회사에서 선임 개발자가 SQL 조회조건을 LIKE '%문자열%'을 INDEX로 바꿔서 커밋한 내역을 확인했다. 속도 개선을 위해서라는데,,, 이해가 되지 않아 이에 대해 공부하고 기록을 남긴다
SQL에서 검색작업을 할 때 인덱스를 사용하는 경우와, 그렇지 않은 경우가 있는데 인덱스를 사용하면 데이터 검색이 훨씬 빨라지므로 조회 성능이 향상된다.
인덱스
인덱스란 무엇인가
인덱스는 데이터베이스 테이블의 특정 열 또는 열 집합에 대해 생성된 별도의 데이터 구조입니다. 인덱스는 검색 작업을 가속화하는 데 사용되며, 책의 색인과 비슷한 역할을 합니다. 예를 들어, 책의 색인을 통해 특정 단어가 나오는 페이지를 빠르게 찾을 수 있는 것처럼, 데이터베이스 인덱스를 사용하면 특정 값이 저장된 행을 빠르게 찾을 수 있습니다.
인덱스를 탄다는 의미
인덱스를 타는 것은 데이터베이스 엔진이 쿼리를 처리할 때 테이블의 모든 행을 하나씩 검사하지 않고, 인덱스를 사용하여 필요한 행을 빠르게 찾아내는 것을 의미합니다. 이를 통해 전체 테이블 스캔을 피하고 성능을 크게 향상시킬 수 있습니다.
인덱스를 사용하는 경우와 사용하지 않는 경우
- 인덱스를 사용하는 경우
- LIKE 'pattern%': 패턴이 접두사로 시작할 때
SELECT * FROM table WHERE column LIKE 'pattern%';- = 연산자 : 인덱스가 있는 열에 대해 값이 정확히 일치하는 행을 찾을 때
SELECT * FROM table WHERE column = 'value';- 범위 검색 : 인덱스가 있는 열에 대해 특정 범위 내의 값을 검색할 때
SELECT * FROM table WHERE column BETWEEN 10 AND 20;- 인덱스를 사용하지 않는 경우
- LIKE '%pattern' || LIKE '%pattern%' : 패턴이 접미사로 끝날 때
SELECT * FROM table WHERE column LIKE '%pattern';
SELECT * FROM table WHERE column LIKE '%pattern%';- 함수 사용
SELECT * FROM table WHERE LOWER(column) = 'value';B-tree, B+tree
왜 LIKE '%pattern%'은 인덱스를 안 탈까?
-> 요인은 INDEX의 자료구조가 B*tree이기 때문이다
- MySQL의 DB engine인 InnoDB는 B+tree로 이루어져있다
- 인덱스를 걸어주면 아래처럼 자료구조에 저장이 되는데 시작 값으로 데이터를 조회한다.
그렇기 때문에 포함되는 단어 혹은 끝나는 단어 같은 경우 기준을 잡을 수 없기 때문에 풀스캔으로 검색을 하게 된다
B-tree
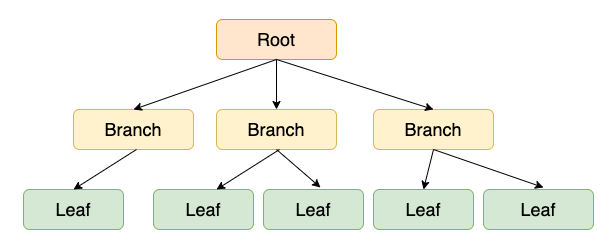
그림에 표시된 사각형으로 표시된 각각의 데이터를 '노드(Node)'라고 한다.
가장 상단의 노드를 '루트 노드(Root Node)', 중간 노드들을 '브랜치 노드(Branch Node)', 가장 아래 노드들을 '리프 노드(Leaf Node)'라고 한다.
