Attention
Attention은 LSTM과 GRU에서 장기 의존성 문제를 개선했지만, 문장이 길어지면 모든 단어의 정보를 고정 길이의 hidden state 벡터에 담기 어렵다는 문제를 갖고 있다. 이러한 문제를 해결하기 위해 고안된 방법이 바로 Attention이다.
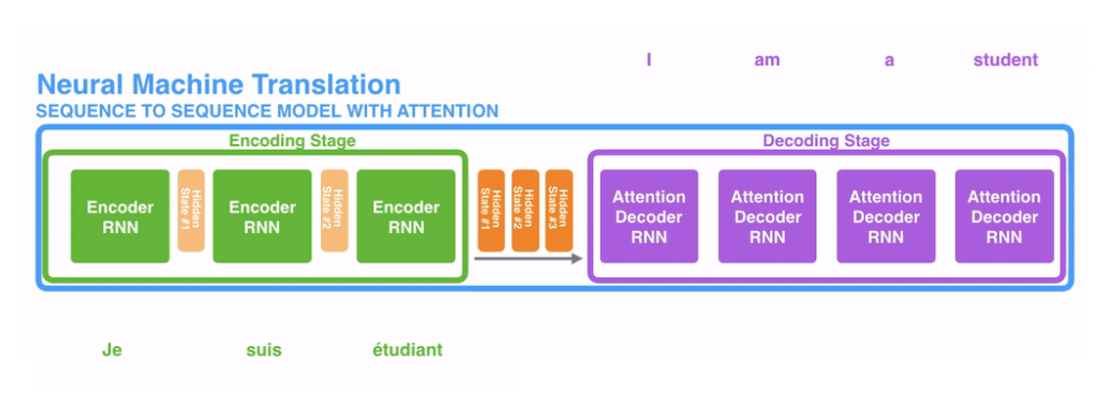
이 링크에서 위의 사진을 영상으로 볼 수 있다. 또한, Attention을 쓰지 않았을 때에는 어떤 단계를 거치는지에 대한 영상도 있어서 Attention을 사용했을 때와 사용하지 않았을 때를 쉽게 이해할 수 있어서 좋다.
Attention은 N개의 단어가 입력되면 N개의 hidden state 벡터를 모두 간직하고 생성된 hidden state 벡터를 모두 디코더에 넘겨준다. 만약 3개의 단어가 입력되었다면 3개의 hidden state 벡터를 생성한다.
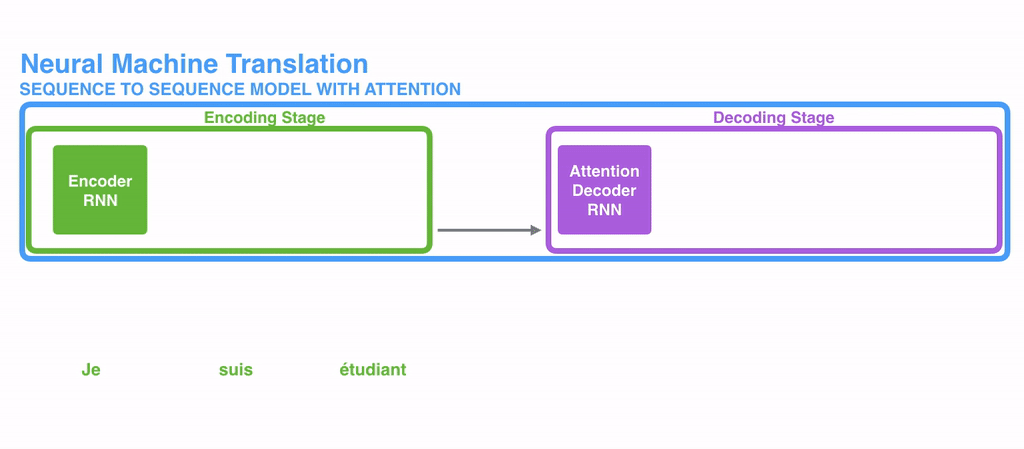
Encoder와 Decoder
Seq2Seq with attention은 Encoder-Decoder 구조로 이루어져 있다. Seq2Se2 (Sequence-to-Sequence)모델은 한 문장(시퀀스)을 다른 문장으로 변환하는 모델을 의미한다. Seq2Seq를 Encoder-Decoder 모델이라고도 하는데 이는 Seq2Seq 모델이 인코더와 디코더로 구성되어 있기 때문이다.
문자 그대로 인코더는 입력된 데이터를 인코딩(부호화)하고, 디코더는 인코딩 된 데이터를 디코딩(복호화)한다. 그러니까 인코더는 입력을 처리하고 디코더는 결과를 생성하는 것이다.
