HTML
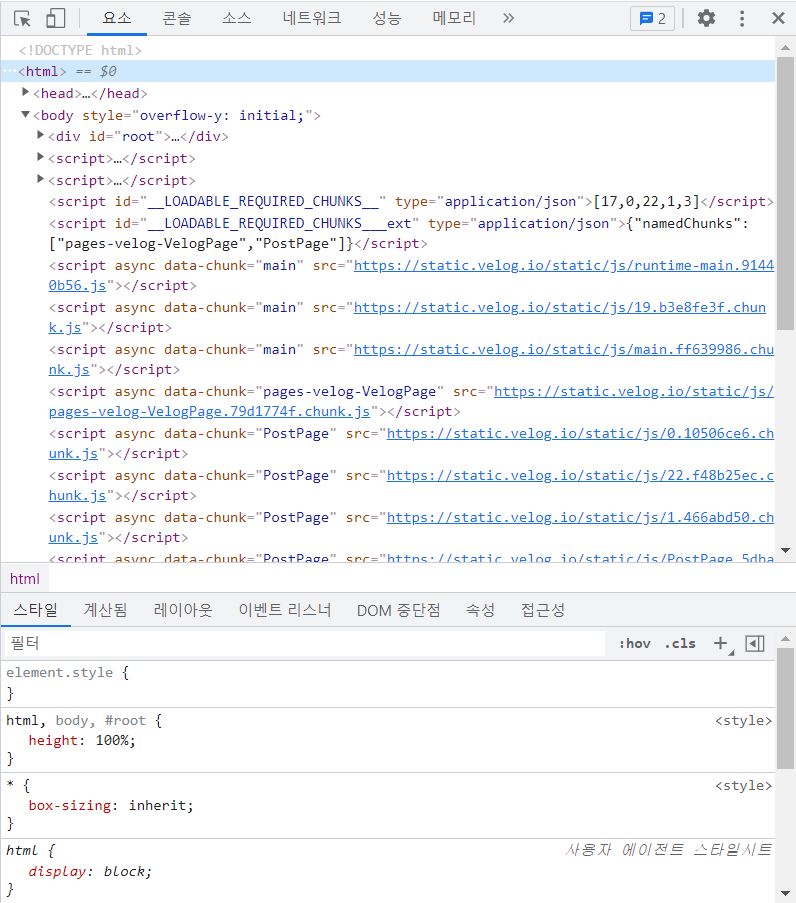
HTML은 Hyper Text Markup Language의 약어로 프로그래밍 언어가 아닌 마크업 언어이다. 웹상에 표시하고 싶은 내용을 HTML 문서로 작성하면 컴퓨터가 웹 브라우저를 통해 HTML 문서를 읽고 표현해 우리가 시각적으로 볼 수 있게 되는 것이다. ''F12'' 혹은 ''Ctrl + Shift + C '' 를 누르면 개발자 도구를 불러올 수 있는데 그 중 Elements 탭을 확인하면 아래 사진과 같이 HTML의 구조를 쉽게 확인할 수 있다.
CSS
CSS는 Cascading Style Sheet의 약어로 쉽게 말해서 작성한 HTML 문서를 꾸며주는 역할을 한다.
BeautifulSoup
BeautifulSoup은 파이썬 라이브러리 중 하나로 웹 스크래핑을 할 때 사용한다. requests를 통해서 불러오게 된 웹 페이지는 하나의 string으로 인식하게 되는게 BeautifulSoup을 통해서 html 문서로 파싱할 수 있다.
import requests
from bs4 import BeautifulSoup
page = requests.get(URL)
soup = BeautifulSoup(page.content, 'html.parser')find 혹은 find_all을 통해서 내가 찾고자 하는 html 요소를 찾을 수도 있다. find는 처음 발견한 하나의 요소만 가져오고, find_all은 발견한 모든 요소를 가지고 온다.
find_one_div = soup.find('div')
find_all_divs = soup.find_all('divs')추가적으로 find와 find_all이 아닌 select_one과 select로 사용할 수도 있다. find가 아닌 select를 사용하게 되면, 요소 안에 있는 요소를 찾을 때도 보다 쉽게 사용할 수 있다.
select_one_div = soup.select_one('div')
select_all_divs = soup.select('div')
p_inside_div = soup.select_on('div > p')
우당탕탕 코린이