
MongoDB와 NoSQL 데이터베이스의 장점
MongoDB와 같은 NoSQL 데이터베이스가 빅데이터를 저장하고 처리하는 데 적합한 이유는 여러 가지 장점 덕분이다. 관계형 데이터베이스에 비해 NoSQL 데이터베이스는 다음과 같은 장점을 제공한다.
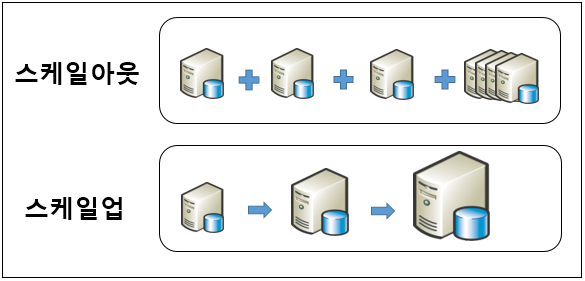
1. 스케일 아웃(Scale-Out) 지원
관계형 데이터베이스: 일반적으로 스케일 업(Scale-Up) 전략을 사용해 성능을 높인다. 더 강력한 하드웨어를 추가하는 방식으로 성능을 높이지만, 비용이 급격히 증가할 수 있다.
NoSQL 데이터베이스 (예: MongoDB): 스케일 아웃(Scale-Out) 전략을 사용하여 여러 서버에 데이터를 분산하여 저장할 수 있다. 클러스터에 노드를 추가하기만 하면 성능과 용량을 쉽게 확장할 수 있고, 비용도 비교적 적다.
스케일 업(Scale up)
스케일 업은 기존의 서버나 시스템에 더 강력한 하드웨어를 추가하거나 업그레이드하여 성능을 향상시키는 방법
- 하드웨어 업그레이드: 더 빠른 프로세서, 더 많은 RAM, 더 큰 저장장치 등으로 기존 서버의 성능을 향상시킨다.
- 단일 서버: 성능을 높이기 위해 단일 서버의 성능을 개선한다.
- 복잡성: 하드웨어 업그레이드가 복잡하거나 비용이 많이 들 수 있다.
- 한계: 하드웨어의 물리적 한계로 인해 성능 향상에 제한이 있을 수 있다.
스케일 아웃(Scale out)
여러 개의 서버나 노드를 추가하여 시스템의 성능을 확장하는 방법이다. 이 방법은 데이터나 작업을 여러 서버에 분산하여 처리
- 서버 추가: 성능을 향상시키기 위해 새로운 서버나 노드를 클러스터에 추가한다.
- 분산 처리: 작업이나 데이터가 여러 서버에 분산되어 처리된다.
- 유연성: 서버를 추가함으로써 성능을 수평적으로 확장할 수 있어 유연성이 높다.
- 비용: 일반적으로 스케일 업보다 비용이 적게 들고, 유지 관리가 더 쉬울 수 있다.
2. 유연한 스키마
관계형 데이터베이스: 엄격한 스키마를 요구한다. 데이터베이스를 설계할 때 테이블 구조를 미리 정의해야 하고, 데이터 형태가 바뀌면 스키마를 수정해야 한다. 스키마 변경은 복잡하고 시간이 걸릴 수 있다.
NoSQL 데이터베이스 (예: MongoDB): 스키마가 자유롭다. 문서 기반의 구조를 사용하여 데이터 형태를 유연하게 정의할 수 있다. 데이터 구조가 동적으로 변할 수 있고, 다양한 형식의 데이터를 함께 저장하고 쉽게 조정할 수 있다.
예시)
관계형 데이터베이스의 테이블 구조
CREATE TABLE Users (
UserID INT PRIMARY KEY,
UserName VARCHAR(100),
UserEmail VARCHAR(100)
);NoSql데이터베이스
{
"_id": "user123",
"name": "John Doe",
"email": "john.doe@example.com",
"orders": [
{
"order_id": "order456",
"amount": 100.00
}
]
}여기서 orders 필드는 배열로, 각 문서마다 다른 구조를 가질 수 있다. 같은 컬렉션 내에서 다양한 형식의 데이터를 저장할 수 있다.
3. 데이터 모델링의 유연성
관계형 데이터베이스: 테이블 간의 관계를 기반으로 데이터를 모델링한다. 복잡한 조인 연산이 필요할 수 있고, 대규모 데이터 집합에서 성능이 떨어질 수 있다.
NoSQL 데이터베이스 (예: MongoDB): 문서 지향 모델을 사용하여 데이터를 JSON과 유사한 형식으로 저장한다. 데이터의 중첩, 배열, 복잡한 구조를 쉽게 표현할 수 있으며, 조인 연산이 필요 없어 성능이 더 좋을 수 있다.
chatGpt에게 일반 데이터와 대용량 데이터의 C,R,U,D에서의 RDBMS와 NOSQL의 성능차이를 비교해줘라고 물어보았다.
