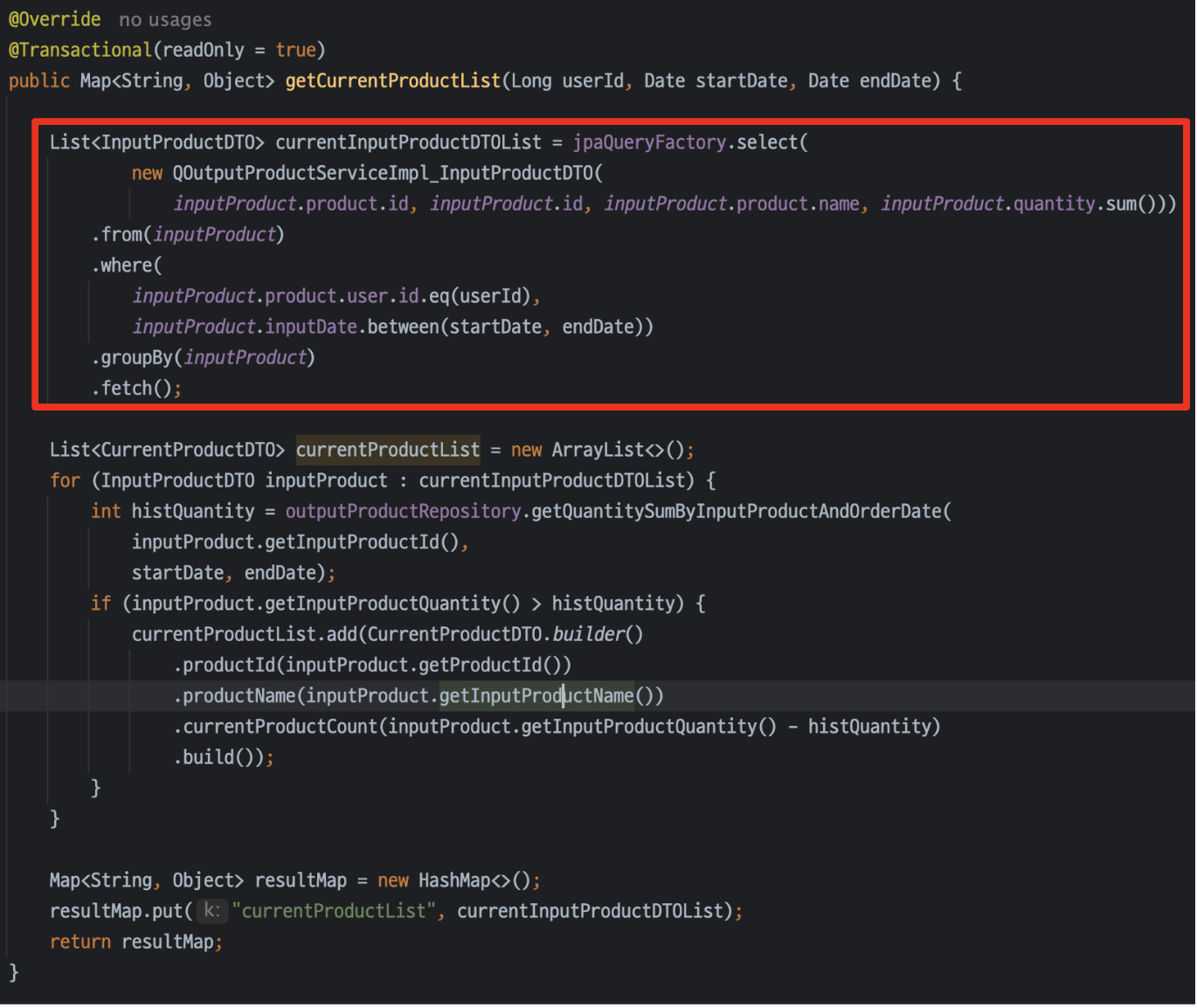
위의 빨간 네모 부분으로 줄였다.
지금 상태로 보면
* product 리스트 조회
-> product 별로 inputProduct 리스트 조회
-> inputProduct 별로 outputProduct 합산 차감이렇게 진행되는 기존의 서비스 코드를
* product 별 inputProduct 합산 리스트 조회
-> inputProduct 별로 outputProduct 합산 차감이런 방향으로 만들었다.
그래도 여전히 inputProduct 별로 outputProduct의 합산 쿼리가 여러번 나가는 거기 때문에 이 반복문을 한번으로 만들어 보려고 했다.
