다양한 인덱스 유형
MySql기준으로 인덱스 유형은 다음과 같다
1. B-Tree인덱스
가장 일반적으로 사용되는 인덱스 유형으로, 검색 및 정렬 작업에 효과적입니다. B-Tree 인덱스는 데이터를 정렬된 트리 구조로 저장하여 빠른 검색을 가능하게 합니다.
예시) : users 테이블에서 username 열에 B-Tree 인덱스를 추가하여 사용자가 입력한 username으로 빠르게 검색할 수 있습니다.
CREATE TABLE users (
id INT AUTO_INCREMENT PRIMARY KEY,
username VARCHAR(50)
);
CREATE INDEX idx_username ON users (username);
2. 해시 인덱스
해시 함수를 사용하여 데이터를 해시 테이블에 저장하는 인덱스입니다. 해시 인덱스는 정확한 일치 검색에 최적화되어 있으며, 주로 등호 연산(=)에 사용됩니다. 그러나 범위 검색이나 정렬에는 적합하지 않을 수 있습니다.
예시) : sessions 테이블에서 세션 ID에 대해 해시 인덱스를 사용하여 빠르게 검색할 수 있습니다.
CREATE TABLE sessions (
session_id CHAR(32) PRIMARY KEY,
data TEXT
) ENGINE=MEMORY;
CREATE INDEX idx_session_id ON sessions (session_id) USING HASH;3. 전문 텍스트 인덱스
텍스트 기반의 데이터를 검색하는 데 특화된 인덱스입니다. 전문 텍스트 인덱스는 텍스트의 단어나 구를 색인화하여 효율적인 텍스트 검색을 제공합니다. 전문 텍스트 인덱스는 MATCH AGAINST 문을 사용하여 텍스트 검색에 사용됩니다.
예시) :articles 테이블에서 content 열에 전체 텍스트 인덱스를 추가하여 문서 내용을 검색할 수 있습니다. 이 인덱스는 content 열의 단어를 검색하는 데 유용하며, MATCH와 AGAINST 연산자를 사용하여 전체 텍스트 검색을 수행할 수 있습니다.
CREATE TABLE articles (
id INT AUTO_INCREMENT PRIMARY KEY,
title VARCHAR(100),
content TEXT
);
CREATE FULLTEXT INDEX idx_content ON articles (content);
SELECT * FROM articles
WHERE MATCH(content) AGAINST('search term');4. 공간 인덱스
공간 데이터를 처리하는 데 사용되는 인덱스입니다. 공간 인덱스는 좌표 값에 대한 효율적인 검색을 가능하게 합니다. 공간 인덱스는 GIS(Geographic Information System) 데이터베이스에서 사용될 수 있으며, 공간 데이터 타입(Geometry, Point, Polygon 등)을 지원하는 컬럼에 대해 공간 인덱스를 생성할 수 있습니다. 이를 통해 공간 데이터의 거리 계산이나 영역 검색과 같은 공간 연산을 효율적으로 수행할 수 있습니다.
예시) : locations 테이블에서 위치 정보를 저장하고 공간 인덱스를 추가하여 특정 위치 범위를 검색할 수 있습니다. 이 예제에서 SPATIAL INDEX는 공간 데이터의 검색 성능을 향상시킵니다._
CREATE TABLE locations (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(100),
location POINT,
SPATIAL INDEX (location)
);
-- 위치 정보 삽입
INSERT INTO locations (name, location) VALUES ('Place A', POINT(1, 2));
INSERT INTO locations (name, location) VALUES ('Place B', POINT(3, 4));
-- 특정 범위 내의 위치 검색
SELECT * FROM locations
WHERE ST_Distance_Sphere(location, POINT(2, 3)) < 5000;5. 전체 텍스트 인덱스
전체 텍스트 데이터에서 단어 기반의 검색을 지원하는 인덱스입니다. 전체 텍스트 인덱스는 일반 텍스트 데이터에서 단어를 추출하여 인덱싱하고, 단어 기반의 검색 쿼리를 수행할 때 사용됩니다. 전체 텍스트 인덱스는 MATCH 문이나 CONTAINS 문을 사용하여 검색할 수 있습니다.
예시) : reviews 테이블에서 리뷰 텍스트에 대한 전체 텍스트 인덱스를 추가하여 특정 단어를 포함하는 리뷰를 검색할 수 있습니다._
CREATE TABLE reviews (
id INT AUTO_INCREMENT PRIMARY KEY,
product_id INT,
review TEXT,
FULLTEXT (review)
);
-- 리뷰에서 특정 단어 검색
SELECT * FROM reviews
WHERE MATCH(review) AGAINST('excellent');인덱스 생성 및 선택
사용자가 명시적으로 인덱스 유형을 지정할 수 있음:
- 사용자 또는 개발자가 인덱스를 생성할 때, 특정 인덱스 유형을 명시적으로 지정할 수 있습니다. 예를 들어, USING HASH를 사용하여 해시 인덱스를 생성하거나 FULLTEXT를 사용하여 전문 텍스트 인덱스를 생성합니다.