일반 데이터에서의 성능 비교
관계형 데이터베이스 (RDBMS)
- Create: 데이터 삽입 작업은 일반적으로 빠르며, 인덱스와 제약조건이 있으면 성능에 영향을 줄 수 있다. 인덱스가 많은 경우, 인덱스 업데이트로 인해 성능 저하가 있을 수 있다.
- Read: 읽기 작업은 효율적이다. 인덱스를 잘 설정하면 복잡한 쿼리와 조인 연산도 빠르게 처리할 수 있다. 트랜잭션 관리와 ACID 속성을 보장하기 때문에 데이터의 일관성 유지에 유리하다.
- Update: 업데이트 작업도 효율적이다. 그러나 인덱스가 있는 경우 인덱스 업데이트가 필요하고, 이로 인해 성능이 영향을 받을 수 있다. 데이터의 무결성을 보장하기 위한 제약 조건을 고려해야 한다.
- Delete: 삭제 작업은 일반적으로 빠르지만, 외래 키 제약 조건이나 트리거가 있는 경우 성능에 영향을 줄 수 있다. 대량의 데이터를 삭제할 때는 성능이 저하될 수 있다.
NoSQL 데이터베이스
-Create: 데이터 삽입 작업은 빠르며, 스키마가 없거나 유연하므로 데이터 구조 변경이 용이하다. 그러나 데이터를 문서 형태로 저장하므로 데이터가 중첩될 경우 삽입 성능이 영향을 받을 수 있다.- Read: 읽기 작업은 매우 빠르며, 데이터가 중첩된 형태로 저장되어 있어 복잡한 쿼리에서 성능이 저하될 수 있다. 하지만, 데이터를 문서로 저장하기 때문에 단순 조회에는 뛰어난 성능을 발휘한다.
- Update: 업데이트 작업은 빠르며, 데이터의 특정 부분만 수정할 수 있다. 하지만, 데이터의 중첩 구조와 복잡성에 따라 성능이 영향을 받을 수 있다. 전체 문서 업데이트 시에는 성능이 저하될 수 있다.
- Delete: 삭제 작업은 효율적이며, 데이터가 문서 형태로 저장되므로 문서 전체를 삭제하는 경우 빠르게 처리할 수 있다. 대량의 데이터 삭제 시 성능 저하가 발생할 수 있지만, 이를 효율적으로 처리하는 방법이 있다.
대용량 데이터에서의 성능 비교
관계형 데이터베이스 (RDBMS)
- Create: 대용량 데이터 삽입 시 성능이 저하될 수 있다. 인덱스와 제약 조건이 있는 경우 데이터 삽입 속도가 느려질 수 있으며, 트랜잭션 로그가 커져 성능이 영향을 받을 수 있다.
- Read: 대량의 데이터를 읽는 작업은 인덱스와 쿼리 최적화 덕분에 상대적으로 효율적일 수 있다. 그러나 대규모 조인 연산이나 복잡한 쿼리에서는 성능이 저하될 수 있다.
- Update: 대용량 데이터 업데이트는 성능 저하를 일으킬 수 있다. 인덱스와 제약 조건으로 인해 업데이트 성능이 영향을 받을 수 있으며, 트랜잭션 처리가 복잡할 수 있다.
- Delete: 대량의 데이터 삭제는 성능 저하를 유발할 수 있다. 특히, 외래 키 제약 조건이나 트리거가 있을 경우 삭제 성능이 떨어질 수 있으며, 데이터 무결성을 유지하기 위한 추가 작업이 필요하다.
NoSQL 데이터베이스- Create: 대용량 데이터 삽입은 빠르고 효율적이다. 스키마가 없거나 유연하므로 데이터 삽입이 용이하며, 데이터가 문서 형태로 저장되어 성능에 큰 영향을 주지 않는다.
- Read: 대량의 데이터를 읽는 작업은 성능이 뛰어나다. 데이터가 분산 저장될 수 있어 대규모 데이터셋에서도 빠른 읽기 성능을 유지할 수 있다. 그러나, 복잡한 쿼리에는 비효율적일 수 있다.
- Update: 대량 데이터 업데이트 시 성능이 좋다. 부분적인 문서 업데이트가 가능하며, 데이터의 중첩 구조로 인해 일부 데이터만 수정할 수 있어 효율적이다.
- Delete: 대량 데이터 삭제는 효율적이며, 전체 문서 삭제가 빠르게 처리된다. 분산 저장된 데이터를 효율적으로 삭제할 수 있으며, 대량 삭제 시 성능이 우수하다.
요약
일반 데이터:
- RDBMS: 복잡한 쿼리와 조인 연산에서 뛰어난 성능을 보인다. 데이터의 무결성을 보장하며, ACID 속성을 지원한다.