서브쿼리를 사용한 한개의 쿼리문을 통해 한번에 하고 싶었지만 Querydsl이 아직 익숙치 않아 null처리에 어려움을 겪어 일단 아래의 방법으로 결과적인 코드로 바꾸었다.
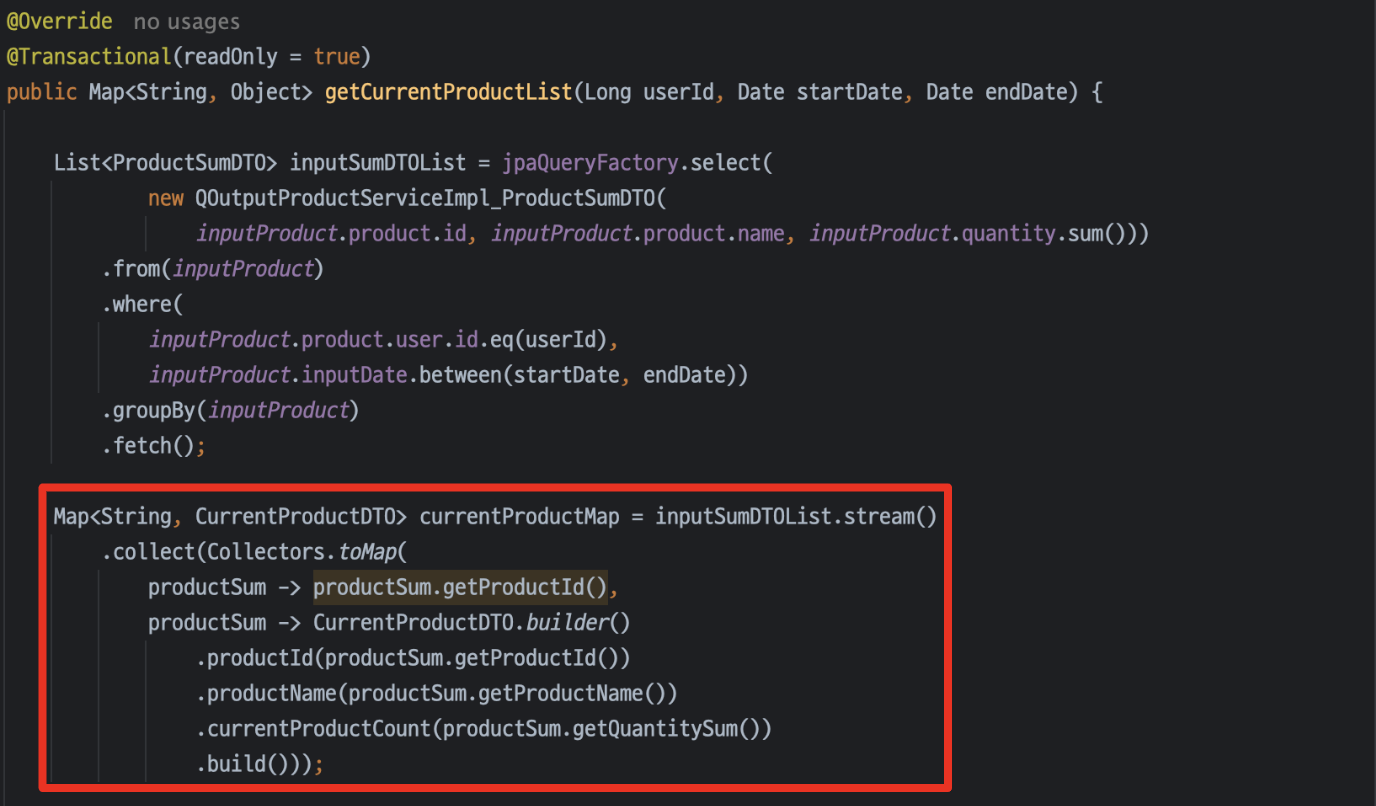
일단 첫째로, 조회한 inputProduct 결과물을 productId key DTO value로 하는 맵으로 만들어주었고,
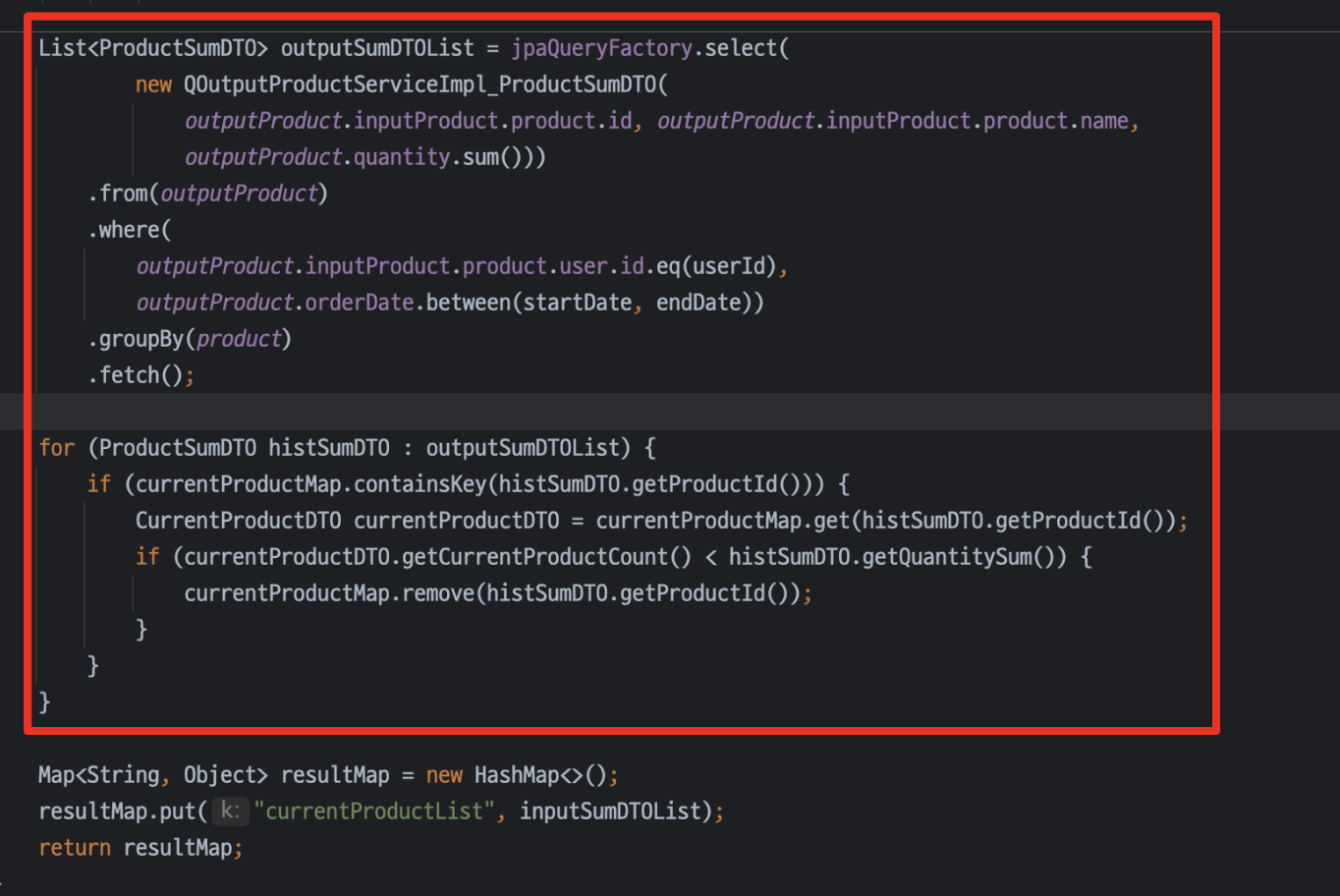
두번째로, 조회한 outputProduct 결과 DTO를 Key로 조회하고 있으면 차감해서 0보다 큰 것만 현재 Product 리스트에 추가하였다.
(ps. 실제 코드는 null 처리, 상태 값에 따른 처리, 단위 처리로 더 많은 중간에 코드가 추가되어있다...)
결과
AFTER에 Querydsl과 Index를 사용하고, 코드를 정리했을 때 아래와 같이 극적인 결과가 나왔다.