- DBMS의 자동 선택:
- MySQL의 DBMS는 사용자가 명시적으로 인덱스 유형을 지정하지 않은 경우, 기본적으로 B-Tree 인덱스를 생성합니다. 이는 MySQL의 기본 인덱스 구조입니다.
- 특정 스토리지 엔진에서는 인덱스 유형이 고정되어 있거나 제한될 수 있습니다. 예를 들어, MEMORY 엔진에서는 해시 인덱스만 사용되며, InnoDB에서는 B-Tree 인덱스를 기본적으로 사용합니다.
요약
- B-Tree 인덱스: 기본 인덱스 유형으로, MySQL에서 기본적으로 사용됩니다.
- 해시 인덱스: MEMORY 엔진에서 사용되며, 정확한 일치 검색에 적합합니다.
- 전문 텍스트 인덱스: 긴 텍스트의 단어 검색을 위해 사용됩니다.
- 공간 인덱스: 공간 데이터를 위한 인덱스입니다.
인덱스 설계 원칙
1. 적절한 컬럼 선택
- 인덱스를 생성할 필드 선택 기준
검색 빈도: 자주 검색되는 필드일수록 인덱스를 생성하는 것이 좋습니다.
카디널리티(Cardinality): 해당 필드의 고유한 값의 수가 많을수록 인덱스의 효과가 큽니다.
필터링과 정렬: WHERE 절에서 필터링이나 ORDER BY 절에서 정렬에 사용되는 필드는 인덱스를 생성하는 것이 유리합니다.
2. 중복 인덱스 피하기
- 중복 인덱스로 인한 오버헤드 방지 방법
중복 인덱스는 같은 필드나 필드의 조합에 대해 중복해서 생성되는 인덱스를 말합니다. 중복 인덱스는 저장 공간을 낭비하고 업데이트 성능을 저하시킬 수 있으므로 피해야 합니다.
중복 인덱스를 피하기 위해서는 중복되는 인덱스를 삭제하고, 필요한 경우에만 새로운 인덱스를 생성하여 오버헤드를 방지할 수 있습니다.
3. 인덱스 칼럼의 정렬 순서
B-Tree 인덱스의 정렬 방식 이해
mysql에서 사용하는 B-Tree 인덱스는 칼럼의 값을 변형하지 않고, 원래의 값을 이용해 인덱싱하는 알고리즘입니다.
정렬 순서가 일치하는 경우에만 인덱스를 사용하여 정렬이 이루어지므로, 쿼리에서 자주 사용되는 정렬 순서에 맞게 인덱스를 생성하는 것이 좋습니다.
예를 들어, last_name과 first_name 두 개의 칼럼을 가진 테이블이 있을 때, last_name을 오름차순으로 정렬하고 first_name을 내림차순으로 정렬하여 인덱스를 생성하려면 다음과 같이 작성할 수 있습니다:
CREATE INDEX idx_name ON table_name (last_name ASC, first_name DESC);위 예제에서는 table_name 테이블에서 last_name 칼럼을 오름차순으로, first_name 칼럼을 내림차순으로 정렬하는 복합 인덱스를 생성하는 것을 보여줍니다.
인덱스 칼럼의 정렬 순서를 적절하게 선택하면 쿼리의 성능을 향상시킬 수 있습니다. 쿼리에서 자주 사용되는 정렬 방식에 맞게 인덱스를 설계하면 데이터베이스의 응답 시간을 최적화할 수 있습니다.
B-Tree 는 최상위에 하나의 루트 노드가 존재하고 그 하위에 자식 노드가 붙어있는 형태입니다.
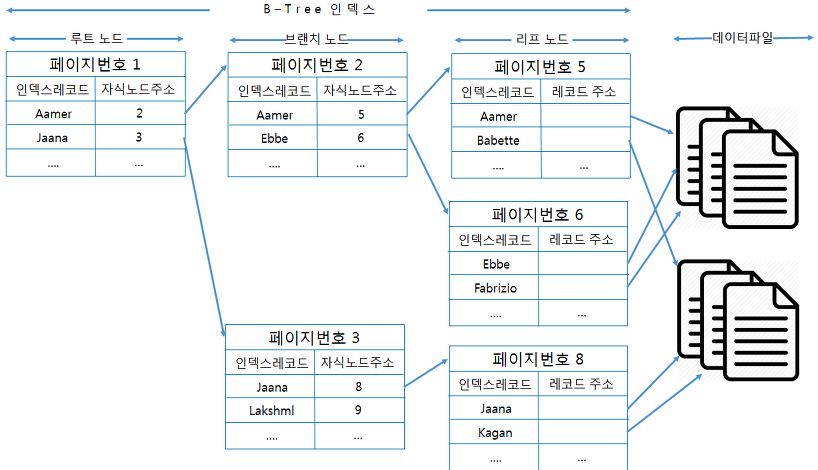
트리 구조의 가장 하위에는 리프 노드라고 하고 트리구조에서 루트노드도 아니고 리프노드도 아닌 중간의 노드를 브랜치 노드라고 합니다.