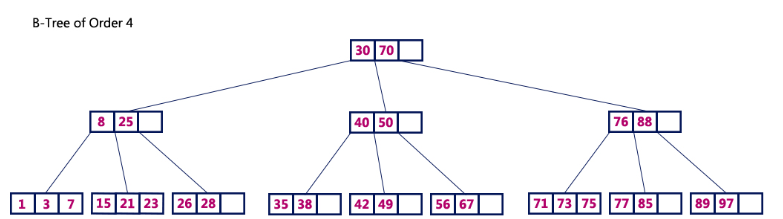
B-tree는 Binary search tree와 유사하지만, 한 노드 당 자식 노드가 2개 이상 가능하다. key 값을 이용해 찾고자 하는 데이터를 트리 구조를 이용해 찾는 것이다.
왜 B-tree는 빠른가
B-tree의 장점 한 가지는 '어떤 값에 대해서도 같은 시간에 같은 결과를 얻을 수 있다'인데 이를 '균일성'이라고 한다. 위의 예시에서 리프노드에 있는 '15'나 '28'을 찾는 시간은 동일할 것이다. (트리 높이가 다른 경우, 약간의 차이는 있겠지만 O(logN)이라는 시간 복잡도를 구할 수 있다)
B+tree
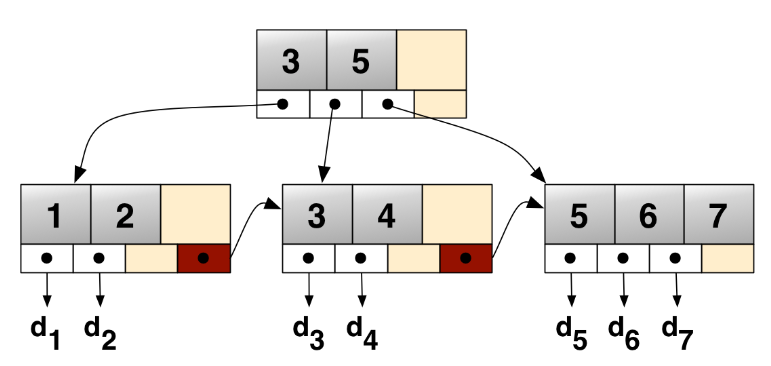
B+tree는 B-tree의 확장개념으로, B-tree의 경우, internal 또는 branch 노드에 key와 data를 담을 수 있다. 하지만, B+tree의 경우 브랜치 노드에 key만 담아두고, data는 담지 않는다. 오직 리프 노드에만 key와 data를 저장하고, 리프 노드끼리 Linked list로 연결되어 있다.
B+tree의 장점
-
리프 노드를 제외하고 데이터를 담아두지 않기 때문에 메모리를 더 확보함으로써 더 많은 key들을 수용할 수 있다. 하나의 노드에 더 많은 key들을 담을 수 있기에 트리의 높이는 더 낮아진다.(cache hit를 높일 수 있음)
-
풀 스캔 시, B+tree는 리프 노드에 데이터가 모두 있기 때문에 한 번의 선형탐색만 하면 되기 때문에 B-tree에 비해 빠르다. B-tree의 경우에는 모든 노드를 확인해야 한다.
B-tree VS B+tree
| 구분 | B-tree | B+tree |
|---|---|---|
| 데이터 저장 | 리프 노드, 브랜치 노드 모두 데이터 저장 가능 | 오직 리프 노드에만 데이터 저장 가능 |
| 트리의 높이 | 높음 | 낮음(한 노드 당 key를 많이 담을 수 있음) |
| 풀 스캔시 검색속도 | 모든 노드 탐색 | 리프 노드에서 선형 탐색 |
| 키 중복 | 없음 | 있음(리프 노드에 모든 데이터가 있기 때문) |
| 검색 | 자주 access되는 노드를 루트 노드 가까이 배치할 수 있고, 루트 노드에서 가까울 경우, 브랜치 노드에도 데이터가 존재하기 때문에 빠름 | 리프 노드까지 가야 데이터 존재 |
| LinkedList | 없음 | 리프 노드끼리 LinkedList로 연결 |
출처 : https://vprog1215.tistory.com/383, https://zorba91.tistory.com/293, chatGPT