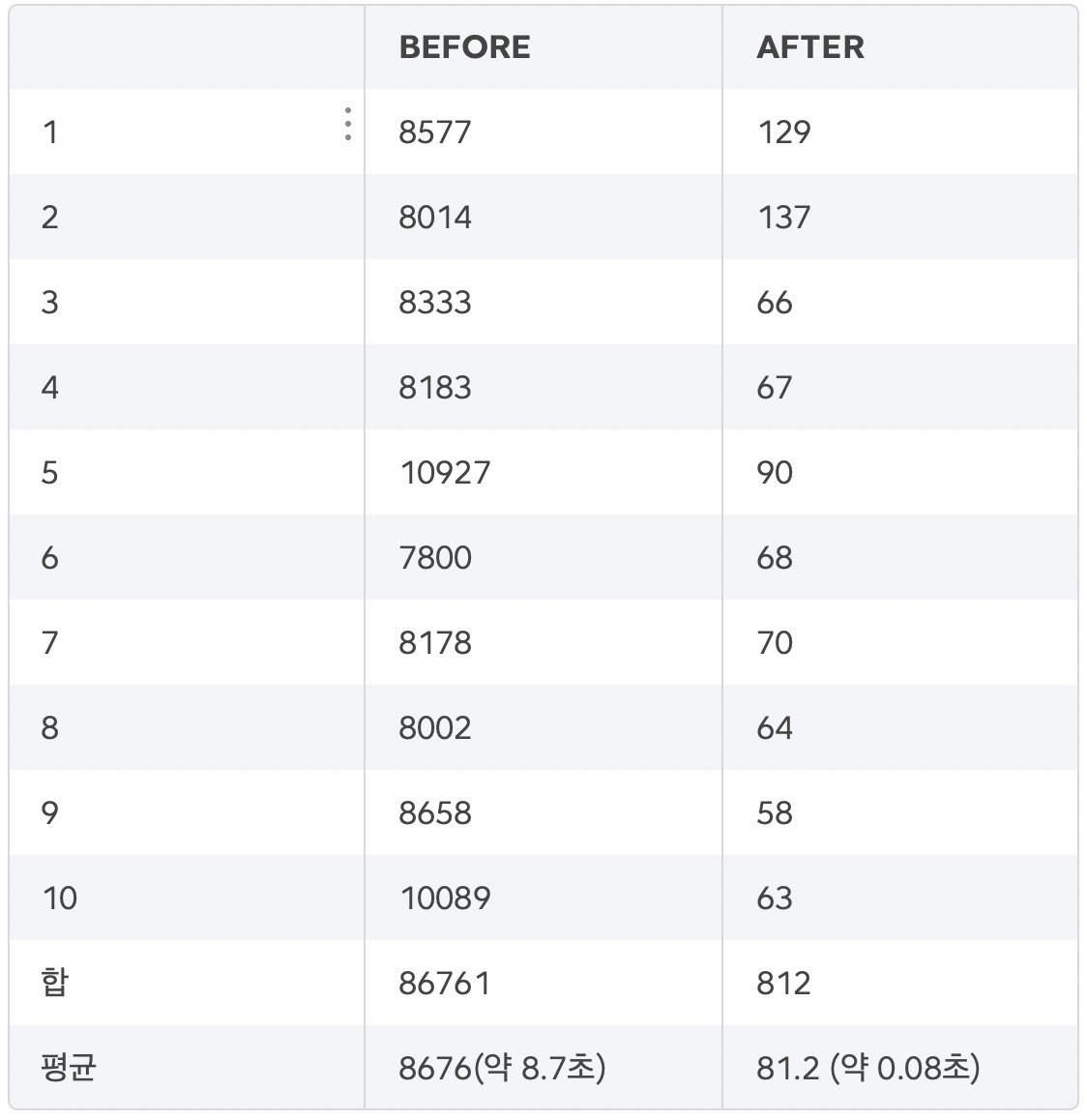
그래도 성능에 대한 고민을 했고, 공부도 좀 했다는게 좋았던 점이다. 여기에는 적지 않았지만 Querydsl의 DTO를 사용했을 때 오히려 속도가 느려졌던 경우도 있었고,
솔직히 성능 개선인지는 좀 의아하다. 코드를 통한 불러오는 방식의 시간복잡도를 변경한게 큰 역할을 했기 때문이다. 대부분의 문제는 올바른 코드에서 해결할 수 있다고 생각이 한편으로는 들었다.
그렇다고 이전 코드가 잘못 짰다고 생각하지는 않는다. 당시에는 현재의 상황을 예상하고 짜는게 쉽지는 않았기 때문이다.
오늘 내가 짠 코드가 내일의 레거시가 된다는 것을 다시 한번 느끼고 항상 겸손하고, 따로 리팩토링 기간을 잡지 않아도 현재 거쳐가는 코드의 리팩토링과 최적화에 대한 생각을 끊임없이 해야됨을 다시 한번 느낀다.

많이 배워갑니다