이 인덱스의 최대 장점은 어떤 데이터를 조회하든지, 이에 사용하는 조회 과정의 길이 및 비용이 균등 합니다.
단, 어떤 데이터를 조회 하든지 Root 에서 부터 Leaf 페이지를 모두 거처야 하기 때문에 데이터가 적은 테이블등의 단순 조회로 데이터를 조회하는 과정이 대비 조회 속도가 느린 단점이 있습니다.
4. 금지해야할 인덱스 설계
- 대용량 데이터가 자주 입력되는 경우
클러스터형 인덱스의 경우 빈번한 페이징이 일어나기 때문에 부하가 생깁니다.
따라서 인덱스가 필요한 경우 primary(클러스터) 대신 unique만 설정하는 게 좋을 수 있습니다.
클러스터형 인덱스의 동작 방식 :
- 클러스터형 인덱스는 데이터가 인덱스 순서에 따라 물리적으로 저장됩니다. 예를 들어, 기본 키가 클러스터형 인덱스인 경우, 데이터는 기본 키 값의 순서에 따라 정렬됩니다.
- 클러스터형 인덱스에서는 데이터가 물리적으로 정렬되어 있기 때문에, 페이징 쿼리를 처리할 때 인덱스를 순회하며 범위 검색을 수행합니다.
- 페이징이 자주 발생할 경우, 데이터의 물리적 순서를 유지해야 하기 때문에, 삽입, 삭제, 업데이트 작업이 빈번히 일어나면 인덱스와 데이터의 정렬을 유지하는 데 추가 비용이 발생합니다. 이는 데이터베이스의 성능 저하를 초래할 수 있습니다.
- 데이터 중복도가 높은 열은 인덱스 효과가 없음.
예를 들어 성별 열에 M, F만 있다고 하면 인덱스를 안쓰는 게 낫습니다.
따라서 일반 보조 인덱스보다 unique 보조 인덱스가 빠른 이유가 이것입니다.
- 자주 사용되지 않으면 성능 저하를 초래할 수 있음.
INSERT만 빈번한 시스템이라면, 사용해보지도 못하고 데이터 입력에 걸리는 작업량만 많아질 수 있습니다.
5. 인덱스를 사용할 때 주의할 점
데이터 변경(삽입, 수정, 삭제) 작업이 얼마나 자주 일어나는지 고려해야합니다.
단일 테이블에 인덱스가 많으면 속도가 느려질 수 있습니다. (테이블당 4~5개 권장)
검색할 데이터가 전체 데이터의 20% 이상이라면, MySQL에서 인덱스를 사용하지 않습니다. (강제로 사용할 시 성능 저하를 초래할 수 있음)
전체 페이지의 대부분을 읽어야 하고, 인덱스 관련 페이지도 읽어야 해서 작업량이 크기 때문입니다.
사용하지 않는 인덱스는 제거하는 것이 바람직함. (실무에서 사용하지 않는 보조 인덱스를 몇개 삭제했을 때 성능이 향상되는 경우도 많음)
클러스터형 인덱스는 테이블당 하나만 생성할 수 있습니다.
테이블에 클러스터형 인덱스가 아예 없는 것이 좋은 경우도 있음
6. Table에 있는 Index 확인 명령
SHOW INDEX
FROM 테이블이름7. Create Index
-- 따로 인덱스 생성
CREATE INDEX 인덱스명 ON 테이블명 (컬럼명); -- 보조 인덱스 생성 (중복 허용)
CREATE UNIQUE INDEX 인덱스명 ON 테이블명 (컬럼명); -- 보조 인덱스 생성 (중복 비허용)
CREATE FULLTEXT INDEX 인덱스명 ON 테이블명 (컬럼명); -- 클러스터 인덱스 생성
CREATE UNIQUE INDEX 인덱스명 ON 테이블명 (컬럼명1, 컬러명2); -- 다중 컬럼 인덱스 생성
ANALYZE TABLE 테이블명; -- !! 생성한 인덱스 적용 !!8. Delete Index
ALTER TABLE 테이블이름
DROP INDEX 인덱스이름출처 : 인덱스 최적화와 효율적인 활용 방법