- NoSQL: 데이터의 삽입과 읽기에서 매우 빠르며, 데이터 모델이 유연하다. 중첩된 데이터와 배열을 효율적으로 처리할 수 있다.
대용량 데이터:- RDBMS: 대용량 데이터 삽입과 업데이트에서 성능 저하가 발생할 수 있으며, 인덱스와 제약 조건이 성능에 영향을 미친다. 복잡한 쿼리 처리에는 강점을 보인다.
- NoSQL: 대량 데이터 삽입과 읽기, 삭제에서 성능이 뛰어나며, 데이터 모델의 유연성 덕분에 효율적으로 처리할 수 있다. 단, 복잡한 쿼리에는 성능이 저하될 수 있다.
결론적으로, RDBMS는 데이터의 무결성과 복잡한 쿼리 처리에 강점을 보이며, NoSQL 데이터베이스는 대량 데이터의 삽입, 읽기, 업데이트, 삭제에서 뛰어난 성능을 보인다. 데이터의 특성과 요구 사항에 따라 적절한 데이터베이스를 선택하는 것이 중요하다.
4. 데이터 접근 속도
관계형 데이터베이스: 복잡한 쿼리와 조인 연산을 처리할 때 성능이 떨어질 수 있다. 특히 데이터 양이 많고 복잡한 쿼리가 필요할 때 성능이 저하될 수 있다.
NoSQL 데이터베이스 (예: MongoDB): 데이터를 문서 단위로 저장하고 인덱싱하여 빠르게 액세스할 수 있다. 쿼리 성능이 뛰어나며, 데이터베이스 설계에 따라 읽기와 쓰기 성능을 최적화할 수 있다.
5. 데이터 저장과 처리 방식
관계형 데이터베이스: 데이터를 정규화해서 저장한다. 중복을 줄이고 일관성을 유지하지만, 정규화로 인해 복잡한 조인 연산이 필요할 수 있다.
NoSQL 데이터베이스 (예: MongoDB): 데이터를 비정규화해서 저장할 수 있다. 데이터를 중복해서 저장할 수 있지만, 읽기와 쓰기 성능을 높일 수 있다. 비정규화된 데이터 저장 방식이 대규모 데이터와 빈번한 읽기 작업에 적합할 수 있다.
6. 고가용성과 내구성
관계형 데이터베이스: 데이터베이스의 고가용성 및 내구성을 보장하기 위해 복잡한 복제 및 백업 메커니즘을 필요로 한다.
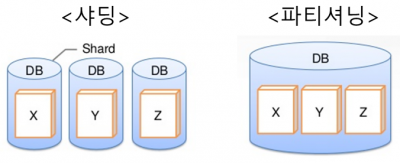
NoSQL 데이터베이스 (예: MongoDB): 내장된 복제 및 샤딩(Sharding) 기능을 통해 데이터의 고가용성과 내구성을 쉽게 구현할 수 있다. MongoDB는 자동으로 데이터를 여러 노드에 복제하고, 분산 환경에서 데이터를 샤딩하여 확장성을 높인다.
7. 애플리케이션의 요구사항
관계형 데이터베이스: 데이터의 무결성을 중요시하고, 복잡한 트랜잭션과 강력한 데이터 일관성을 제공한다.
NoSQL 데이터베이스 (예: MongoDB): 데이터의 유연성, 확장성, 성능을 중요시한다. 강력한 일관성보다는 성능과 확장성을 중시하는 경우에 더 적합하다.
예시: MongoDB의 문서 모델
MongoDB는 데이터를 BSON(Binary JSON) 형식으로 저장한다. 예를 들어, 사용자 데이터를 저장하는 문서는 다음과 같은 형태를 가질 수 있다:
{
"_id": "user123",
"name": "John Doe",
"email": "john.doe@example.com",
"orders": [
{
"order_id": "order456",
"amount": 100.00
},
{
"order_id": "order789",
"amount": 150.00
}
]
}이 문서는 사용자와 관련된 모든 정보를 하나의 문서에 포함시킬 수 있어, 관계형 데이터베이스에서 필요한 조인 연산 없이 데이터를 쉽게 읽고 쓸 수 있다.
요약
MongoDB와 같은 NoSQL 데이터베이스는 빅데이터 처리에 여러 장점을 제공한다. 유연한 스키마, 스케일 아웃 지원, 빠른 데이터 접근, 데이터 모델링의 유연성 등이 주요 장점이다. 이러한 특성은 대규모 데이터 환경에서 성능과 확장성을 극대화하는 데 도움을 준다. 반면, 관계형 데이터베이스는 강력한 데이터 무결성 및 트랜잭션 관리가 필요한 경우에 적합하다. 데이터베이스 선택은 애플리케이션의 요구 사항과 데이터 처리 특성에 따라 달라질 수 있다.