Decoder에서 동작하는 법
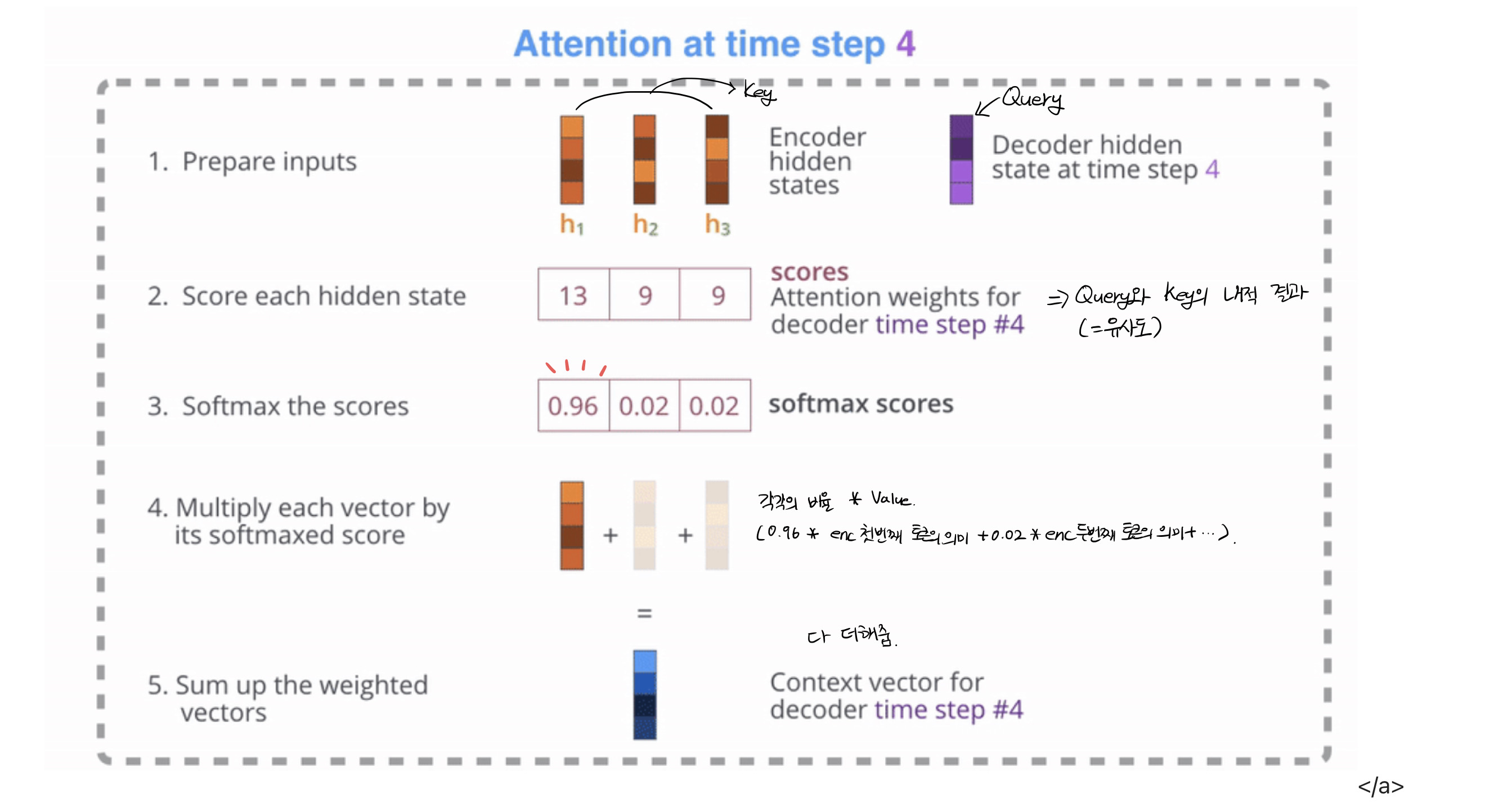
위의 사진은 디코더에서 한 단어에 대한 가중치가 구해지는 과정이다. 이를 위해서 필요한 준비물이 3개가 있는데 바로 Query, Key, Value이다.
Query는 질문으로 디코더의 해당 time step의 hidden state vector를 뜻한다. 쉽게 예를 들자면 "여기 나랑 비슷한 애 누구야?" 하는 질문이라고 할 수 있다.
Key는 인코더에서 넘겨준 각각의 hidden state를 비교할 단어들로 질문에 대한 답을 찾을 수 있는 애라고 생각하면 쉽고, Value는 Key에 대한 값이라고 생각하면 된다.
Query와 Key, Value가 준비됐다면 각각의 벡터를 내적한 값을 구한 뒤 이 값에 softmax 함수를 취해준다. softmax를 취해 나온 값에 Value에 해당하는 인코더에서 넘어온 hidden state 벡터를 곱해준다.
그리고 이 벡터를 모두 더해주면 최종적으로 생성된 벡터와 디코더의 hidden state 벡터를 사용해서 출력 단어가 결정되는 것이다.
이처럼 Attention을 활용하면 디코더가 인코더에 입력되는 모든 단어의 정보를 활용할 수 있기 때문에 장기 의존성 문제(입력과 출력 사이의 거리가 멀어질수록 연관 관계가 적어지는 문제로 먼 과거 시점의 정보를 잘 반영하지 못하는 문제)를 해결할 수 있다.
